目标检测简介
图片理解的三个层次
理解一张图片?根据后续任务的需要,有三个主要的层次。

一是分类(Classification),即是将图像结构化为某一类别的信息,用事先确定好的类别(string)或实例ID来描述图片。这一任务是最简单、最基础的图像理解任务,也是深度学习模型最先取得突破和实现大规模应用的任务。其中,ImageNet是最权威的评测集,每年的ILSVRC催生了大量的优秀深度网络结构,为其他任务提供了基础。在应用领域,人脸、场景的识别等都可以归为分类任务。
二是检测(Detection)。分类任务关心整体,给出的是整张图片的内容描述,而检测则关注特定的物体目标,要求同时获得这一目标的类别信息和位置信息。相比分类,检测给出的是对图片前景和背景的理解,我们需要从背景中分离出感兴趣的目标,并确定这一目标的描述(类别和位置),因而,检测模型的输出是一个列表,列表的每一项使用一个数据组给出检出目标的类别和位置(常用矩形检测框的坐标表示)。
三是分割(Segmentation)。分割包括语义分割(semantic segmentation)和实例分割(instance segmentation),前者是对前背景分离的拓展,要求分离开具有不同语义的图像部分,而后者是检测任务的拓展,要求描述出目标的轮廓(相比检测框更为精细)。分割是对图像的像素级描述,它赋予每个像素类别(实例)意义,适用于理解要求较高的场景,如无人驾驶中对道路和非道路的分割。
目标检测
本系列文章关注的领域是目标检测,即图像理解的中层次。常见的深度学习目标检测算法分为两类:以yolo系列网络为代表的One-stage网络和以faster-rcnn为代表的Two-stage网络。
对于上述网络的常见理解是,one-stage网络速度要快很多,one-stage网络的准确性低于two-stage网络。
- 为什么?
Two-stage检测分两个阶段进行:(1)首先,模型通过选择搜索或区域提议网络生成一组候选区域。由于潜在的边界框候选可以是无限的,因此所提出的区域是稀疏的。(2)然后分类器仅处理候选区域。
One-stage会跳过区域提议阶段,并直接在可能位置的密集采样上运行检测。这更快更简单,但可能会降低性能。
one-stage 的精度不如 two-stage 的精度,一个主要的原因是训练过程中样本极度不均衡造成的。
目标检测常见概念
目标检测中的 正/负样本:
样本即预测出来的box。Faster R-CNN中的anchor boxes以及SSD中的特征图中的default boxes,这些框中的一部分被选为正样本(正确识别目标),一部分被选为负样本(出现误检),另外一部分被当作背景或者不参与运算。不同的框架有不同的策略,大致筛选策略是根据IOU的值,选取个阈值范围进行判定。two-stage算法会在生成RP阶段保证正:负=1:3,包括YOLO在内的大部分one-stage算法无此环节。比如人脸识别中的例子,正样本很好理解,就是人脸的图片,负样本的选取就与问题场景相关,具体而言,如果你要进行教室中学生的人脸识别,那么负样本就是教室的窗子、墙等等。目标检测中的(样本)类别不平衡问题:
在训练的过程中要特别注意均衡正负样本之间的比例。 因为,因为负样本占比过大会使得模型的参数迭代方向偏离重心,由“把正要样本正确识别为正样本”偏向为“不把负样本误认为正样本”。one-stage目标检测算法在训练时会将所有框(正负样本)投入训练,因此普遍存在类别不平衡的问题。
yolov原理
逐步介绍YOLO v1~v3的设计历程:
yolov1基本思想
* 时间:CVPR 2016(YOLO v1)
* 作者:Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi
* 论文:[You Only Look Once: Unified, Real-Time Object Detection](https://arxiv.org/pdf/1506.02640.pdf)
* 代码:[yolo_tensorflow](https://github.com/hizhangp/yolo_tensorflow)
* 源码分析参考:[YOLO源码解析](https://zhuanlan.zhihu.com/p/25053311)
* 博客参考:[图解YOLO](https://zhuanlan.zhihu.com/p/24916786)
* 网络设计
* 输入shape:448×448×3
* 输出shape:7×7×30
* 卷积层个数:24
* 全连接层个数:2
YOLO(You Only Look Once,YOLO)将输入图像分成SxS个格子,若某个物体 Ground truth 的中心位置的坐标落入到某个格子,那么这个格子就负责检测出这个物体。

