路由算法是网络层软件的一部分。子网提供数据报服务,每个包都要做路由选择;子网提供虚电路服务,只需在建立连接时做一次路由选择
路由算法应具有的特性:
正确性,简单性,健壮性(鲁棒性,网络出现意外情况时候的解决问题的能力。例如突然某个路由器停电了,使得周边的路由器都没法正常工作,如果出现这样的问题说明路由器的健壮性不够),稳定性(常规使用是否稳定,数据量增多的时候能否正常工作),公平性(网络资源的使用是否公平,避免有些节点出现特别繁忙的状态,而有些节点总是处于很闲的状态),最优性
路由算法分类
• 按转发方式和数据副本数量划分
1.全路路由(广播路由)算法:如洪泛算法,按照所有路径广播转发(中间转发节点以及目标节点都会送到很多重复数据。不需要路由表和路由控制功能)
2.多路路由算法:向所有接近目的节点的路径转发(中间转发节点以及目标节点都会送到很多重复数据。)
3.单路路由算法:如距离矢量算法,向目的节点沿着唯一的路径转发(中间的转发节点只转发一份数据即可)
• 按健壮性和简单性划分
1.非自适应算法(静态路由算法):不能根据网络流量和拓扑结构的变化更新路由表,使用静态路由表。需要人为的更改和设定。特点是简单、开销小、灵活性差。典型算法为基于流量的路由算法等
2.自适应算法(动态路由算法):可根据网络流量(网络承载的数据量)和拓扑结构的变化更新路由表。特点是开销大、健壮性和灵活性好。典型算法为距离向量路由算法、链路状态路由算法等
☆可以静态路由和动态路由结合起来使用,此时静态路由的优先级别较高
自适应路由算法工作过程
测量(获取)有关路由选择的网络度量参数(选择最优,比如是要求传播距离最短,还是要求传输时延短等)。如何测量?选取哪些网络参数?
将路由信息传送到适当的网络节点。传送给谁?如何传送?传送什么信息?
计算和更新路由表。更新路由表的算法
根据新路由表执行分组的转发
路由算法设计最优化原则
如果路由器J在路由器I到K的最优路由上,那么从J到K的最优路由一定落在同一路由上
汇集树
从所有的源节点到一个给定的目的节点的最优路由的集合形成了一个以目的节点为根的树,称为汇集树;路由算法的目的是找出并使用汇集树
最短路径路由
基本思想:构建子网的拓扑图,图中的每个节点代表一个路由器,每条弧代表一条通信线路。为了选择两个路由器间的路由,算法需要在图中找出节点间的最短路径
网络度量参数
节点数量;地理距离;传输延迟;距离、信道带宽等参数的加权函数
分层路由
网络规模增大带来的问题:路由器中的路由表增大;路由器为选择路由而占用的内存、CPU时间和网络带宽增大
分层路由:分而治之的思想;根据需要,将路由器分成区域、聚类、区和组;Fig.6-6,路由表由17项减为7项
分层路由带来的问题:路由表中的路由不一定是最优路由


☆分层路由功能大部分时候性能是比较好的,可以选择最优路径,但是有时也会选择到非最优路径。比如上图中如果想从1A到5C,应该是1A→1B→2A→2B→2D→5C是比较优的选择,但是按照1A的分层路由表显示,从区域1到区域5出口线路为1C,因此选择的路线为1A→1C→3B→4A→5A→5B→5C,这时就相对绕远了
• ❀距离向量路由算法❀
DVR - Distance Vector Routing
动态路由算法,也称Bellman - Ford路由算法或Ford - Fulkerson算法,最初用于ARPANET(Internet的前身),被RIP协议所采用
距离向量路由算法思想
每个路由器维护一张路由表,表中给出了到每个目的地的已知最佳距离和线路,并通过与相邻路由器交换距离信息来更新表;每隔一段时间,路由器向所有邻居节点发送它到每个目的节点的距离表,同时它也接收每个邻居节点发来的距离表;邻居节点X发来的表中,X到路由器I的距离为Xi,本路由器到X的距离为m,则路由器经过X到i的距离为Xi + m。根据不同邻居发来的信息,计算Xi + m,并取最小值,更新本路由器的路由表
距离向量路由算法原理图:

图1:
此时路由A把它的路由表发给路由B,B会综合从A得来的路由表来更新自己的矢量表↓
根据初始A矢量表和B矢量表得知B到A为6,B到C为1,B到D没有;两个表都有到E的距离,直接从B到E为8;如果B经由A再到E就要计算A到B的距离加上A到E的距离即可,即6+1=7
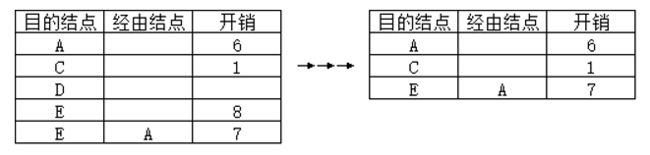
图2:
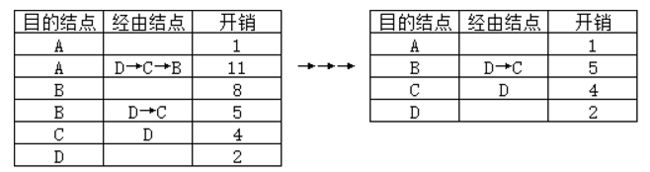
B把路由表发给C之后↓
从C的初始矢量表可得知C到B为1,C到D为2,C无法直接到A,但是通过B的路由表得知B到A为6,再加上C到B的距离1,得出C到A距离为7,同理可得到E距离为7+1=8

