本篇内容来自论文:《Is Space-Time Attention All You Need for Video Understanding?》,在编辑过程中增加了一些自己的理解,难免理解不周或者书写有错,欢迎在评论区指出,谢谢!
TimeSformer 能做什么?
近日,Facebook AI提出了一种称为 TimeSformer(Time-Space transformer) 的视频理解新架构,这个结构完全基于 Transformer。自 Transformer 提出以来,在 NLP 领域得到了非常广泛的使用,是机器翻译以及语言理解中最常用的方法。
TimeSformer 在多个有挑战的行为识别数据集上达到了 SOTA 的结果,论文中使用的数据集包括 Kinetics-400,Kinetics-600、Something-Something-v2 、Diving-48 和 HowTo100M 数据集。相比于现代的 3D 卷积神经网络,TimeSformer训练要快3倍,推理的时间为它的十分之一。
除此之外,TimeSformer 的可扩展性,使得可以在更长的视频片段上训练更大的模型,当前的 3D CNN 最多只能够处理几秒钟的片段,使用 TimeSformer ,甚至可以在数分钟的片段上进行训练。它为将来的 AI 系统理解更复杂的人类行为铺好了路。
相比于卷积,Transformer 有什么区别,又好在哪里?
传统的视频分类模型使用 3D 卷积核来提取特征,而 TimeSformer 基于 Transformer 中的自注意力机制,使得它能够捕捉到整段视频中的时空依赖性。这个模型将输入的视频看做是从各个帧中提取的图像块(patch)的时空序列,以将 Transformer 应用于视频。这个使用的方式与 NLP 中的用法非常相似。NLP Transformer 是通过将每个词与句子中的所有词进行比较,来推断每个词的含义,这种方法叫做自注意力机制。该模型通过将每个图像块的语义与视频中的其它图像块进行比较,来获取每个图像块的语义,从而可以同时捕获到邻近的图像块之间的局部依赖关系,以及远距离图像块的全局依赖性。
众所周知,Transformer 的训练非常消耗资源,为了缓解这一问题,TimeSformer 通过两个方式来减少计算量:
- 将视频拆解为不相交的图像块序列的子集;
- 使用一种独特的自注意力方式,来避免所有的图像块序列之间进行复杂计算。文中把这项技术叫做 分开的时空注意力机制(divided space-time attention)。在时间 attention 中,每个图像块仅和其余帧在对应位置提取出的图像块进行 attention。在空间 attention 中,这个图像块仅和同一帧的提取出的图像块进行 attention。作者还发现,分开的时空注意力机制,效果要好于共同使用的时空注意力机制。
在CV领域,卷积和 Transformer 相比,有以下的缺陷:
- 卷积有很强的归纳偏见(例如局部连接性和平移不变性),虽然对于一些比较小的训练集来说,这毫无疑问是有效的,但是当我们有了非常充足的数据集时,这些会限制模型的表达能力。与 CNN 相比,Transformer 的归纳偏见更少,这使得他们能够表达的范围更广,从而更加适用于非常大的数据集。
- 卷积核是专门设计用来捕捉局部的时空信息,它们不能够对感受野之外的依赖性进行建模。虽然将卷积进行堆叠,加深网络会扩大感受野,但是这些策略通过聚集很短范围内的信息的方式,仍然会限制长期以来的建模。与之相反,自注意力机制通过直接比较在所有时空位置上的特征,可以被用来捕捉局部和全局的长范围内的依赖。
- 当应用于高清的长视频时,训练深度 CNN 网络非常耗费计算资源。目前有研究发现,在静止图像的领域中,Transformer 训练和推导要比 CNN 更快。使得能够使用相同的计算资源来训练拟合能力更强的网络。
具体如何实现的?
这项工作基于图像模型 Vision Transformer(ViT),将自注意力机制从图像空间扩展到时空的 3D 空间。
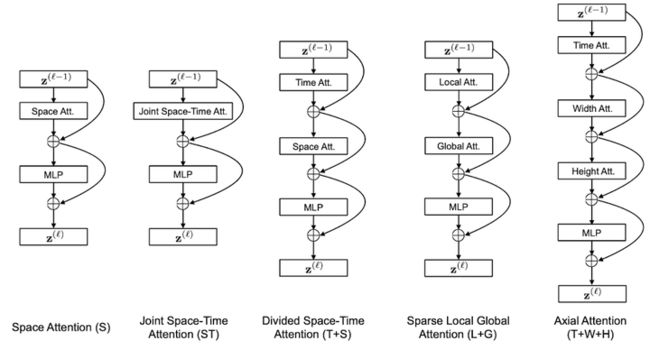
视频自注意力模块
在下图中可以清楚看到,注意力机制是如何运作的:

不同注意力施加方式
图中,蓝色的图像块是 query 的图像块,其余颜色的图像块,是每个自注意力策略使用到的图像块,没有颜色的图像块没有被使用到。策略中,有多种颜色的图像块,代表注意力机制是分开进行的,比如 T+S,就是先 T,后 S,L + G 也是同理。这里图中只展示了三帧,但是作用时是作用在整个序列上的。
通过对输入图像进行分块,论文中一共研究了五种不同的注意力机制:
- 空间注意力机制(S):只取同一帧内的图像块进行自注意力机制
- 时空共同注意力机制(ST):取所有帧中的所有图像块进行注意力机制
- 分开的时空注意力机制(T+S):先对同一帧中的所有图像块进行自注意力机制,然后对不同帧中对应位置的图像块进行注意力机制
- 稀疏局部全局注意力机制(L+G):先利用所有帧中,相邻的 H/2 和 W/2 的图像块计算局部的注意力,然后在空间上,使用2个图像块的步长,在整个序列中计算自注意力机制,这个可以看做全局的时空注意力更快的近似
- 轴向的注意力机制(T+W+H):先在时间维度上进行自注意力机制,然后在纵坐标相同的图像块上进行自注意力机制,最后在横坐标相同的图像块上进行自注意力机制
相信大家都已经对于 Transformer 的具体作用方式(q、k和v)已经很了解了,这里的话换了一下自注意力中的输入信息,所以就不展示公式了。感兴趣的可以阅读原文。
实验部分
自注意力机制的分析
在 K400 和 SSv2 数据集上研究了所提的五个自注意力策略,表中汇报的是视频级别的分类准确率。其中分开的时空注意力效果最好。

从表中可以看出,对于 K400 数据集,仅使用空间信息已经能够分类比较好了,这些前面的研究者也发现了,但是,对于 SSv2 数据集来说,仅仅使用空间信息的效果非常差。这说明了对时间建模的重要性。
图像大小和视频长度的影响
当每一个图像块的大小不变时,图像越大,图像块的个数越多。同时,帧数越多,输入注意力机制的数据也越多。作者也研究了这些对于最终性能的影响,结果是随着输入信息更加丰富,带来的效果提升是非常明显的。

这里由于显存的限制,没有办法测试 96 帧以上的视频片段。作者说,这已经是一个很大的提升了, 因为目前的卷积模型,输入一般都被限制在 8-32 帧。
预训练和数据集规模的重要性
因为这个模型需要非常大的数据才能够训练,作者有尝试自己从头训练,但是都失败了,因此在论文中报告的所有结果,都使用了 ImageNet 进行预训练。

为了研究数据集的规模的影响,使用了两个数据集,实验中,分四组,分别使用25%,50%,75%和100%的数据。结果是 TimeSformer 当数据比较少的时候表现不太好,数据多的时候表现好。
与 SOTA 比较
在本节中使用了三个模型的变种:
- TimeSformer :输入 8224224,8为帧数
- TimeSformer-HR:空间清晰度比较高,输入为 16448448
- TimeSformer-L:时间范围比较广,输入为 96224224
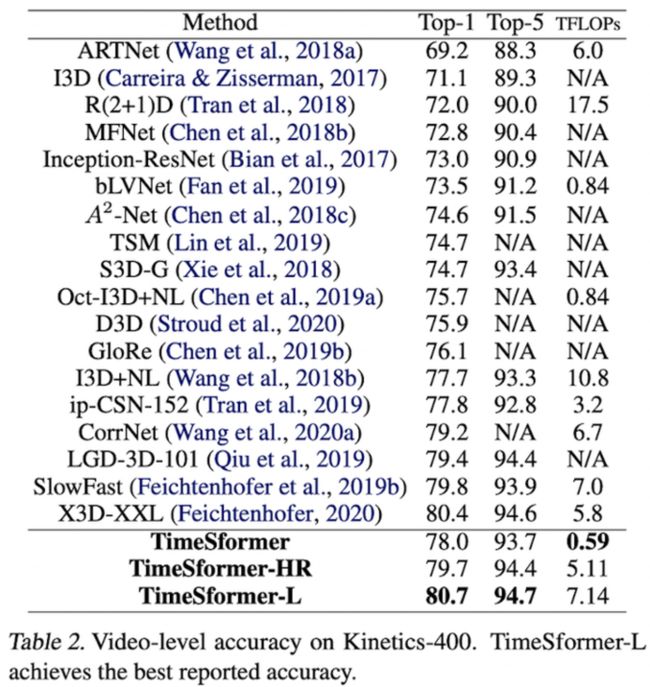
在 K400 数据集上视频分类的结果,达到了SOTA。
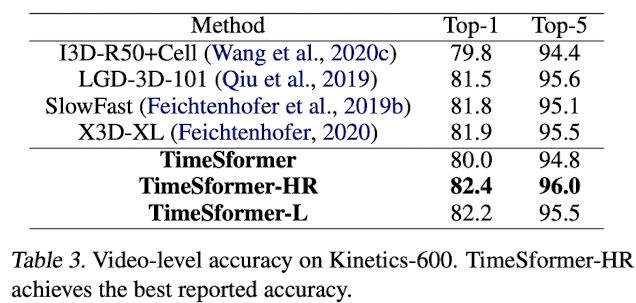
K600数据集上的结果,达到了 SOTA。
SSv2和Diving48上的结果,SSv2并没有达到最好的结果,作者提到说所提方法采用了完全不同的结构,对于这么有挑战性的数据集来说已经是比较好的了,有进一步发展的空间。

视频中的长期建模
作者还验证了所提模型相比于 CNN 来说,对于长期视频建模的优势。这一步使用了 HowTo100M 数据集。

其中,# Input Frames 代表输入模型的帧数,Single Clip Coverage 代表输入的一段视频覆盖了多久的视频,# Test Clips 代表预测阶段,需要将输入视频裁剪几段才能输入进网络。可以看到,当TimeSformer 输入96帧时,能够有效利用视频中长期依赖的信息,达到了最好的效果。
参考资料
- ViT(Vision Transformer):https://arxiv.org/abs/2010.11929
- 这篇原始论文链接:https://arxiv.org/pdf/2102.05095.pdf
- 代码:https://github.com/lucidrains/TimeSformer-pytorch
写在最后:如果觉得这篇文章对您有帮助,欢迎点赞收藏评论支持我,谢谢!也欢迎关注我的公众号:算法小哥克里斯。