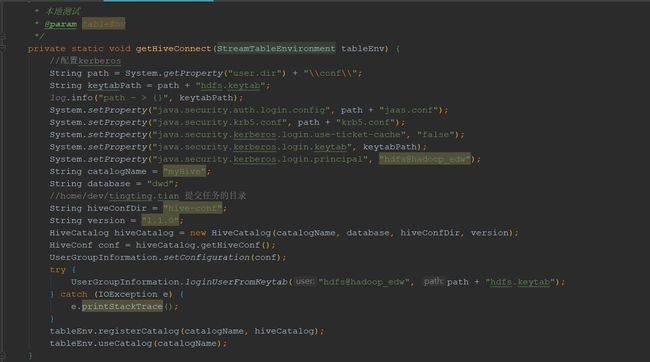
最近有个项目,需要读取hive表中的数据写到Hbase中,正好flink1.10版本刚出来,而且支持连接hive,那就他了。
哪想到这才是噩梦的开始。确定了技术栈,就开始着手写代码,按照习惯,官网打开瞅一眼案例:
这是依赖:
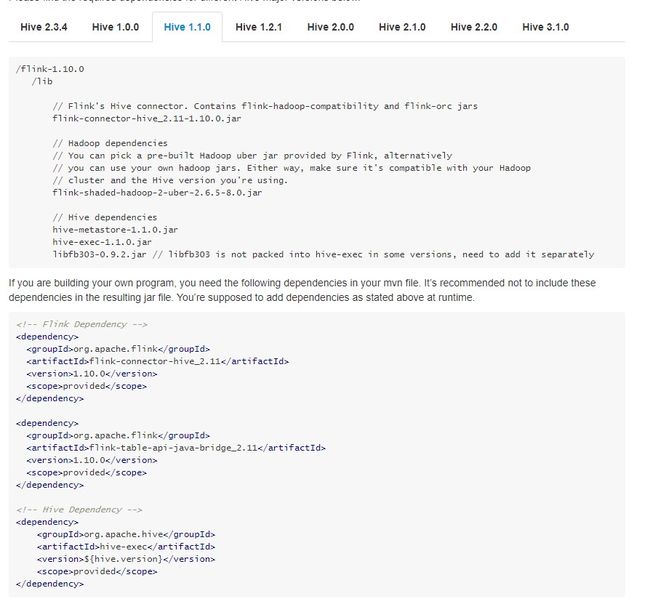
这是代码:

是不是觉得太简单了,太天真了。
开始构建工程,添加依赖,修改地址,开始本地跑

第一个,这个问题很明显是kerberos的问题,但是,我对Kerberos的问题一直很头疼,所以这个问题是同事解决的,给他点个赞。
加上关于kerberos的相关代码后,本地算是勉强调通了。
最终本地调试代码:
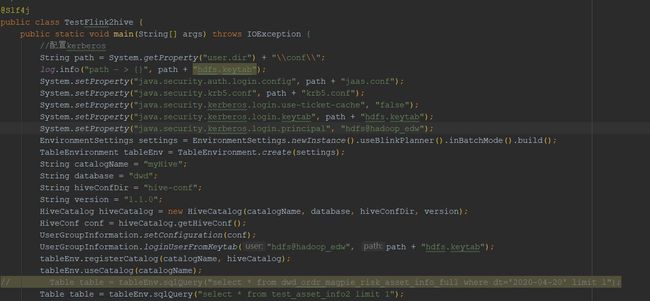
本地可以了,上集群测试,先来个简单的脚本吧

启动,报错

这个错误也很明确,你需要设置hadoop的配置文件的目录和依赖的目录(原因是flink从某版本(具体哪个版本记不清了)不再提供hadoop的依赖,所以需要手动添加,具体解决方案,在flink官网说的很清楚,传送门:https://ci.apache.org/projects/flink/flink-docs-release-1.10/ops/deployment/hadoop.html),好办,修改脚本

重新启动,紧接着异常

这个问题困惑了我好久,我知道是jar冲突,也知道是哪个jar包,但是不知道排除哪些依赖,后来晚上回家睡觉流程有捋了一下,才恍然大悟
我打包的时候,把flink-shaded-hadoop2的jar包打进了我的依赖中, 导致他和集群上hadoop的jar包冲突,只需要把这个包排掉就行
解决办法:上传集群时,去掉这个jar包
启动,又见异常:
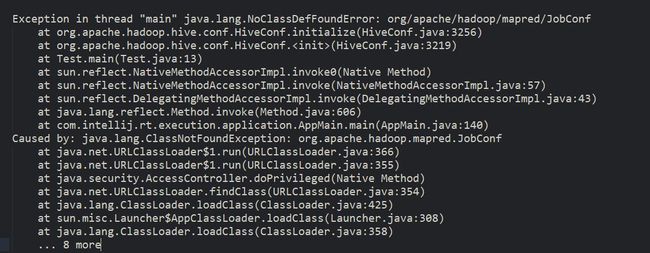
看到这个我心里有点数了,我导进来hadoop jar包和flink1.10的jar包冲突了,我懵逼了,这咋排??于是果断换个方案,下载flink-shaded-hadoop-2-uber-2.6.5-7.0.jar直接扔进flink/lib下,解决。
继续启动,异常又来:

解决办法:
紧接着,又报错,

添加依赖:
我以为就到此为止了吧,不,还有个绝的:

看到这个异常,我都懵了。这是啥问题??心态有点崩,找了各种资料,最终终于知道问题所在:
我的hive是cdh版本的,但是我添加的hadoop依赖flink-shaded-hadoop2是apache的。
解决办法:添加依赖
至此,我的任务终于跑起来了

看到结果,我倍感欣慰,这一路走来太不容易了,心态崩过好几次,幸好结果是好的。解决问题的过程虽然很痛苦,但是解决了问题后的感觉真的是超级棒!!
note:
flink连接hive处理流任务,读取hive表的数据时,即使加了limit的字段,也会将全表数据加载到state中,如果表很大,比如全量表,读起来会很慢,而且超级耗资源,慎用!!
但是,我想总会有解决的办法(有时间再更新)。期待flink对接hive越来越完善!!
贴出最终code和pom: