1 K-均值聚类(K-means)概述
1.1 聚类
“类”指的是具有相似性的集合。聚类是指将数据集划分为若干类,使得类内之间的数据最为相似,各类之间的数据相似度差别尽可能大。聚类分析就是以相似性为基础,对数据集进行聚类划分,属于无监督学习。
1.2 无监督学习和监督学习
和KNN所不同,K-均值聚类属于无监督学习。那么监督学习和无监督学习的区别在哪儿呢?监督学习知道从对象(数据)中学习什么,而无监督学习无需知道所要搜寻的目标,它是根据算法得到数据的共同特征。比如用分类和聚类来说,分类事先就知道所要得到的类别,而聚类则不一样,只是以相似度为基础,将对象分得不同的簇。
1.3 K-means
K-means算法具有悠久的历史,并且也是最常用的聚类算法之一。K-means算法实施起来非常简单,因此,它非常适用于机器学习新手爱好者。
1967年,James MacQueen在他的论文《用于多变量观测分类和分析的一些方法》中首次提出 “K-means”这一术语。1957年,贝尔实验室也将标准算法用于脉冲编码调制技术。1965年,E.W. Forgy发表了本质上相同的算法——Lloyd-Forgy算法。
k-means算法是一种简单的迭代型聚类算法,采用距离作为相似性指标,从而发现给定数据集中的K个类,且每个类的中心是根据类中所有值的均值得到,每个类用聚类中心来描述。对于给定的一个包含n个d维数据点的数据集X以及要分得的类别K,选取欧式距离作为相似度指标,聚类目标是使得各类的聚类平方和最小,即最小化:
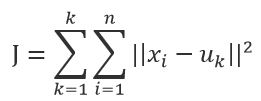
结合 最小二乘法和拉格朗日原理,聚类中心为对应类别中各数据点的平均值,同时为了使得算法收敛,在迭代过程中,应使最终的聚类中心尽可能的不变。
1.4 K-Means算法的十大用例
K-means算法通常可以应用于维数、数值都很小且连续的数据集,比如:从随机分布的事物集合中将相同事物进行分组。
1.文档分类器
根据标签、主题和文档内容将文档分为多个不同的类别。这是一个非常标准且经典的K-means算法分类问题。首先,需要对文档进行初始化处理,将每个文档都用矢量来表示,并使用术语频率来识别常用术语进行文档分类,这一步很有必要。然后对文档向量进行聚类,识别文档组中的相似性。 这里是用于文档分类的K-means算法实现案例。2.物品传输优化
使用K-means算法的组合找到无人机最佳发射位置和遗传算法来解决旅行商的行车路线问题,优化无人机物品传输过程。3.识别犯罪地点
使用城市中特定地区的相关犯罪数据,分析犯罪类别、犯罪地点以及两者之间的关联,可以对城市或区域中容易犯罪的地区做高质量的勘察。这是基于德里飞行情报区犯罪数据的论文。4.客户分类
聚类能过帮助营销人员改善他们的客户群(在其目标区域内工作),并根据客户的购买历史、兴趣或活动监控来对客户类别做进一步细分。这是关于电信运营商如何将预付费客户分为充值模式、发送短信和浏览网站几个类别的白皮书。对客户进行分类有助于公司针对特定客户群制定特定的广告。5.球队状态分析
分析球员的状态一直都是体育界的一个关键要素。随着竞争越来愈激烈,机器学习在这个领域也扮演着至关重要的角色。如果你想创建一个优秀的队伍并且喜欢根据球员状态来识别类似的球员,那么K-means算法是一个很好的选择。6.保险欺诈检测
机器学习在欺诈检测中也扮演着一个至关重要的角色,在汽车、医疗保险和保险欺诈检测领域中广泛应用。利用以往欺诈性索赔的历史数据,根据它和欺诈性模式聚类的相似性来识别新的索赔。由于保险欺诈可能会对公司造成数百万美元的损失,因此欺诈检测对公司来说至关重要。这是汽车保险中使用聚类来检测欺诈的白皮书。7.乘车数据分析
面向大众公开的Uber乘车信息的数据集,为我们提供了大量关于交通、运输时间、高峰乘车地点等有价值的数据集。分析这些数据不仅对Uber大有好处,而且有助于我们对城市的交通模式进行深入的了解,来帮助我们做城市未来规划。这是一篇使用单个样本数据集来分析Uber数据过程的文章。8.网络分析犯罪分子
网络分析是从个人和团体中收集数据来识别二者之间的重要关系的过程。网络分析源自于犯罪档案,该档案提供了调查部门的信息,以对犯罪现场的罪犯进行分类。这是一篇在学术环境中,如何根据用户数据偏好对网络用户进行 cyber-profile的论文。9.呼叫记录详细分析
通话详细记录(CDR)是电信公司在对用户的通话、短信和网络活动信息的收集。将通话详细记录与客户个人资料结合在一起,这能够帮助电信公司对客户需求做更多的预测。在这篇文章中,你将了解如何使用无监督K-Means聚类算法对客户一天24小时的活动进行聚类,来了解客户数小时内的使用情况。10.IT警报的自动化聚类
大型企业IT基础架构技术组件(如网络,存储或数据库)会生成大量的警报消息。由于警报消息可以指向具体的操作,因此必须对警报信息进行手动筛选,确保后续过程的优先级。对数据进行聚类可以对警报类别和平均修复时间做深入了解,有助于对未来故障进行预测。
1.5 应用示例
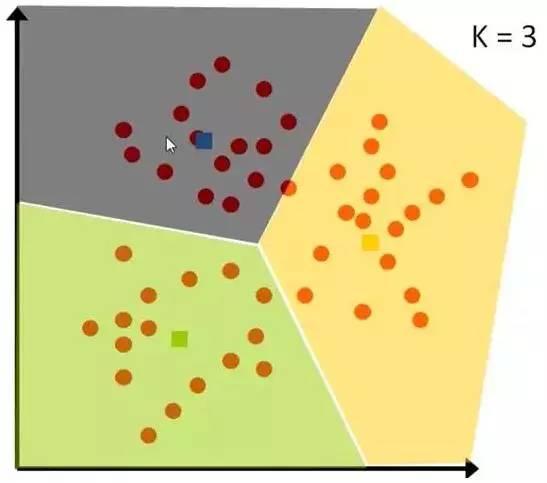
想要将一组数据,分为三类,粉色数值大,黄色数值小。
最开心先初始化,这里面选了最简单的 3,2,1 作为各类的初始值。
剩下的数据里,每个都与三个初始值计算距离,然后归类到离它最近的初始值所在类别。

分好类后,计算每一类的平均值,作为新一轮的中心点。

几轮之后,分组不再变化了,就可以停止了。

1.6 算法流程
K-means是一个反复迭代的过程,算法分为四个步骤:
1) 选取数据空间中的K个对象作为初始中心,每个对象代表一个聚类中心;
2) 对于样本中的数据对象,根据它们与这些聚类中心的欧氏距离,按距离最近的准则将它们分到距离它们最近的聚类中心(最相似)所对应的类;
3) 更新聚类中心:将每个类别中所有对象所对应的均值作为该类别的聚类中心,计算目标函数的值;
4) 判断聚类中心和目标函数的值是否发生改变,若不变,则输出结果,若改变,则返回2)。
用以下例子加以说明:
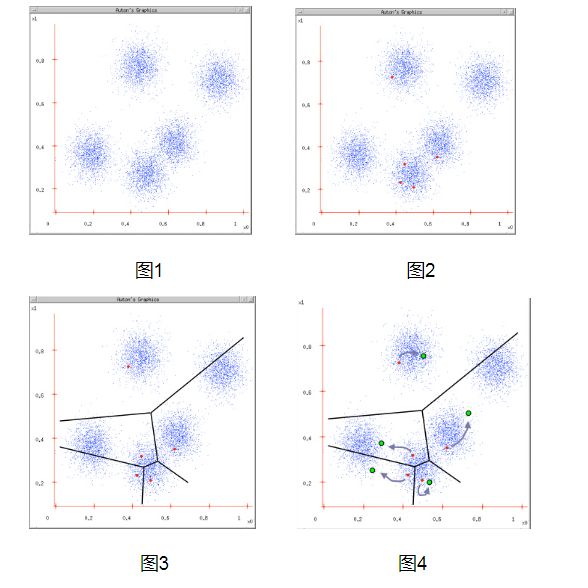
图1:给定一个数据集;
图2:根据K = 5初始化聚类中心,保证 聚类中心处于数据空间内;
图3:根据计算类内对象和聚类中心之间的相似度指标,将数据进行划分;
图4:将类内之间数据的均值作为聚类中心,更新聚类中心。
最后判断算法结束与否即可,目的是为了保证算法的收敛。
2 Python实现
2.1 计算过程
st=>start: 开始
e=>end: 结束
op1=>operation: 读入数据
op2=>operation: 随机初始化聚类中心
cond=>condition: 是否聚类是否变化
op3=>operation: 寻找最近的点加入聚类
op4=>operation: 更新聚类中心
op5=>operation: 输出结果
st->op1->op2->op3->op4->cond
cond(yes)->op3
cond(no)->op5->e
2.2 输入样例
15.55,28.65
14.9,27.55
14.45,28.35
14.15,28.8
13.75,28.05
13.35,28.45
13,29.15
13.45,27.5
13.6,26.5
12.8,27.35
2.3 代码实现
__author__ = 'Bobby'
from numpy import *
import matplotlib.pyplot as plt
import time
INF = 9999999.0
def loadDataSet(fileName, splitChar='\t'):
"""
输入:文件名
输出:数据集
描述:从文件读入数据集
"""
dataSet = []
with open(fileName) as fr:
for line in fr.readlines():
curline = line.strip().split(splitChar)
fltline = list(map(float, curline))
dataSet.append(fltline)
return dataSet
def createDataSet():
"""
输出:数据集
描述:生成数据集
"""
dataSet = [[0.0, 2.0],
[0.0, 0.0],
[1.5, 0.0],
[5.0, 0.0],
[5.0, 2.0]]
return dataSet
def distEclud(vecA, vecB):
"""
输入:向量A, 向量B
输出:两个向量的欧式距离
"""
return sqrt(sum(power(vecA - vecB, 2)))
def randCent(dataSet, k):
"""
输入:数据集, 聚类个数
输出:k个随机质心的矩阵
"""
n = shape(dataSet)[1]
centroids = mat(zeros((k, n)))
for j in range(n):
minJ = min(dataSet[:, j])
rangeJ = float(max(dataSet[:, j]) - minJ)
centroids[:, j] = minJ + rangeJ * random.rand(k, 1)
return centroids
def kMeans(dataSet, k, distMeans=distEclud, createCent=randCent):
"""
输入:数据集, 聚类个数, 距离计算函数, 生成随机质心函数
输出:质心矩阵, 簇分配和距离矩阵
