离散热图
0.需求
今天在群里看到一个非常漂亮的热图,我以为是什么奇怪的新R包画的,转了一圈发现原来还是大名鼎鼎的ComplexHeatmap丫。今天的代码都是在作者写的书基础上探索学习的,书在:https://jokergoo.github.io/ComplexHeatmap-reference/book/
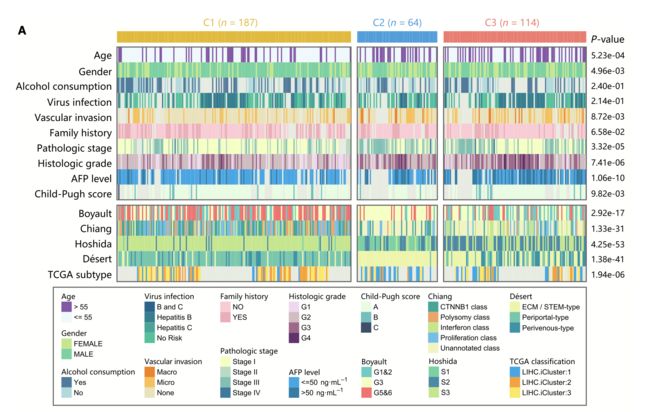
这种图和普通热图的不同点:
- 数据是离散型的,与常规的数值型热图不同。
- 每行单独配色,颜色逐行变化
- 左右两边都有文字
- 划分的不同板块有格子
1.学习普通的离散型热图
以前画的热图无一例外都是连续型数值,这次是离散型数据咯,矩阵里面只有四个取值,所以就只有四个颜色。如果不指定的话,颜色就是随机的:
rm(list = ls())
library(ComplexHeatmap)
library(RColorBrewer)
library(circlize)
discrete_mat = matrix(sample(letters[1:4], 100, replace = TRUE), 10, 10)
Heatmap(t(discrete_mat),
column_split = discrete_mat[, 1],
top_annotation = HeatmapAnnotation(group = discrete_mat[, 1]),
border = T)
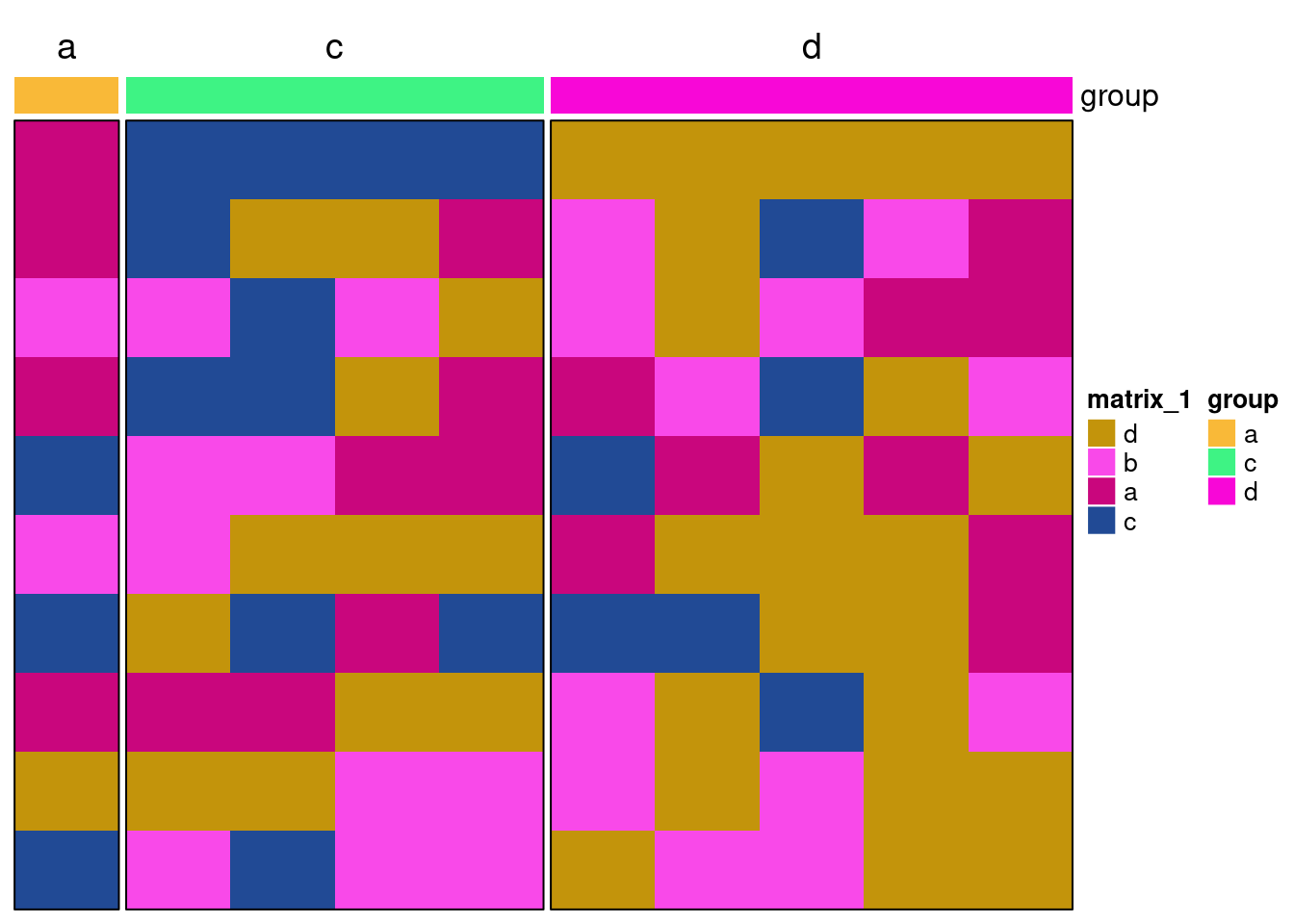
请忽略配色
切割、加边框、加注释这样的操作,参数还是蛮好找的。
编一个类似于上面那张图的输入数据,画画看。每一行都是有重复值的不同向量,并且向量的取值数量都是有限的。
sl = function(letter,n = sample(2:4,1),ncol = 100){
sample(paste0(letter,1:n),ncol,replace = T)
}
table(sl("a"))
##
## a1 a2 a3 a4
## 21 31 25 23
dat = t(sapply(letters[1:10], sl))
rownames(dat) = LETTERS[1:10]
colnames(dat) = paste0("M",1:ncol(dat))
dat[1:4,1:4]
## M1 M2 M3 M4
## A "a1" "a2" "a1" "a2"
## B "b2" "b2" "b2" "b2"
## C "c1" "c1" "c1" "c2"
## D "d2" "d1" "d2" "d3"
col_group = rep(c("C1","C2","C3"),times = c(30,40,30))
row_group = rep(c("x","y"),times = c(6,4))
Heatmap(dat, name = "mat",
top_annotation = HeatmapAnnotation(cluster = col_group),
left_annotation = rowAnnotation(foo1 = row_group),
column_split = col_group,
row_split = row_group,
border = T,show_column_names = F)
请忽略配色
2.自定义颜色
ComplexHeatmap有一个特点,如果你不指定配色的话,每次运行相同代码出来的图配色都不一样哦,所以接下来自己定义颜色。
这里用到一个函数:colorRamp2,出自circlize包,可以根据你指定的几个颜色,生成一组渐变色。
# 主体热图的颜色
m = apply(dat,1,function(x){length(unique(x))})
col_fun = colorRamp2(breaks = seq(0, 1, length.out = 12),
colors = brewer.pal(12,"Set3"))
qz = sort(unique(as.character(dat)));length(qz)
## [1] 28
colors = col_fun(seq(0, 1, length.out = length(qz)))
names(colors) = qz
head(colors)
## a1 a2 b1 b2 b3 c1
## "#8DD3C7FF" "#BFE5BFFF" "#ECF7B7FF" "#F2EFBDFF" "#D8D3CDFF" "#C2B8D6FF"
# 注释条的颜色
color_an = brewer.pal(length(unique(col_group)),"Dark2")
names(color_an) = unique(col_group)
color_an
## C1 C2 C3
## "#1B9E77" "#D95F02" "#7570B3"
#顶部注释
top_annotation = HeatmapAnnotation(cluster = col_group,col = list(cluster = color_an),show_legend = F,show_annotation_name = F)
f = Heatmap(dat, col = colors,
top_annotation = top_annotation,
row_split = ifelse(row_group=="x",""," "), #这一句是为了隐藏行分组的名字
column_split = col_group,
show_heatmap_legend = F,
border = T,show_column_names = F,row_names_side = "left",
right_annotation = rowAnnotation(score = anno_text(1:nrow(dat)))
)
f
隐藏图例了
3.自定义图例
前面有个参数是show_heatmap_legend = F,show_legend = F,是不显示主体与注释图例的意思。这里之所以不显示是为了自定义图例。否则呢,主体热图的图例就会全部放在一起,不能按行来显示哦。
# 主体热图的图例
k = 1
lgd = list()
for(i in 1:10){
un = sort(unique(dat[i,]))
ti = rownames(dat)[i]
lgd[[i]] = Legend(seq(0, 1, length.out = length(un)), labels = un,
title = ti, legend_gp = gpar(fill =colors[k:(k+length(un)-1)]))
k = k + length(un)
}
# 注释的图例
cld = Legend(labels = c("a1","a2","a3"), title = "cluster",
legend_gp = gpar(fill = color_an))
# 把各个图例合并在一起
p = packLegend(list = c(cld,lgd),
direction = "horizontal",gap = unit(0.6, "cm"))
draw(p)

全部的图例哦
# 主体和图例画到一起
draw(f,heatmap_legend_list = p,heatmap_legend_side = "bottom")
收工