图3:
C把路由表发给D之后↓

图4:
D把路由表发给E之后↓
距离向量路由算法示意:

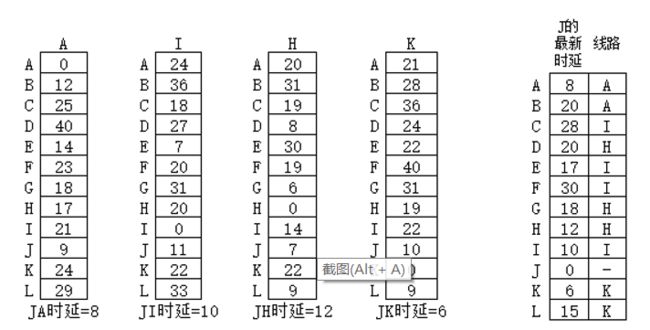
J的相邻节点为4个,分别为A,I,H,K,因此可以选择的路线也为4种
现在要求J的最新路由表。以J到E为例,J到A为8,A到E为14,和为22;J到I为10,I到E为7,和为17;J到H为12,H到E为30,和为42;J到K为6,K到E为22,和为28。从而得出,经由I的时候得到的和17最小,因此在新生成的J到E的位置记录17
距离向量路由算法无穷计算问题
无限计算问题:对好消息反应迅速,对坏消息反应迟钝
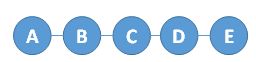
比如从E到A,E刚开始连通的时候是不知道如何才能到A的,只有通过B与A交互,C与B交互这样最终E通过与D交互才知道如何能到A,这就是好消息。可能需要花些时间,但是结果都是无论目的节点是哪里总会找到路径
坏消息例子:A,B,C之间通信。B到A的距离为1(A,1),C到A的距离为2(B(经B),2)。各个节点都会有一个刷新周期,到了这个周期的时候每个节点会把自己的路由信息发给其相邻节点。例如A路由断开连接,这个时候B到A的线路断开。也就是B到A的距离为无穷大了(A,∞)。如果在B把这个信息反馈给C之前,C先把路由信息告诉B了,那么B收到的信息就为(C,3)。因为A已经不存在,而B从C处得知通过C有路径可以到达A,这时B的路由表就变成(C,3),同样的这时B再告诉C,C就会变成(B,4),就会这样无穷计算下去。如果一开始是B先把信息发给C就不会发生这样的问题
解决方法:
• 触发式更新:节点不等到刷新周期的到来,只要有突发情况马上就会把情况通知相邻路由
• 水平分割:因为一开始C是从B得知经过B可以到达A的,所以用了这种方法之后,C就不会再向B发送如何到A,而只等着B给C发如何到A了。这样就不会有无穷计算问题
• 定义一个最大值:坏消息例子当中,括号里后面的数会一直循环增长下去,如果把这个数字设置一个最大值,那么当循环到这个最大值的时候双方就不会再就怎么到A的信息进行交互了,就不会发生无穷计算的情况
• 挂起计数器:坏消息例子当中,B收到了C的路由最新信息(C,3)的时候这个不会马上生效刷新,(A,∞)会保留两个周期,在这两个周期里面,B肯定有机会给C发送(A,∞),
而因为C没有通往A的路径,所以当C到刷新周期的时候给B发的就为(B,∞)。B前后收到的信息不一致,但是第二次收到的信息和B发给C的信息是一致的,所以B就会认为第一次收到的(C,3)是无效的。但是如果C真的有了一条通往A的线路,这时两次发的信息一定是一致的,那么B就会相信C的信息,从而把(A,∞)刷新成C给B的信息
❉距离向量路由算法只适用于小规模网络,每个节点不清楚整个网络的拓扑结构
• ❀链路状态路由算法❀
发现邻居节点,并学习它们的网络地址,测量到每个邻居节点的延迟或开销,将所有学习到的内容封装成一个链路状态包(包以发送方的标识符开头,后面是序号、年龄和一个邻居节点列表;链路状态包定期创建或发生重大事件时创建)。将链路状态包广播发送给所有其他路由器【洪泛方式:状态包包含一个序号,每次发送新包时加1。路由器记录信息对(源路由器,序号),当一个链路状态包到达时,若是新的则分发,若是重复的则丢弃,若序号比路由记录中的最大序号小则认为过时而丢弃】。计算到每个其他路由器的最短路径
☆链路状态路由算法适用于大规模网络。每个节点都会了解其他节点的局部拓扑,因此就会了解整个网络的拓扑结构,这时当前节点就能找到到目的节点的最优路由
链路状态路由算法
• 使用32位序号。
因为序号是循环使用的,如果位数很少,比如只是1~7,那么7不一定比1大,1有可能是下一轮的第一个数。而32位的时候因为数字特别庞大,不会出现这样问题
• 增加年龄域,每秒钟年龄减1,为零则丢弃
比如A发给B (C,4),由于差错,本来是(C,5)的下一个包,变成了(C,1000)。这之后来的(C,6),(C,7)。。。都没有(C,1000)大,因此包会被丢弃。但其实后面到的包都是新的。为了避免这样的问题发生,(C,1000)里的1000就会在每一秒减1,直到年龄比新到的包小,接下来就可以正常接包了。不过这之前到的包都会被丢弃,这也是没有办法的事
• 链路状态包到达后,延迟一段时间,并与其它已到达的来自同一路由器的链路状态包比较序号,丢弃重复包,保留新包
• 链路状态包需要应答
为了保证数据传输的可靠性