"""
m = shape(dataSet)[0]
clusterAssment = mat(zeros((m, 2)))
centroids = createCent(dataSet, k)
clusterChanged = True
while clusterChanged:
clusterChanged = False
for i in range(m): # 寻找最近的质心
minDist = INF
minIndex = -1
for j in range(k):
distJI = distMeans(centroids[j, :], dataSet[i, :])
if distJI < minDist:
minDist = distJI
minIndex = j
if clusterAssment[i, 0] != minIndex:
clusterChanged = True
clusterAssment[i, :] = minIndex, minDist**2
for cent in range(k): # 更新质心的位置
ptsInClust = dataSet[nonzero(clusterAssment[:, 0].A == cent)[0]]
centroids[cent, :] = mean(ptsInClust, axis=0)
return centroids, clusterAssment
def plotFeature(dataSet, centroids, clusterAssment):
m = shape(centroids)[0]
fig = plt.figure()
scatterMarkers = ['s', 'o', '^', '8', 'p', 'd', 'v', 'h', '>', '<']
scatterColors = ['blue', 'green', 'yellow', 'purple', 'orange', 'black', 'brown']
ax = fig.add_subplot(111)
for i in range(m):
ptsInCurCluster = dataSet[nonzero(clusterAssment[:, 0].A == i)[0], :]
markerStyle = scatterMarkers[i % len(scatterMarkers)]
colorSytle = scatterColors[i % len(scatterColors)]
ax.scatter(ptsInCurCluster[:, 0].flatten().A[0], ptsInCurCluster[:, 1].flatten().A[0], marker=markerStyle, c=colorSytle, s=90)
ax.scatter(centroids[:, 0].flatten().A[0], centroids[:, 1].flatten().A[0], marker='+', c='red', s=300)
def main():
#dataSet = loadDataSet('testSet2.txt')
dataSet = loadDataSet('788points.txt', splitChar=',')
#dataSet = createDataSet()
dataSet = mat(dataSet)
resultCentroids, clustAssing = kMeans(dataSet, 6)
print('*******************')
print(resultCentroids)
print('*******************')
plotFeature(dataSet, resultCentroids, clustAssing)
if __name__ == '__main__':
start = time.clock()
main()
end = time.clock()
print('finish all in %s' % str(end - start))
plt.show()
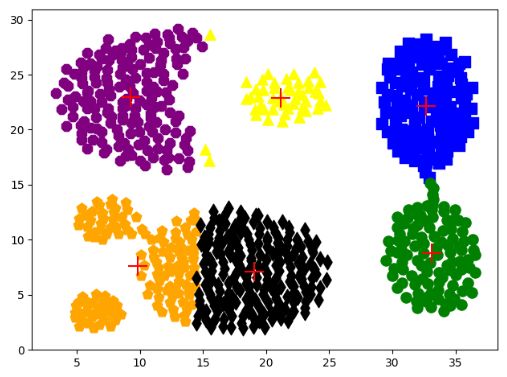
2.4 输出样例
*******************
[[32.69453125 22.13789062]
[33.14278846 8.79375 ]
[21.16041667 22.89895833]
[ 9.25928144 22.98113772]
[ 9.81847826 7.59311594]
[19.0637931 7.06551724]]
*******************
finish all in 2.270720974