摘要:本文从总体架构、主打场景、关键技术特性等方面进行介绍GaussDB(for openGauss)。
本文分享自华为云社区《技术直播解读第1期:认识华为云数据库GaussDB(for openGauss)》,原文作者:心机胖。
1.背景介绍
3月16日,在华为云主办的GaussDB(for openGauss)系列技术第一期直播课《认识华为云数据库 GaussDB(for openGauss) 》上,有这样一个提问:开源数据库这么香,为什么华为还要下功夫自研GaussDB(for openGauss)?
其实,不少开源数据库在易用性、配套能力等方面较弱,需要不断维护,而且一旦遇到数据丢失问题,很难快速恢复,造成的损失不可估量。也因此,开源数据库上云只能解决中小企业的简化部署、运维、调优、极致性价比等诉求。
与此同时,开源数据库还得面临服务器、数据库维护升级、人力运维等各种大大小小的成本支出,很难满足业务的快速扩张以及可持续发展。面对金融、政企等对数据安全、响应速度、可靠性、可用性有严苛要求的大型企业,就需要超高可用、功能完备、性能卓越、开放生态、极致弹性的企业级数据库服务。
GaussDB(for openGauss)是华为深度融合多年数据库领域经验,充分结合企业级场景需求,基于openGauss自研生态推出的企业级分布式关系型数据库。目前支持单分片和分布式两种部署形态,在支撑传统业务的基础上,持续构建竞争力特性,为企业面向5G时代的挑战,提供了无限可能。
为了让大家快速了解GaussDB(for openGauss),华为云数据库团队准备了GaussDB(for openGauss)系列技术直播,本文将结合第一场直播内容从总体架构、主打场景、关键技术特性等方面进行介绍。
2.总体架构:统一基于数据分片的分布式架构
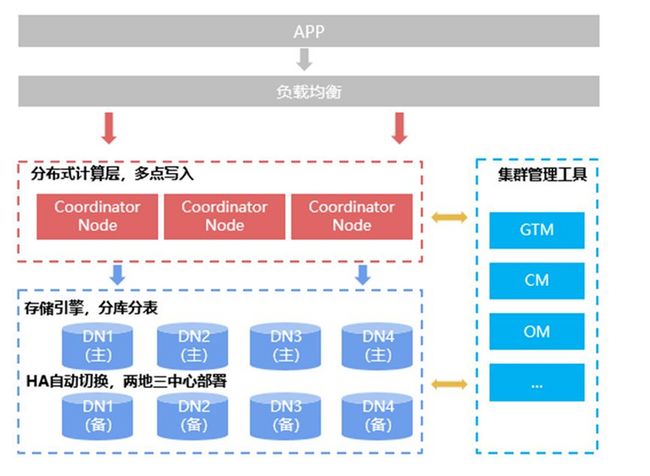
GaussDB(for openGauss)统一基于数据分片的分布式架构(share nothing),底层数据通过一定的规则比如hash、list或者range等让数据打散分布到不同的数据节点上,计算时底层多个节点共同参与计算。同时数据节点可以扩展,上层由协调节点进行SQL解析和转发。
从图中可以看到,主要包括三类节点:协调节点、数据节点、集群类节点(最重要的是全局事务管理器)。协调节点负责SQL解析转发,充当的是类似proxy的角色,数据节点负责计算和数据存储,全局事务管理器负责全局事务读一致性的保证。
这种架构为GaussDB(for openGauss)构建了以下核心优势:
- 极致高可用: 两地三中心架构,跨Region数据实时灾备
- 数据安全: 实现跨AZ部署数据强一致性,保证数据0丢失
- 高扩展性:容器化部署,性能容量按需水平扩展,高达1000+节点
- 性能强劲:鲲鹏2路服务器,32节点1200万tpmC(华为内部测试)
- 全栈软硬自研可控:业界领先的鲲鹏+openGauss自研开放内核
3.主打场景
场景一:传统核心交易
针对传统的应用,可以使用单分片的模式,使用方式同传统的主备模式相同。GaussDB(for openGauss)结合鲲鹏深度优化,性能非常出众,同时在可用性上做了极大的提升,非常适合传统商业数据库的替换场景。

场景二:未来海量事务型
随着5G时代的到来,单一节点是难以应对数据规模的不断增长并确保性能的需要,而跨节点、可横向扩展的数据库可以很好解决大规模海量数据的计算存储需要。GaussDB(for openGauss)分布式模式最大可以支持1000+节点,PB级存储,分布式事务强一致等特性可以很好地满足政府、交通、金融、能源等行业的互联网+的诉求。
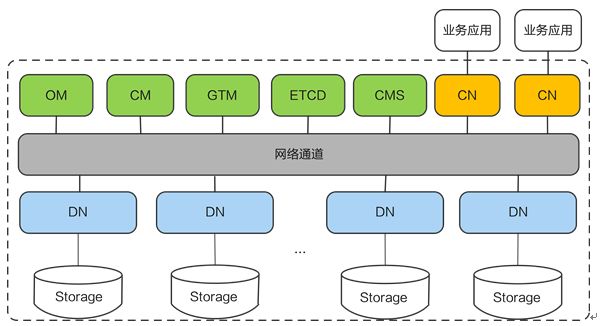
关键角色
为了方便大家更好理解GaussDB(for openGauss)的技术运行状态,下面将对GaussDB(for openGauss)一些关键角色进行介绍:

4.关键技术特性
GaussDB(for openGauss)基于计算存储分离的分布式架构,构建了6大核心技术特性,下面将对这6大特性进行详细解读。
关键技术一:高性能—分布式执行框架
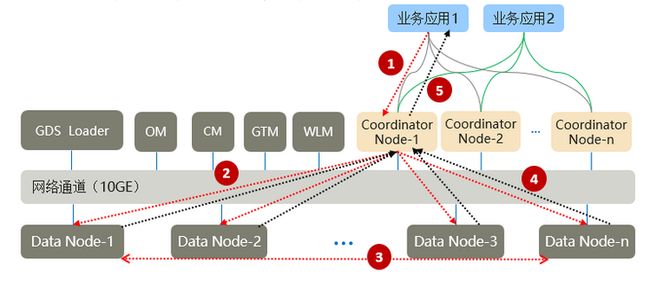
该特性的大致执行过程为:
- 业务应用下发SQL给Coordinator ,SQL可以包含对数据的CRUD操作;
- Coordinator利用数据库的优化器生成执行计划,每个DN会按照执行计划的要求去处理数据;
- 数据基于一致性Hash算法分布在每个DN,因此DN在处理数据的过程中,可能需要从其他DN获取数据,GaussDB提供三种stream流(广播流、聚合流和重分布流)实现数据在DN间的流动;
- DN将结果集返回给Coordinate进行汇总;
- Coordinator将汇总后的结果返回给业务应用。
华为在SQL执行优化方面有多年的沉淀,即使是复杂的SQL、事务分析混合(HTAP)的场景也能得到最佳的执行,举个列子:
- 基于代价的优化
- 基数估算:Feedback增强、AI基数增强
- 代价估算:行存/列存代价估算、网络通信代价估算
- 搜索算法:动态规划方法、遗传算法、AI搜索
- 分布式执行计划能力
- Light Proxy
- Fast Query Shipping
- Remote Query Shipping
- 自研Cascade优化器
- 对象化处理规则应用及搜索任务
- 基于分支限界的剪枝技术
通过分布式查询引擎、分布式调度引擎、分布式存储引擎,GaussDB(for openGauss)完美做到了数据的自动分片,并利用查询优化器在自动负载均衡的同时不断提升执行计划处理效率;在数据节点上针对不同数据场景提供分场景stream流(广播流、聚合流、重分布流),不断提升多分片数据节点间的交互效率,并自动完成数据的结果汇总,保障分布式事务的全局一致性。
关键技术二:高性能—分布式事务处理性能,GTM-Lite技术
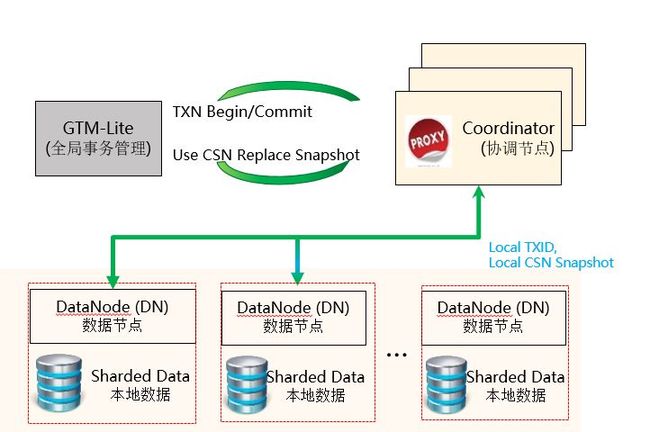
该特性的优势是:
- 高性能事务管理:支持无锁、多版本、高并发事务技术。
- 分布式强一致:分布式的GTM-Lite方案提供全局事务快照和提交号管理,实现强一致性,且无中心节点性能瓶颈。
关键技术三:高性能—Scale-up能力,突破鲲鹏4P NUMA-Aware新架构,实现4P服务器性能突破
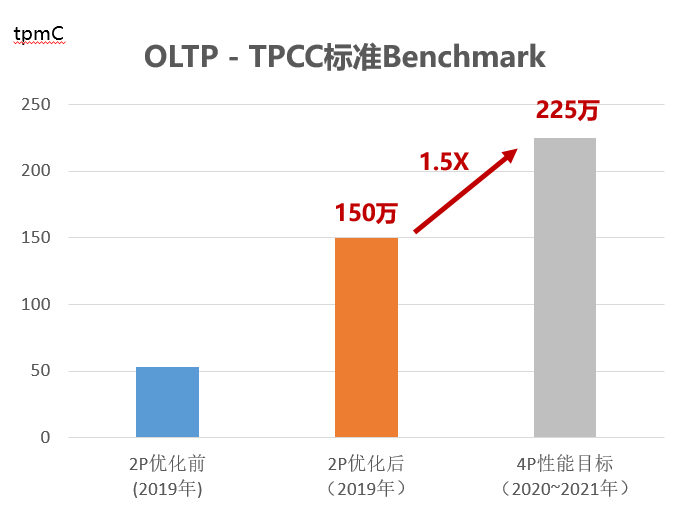
GaussDB(for openGauss)使用Numa Aware技术,根据鲲鹏处理器多核NUMA架构特点进行系列优化,通过绑核技术避免内存跨核访问,减少时延问题;通过应用重做日志批量插入、热点数据NUMA分布、Clog分区等关键技术,充分发挥多核算力优势,不断降低访问延迟,日志写冲突,索引更新冲突。当前基于泰山鲲鹏服务器,TPCC性能压测是同规格x86的1.5倍。
关键技术四:高可用—集群HA,多层级冗余实现系统无单点故障
GaussDB(for openGauss)通过硬件冗余、实例冗余、数据冗余,实现整个系统软硬件无单点故障。不同于传统数据库软件产品,GaussDB(for openGauss)主要着重于通过软件能力来提供高可用、高可靠保障。华为云基于软硬件底座,做到端到端数据库高可用能力,并支持对整个场景进行端到端监控&检测,能够更及时、更可靠地保障用户的应用在线、数据0丢失,实现全栈无单点故障。
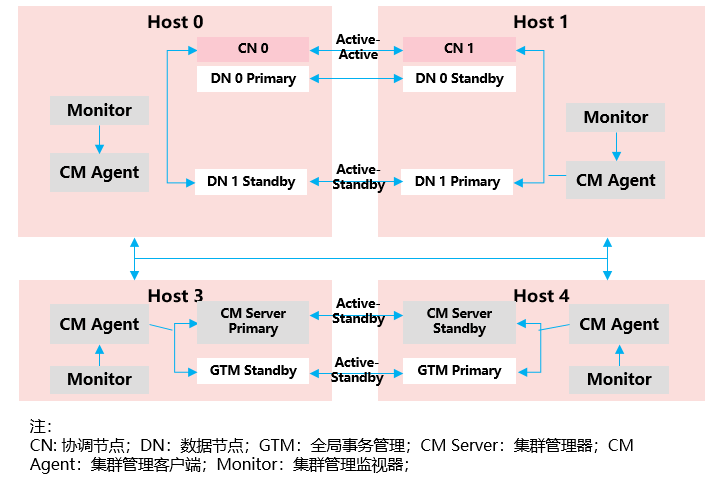
高可用技术点
硬件高可用:
- 存储:磁盘RAID冗余。
- 网络:双交换机冗余。
- 网卡:多网卡冗余。
- 主机:UPS电源保护
软件高可用:
- 协调节点CN实例多活冗余
- 数据节点/全局事务管理/ 集群管理器实例Active-Standby冗余
故障检测
- 网络故障检测和处理(交换机路由器等)
- 网卡故障检测和处理(本地网卡故障检测)
- 磁盘故障检测和处理:磁盘心跳,处理文件系统返回的错误码
- 主机掉电检测和处理:Heartbeat机制
- 集群实例故障检测和处理(CN/DN/GTM进程非法终止)
- 集群软件故障
关键技术五:高可用—跨AZ/Region容灾技术
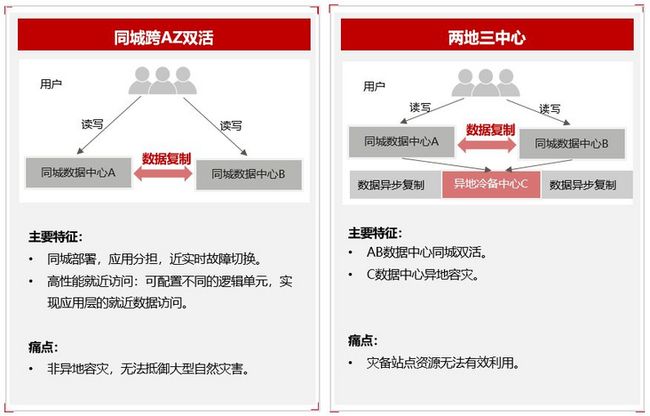
GaussDB(for openGauss)当前已经支持同城单集群跨AZ双活,RPO=0,RTO<60s;双集群跨Region两地三中心容灾,RPO<10s,RTO< 10m,该方案在支持跨Region容灾的同时,支持容灾节点最小化,有效降低用户容灾成本,同时允许用户在故障场景升主后对容灾节点进行在线扩展,保证业务不中断的同时提升用户原容灾实例的可靠性和可用性。
关键技术六:高扩展—Scale-out在线横向扩展
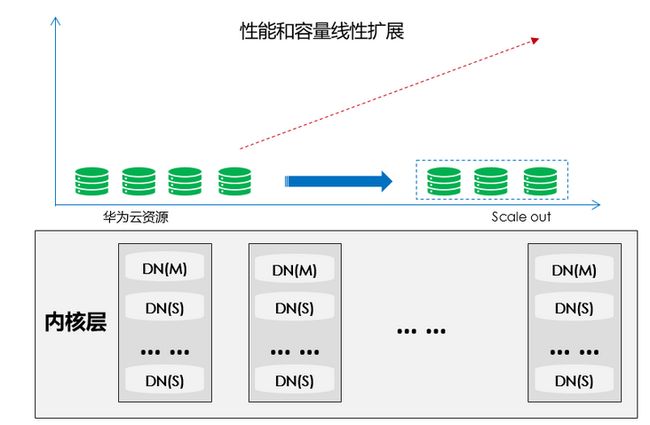
GaussDB(for openGauss)单集群计算节点最大规模支持1000+,同时拥有卓越的线性扩展能力。
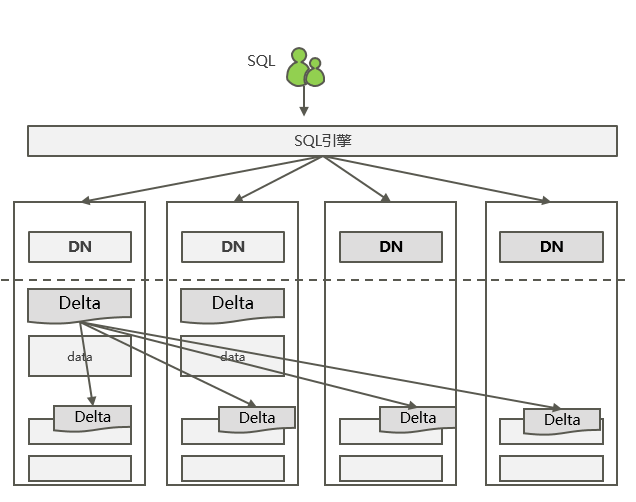
单集群分片扩展支持数据自动在线完成重分布操作,支持PB级海量事务型存储扩展能力。
综上所述,GaussDB(for openGauss)具备企业级事务混合负载能力,支持分布式事务强一致,同城跨AZ部署,数据0丢失,支持1000+的计算节点扩展能力,PB级海量存储。同时拥有云上高可用,高可靠,高安全,弹性伸缩,一键部署,快速备份恢复,监控告警等关键能力,能为企业提供功能全面、稳定可靠、扩展性强、性能优越的企业级数据库服务,目前已全网开放商用。而且它也是一个开放生态的产品,单分片版本的源代码已经开源,社区地址为:https://opengauss.org,欢迎大家自行下载、安装和体验。
Ps:错过GaussDB(for openGauss)专场直播的小伙伴们注意了,点击链接可直接回顾,快来观看吧>> https://bbs.huaweicloud.com/live/cloud_live/202103161900.html