每个格子预测B个bounding box及其置信度(confidence score),以及C个类别概率。bbox信息(x,y,w,h)为物体的中心位置相对格子位置的偏移及宽度和高度,均被归一化.置信度反映是否包含物体以及包含物体情况下位置的准确性,定义为:
我们希望预测的置信度和ground truth的IOU相同。每个格子(grid cell)预测条件概率值C()。在测试时,每个box通过类别概率和box置信度相乘来得到特定类别置信度:
网络结构

YOLOv1采用卷积神经网络结构。开始的卷积层提取图像特征,全连接层预测输出概率。借鉴了GoogLeNet分类网络结构。24个卷积层,2个全链接层。(用1×1 reduction layers 紧跟 3×3 convolutional layers 取代Goolenet的 inception modules )。YOLOv1网络在最后使用全连接层进行类别输出,因此全连接层的输出维度是。

- 每个单元格虽然有多个Bounding Box,但是只预测一个类别而不是针对每个Box预测一个类别
- 预测Box,除了x,y,w,h外,还有一个score,如果grid负责预测某个object,score就是预测出来的Box和该object的IoU,如果没有任何object就是0,所以scores其实表征了grid是否含有物体和与物体的重叠度两个概念;在测试的时候,可以直接把score和class probabilities向量相乘作为class-specific confidence sores
训练
- 预训练:作者采用ImageNet 1000-class 数据集来预训练卷积层。预训练阶段,采用图2-2网络中的前20卷积层,外加average-pooling 层和全连接层。模型训练了一周,获得了top-5 accuracy为0.88(ImageNet2012 validation set),与GoogleNet模型准确率相当。训练图像分辨率resize到224x224。
- 将模型转换为检测模型:用步骤1)得到的前20个卷积层网络参数来初始化YOLO模型前20个卷积层的网络参数,向预训练模型中加入了4个卷积层和两层全连接层,提高了模型输入分辨率(224×224->448×448)。顶层预测类别概率和bounding box协调值。bounding box的宽和高通过输入图像宽和高归一化到0-1区间。顶层采用linear activation,其它层使用 leaky rectified linear。作者采用sum-squared error为目标函数来优化,增加bounding box loss权重,减少置信度权重。
作者在PASCAL VOC2007和PASCAL VOC2012数据集上进行了训练和测试。训练135轮,batch size为64,动量为0.9,学习速率延迟为0.0005. Learning schedule为:第一轮,学习速率从0.001缓慢增加到0.01(因为如果初始为高学习速率,会导致模型发散);保持0.01速率到75轮;然后在后30轮中,下降到0.001;最后30轮,学习速率为0.0001.作者还采用了dropout和 data augmentation来预防过拟合。dropout值为0.5;data augmentation包括:random scaling,translation,adjust exposure和saturation。
损失函数
YOLO全部使用了均方和误差作为loss函数.由三部分组成:坐标误差、IOU误差和分类误差。
YOLO在训练过程中Loss计算如下式所示:

其中,为预测值,为训练标记值,表示物体落入格子i的第j个bbox内.如果某个单元格中没有目标,则不对分类误差进行反向传播;B个bbox中与GT具有最高IoU的一个进行坐标误差的反向传播,其余不进行.
损失函数的设计目标就是让坐标(x,y,w,h),confidence,classification 这个三个方面达到很好的平衡。简单的全部采用了平方误差损失(sum-squared error loss)来做这件事会有以下不足:
更重视8维的坐标预测,给这些损失前面赋予更大的loss weight, 记为 ,在pascal VOC训练中取5。
如果一个网格中没有object(一幅图中这种网格很多),那么就会将这些网格中的box的confidence push到0,相比于较少的有object的网格,这种做法是overpowering的,这会导致网络不稳定甚至发散。对没有object的bbox的confidence loss,赋予小的loss weight,记为,在pascal VOC训练中取0.5。有object的bbox的confidence loss 和类别的loss 的loss weight正常取1
-
对不同大小的bbox预测中,相比于大bbox预测偏一点,小box预测偏一点更不能忍受。而平方误差损失(sum-squared error loss)中对同样的偏移loss是一样。作者用了一个比较取巧的办法,就是将box的width和height取平方根代替原本的height和width。 因为small bbox的横轴值较小,发生偏移时,反应到y轴上的loss 比 big box 要大
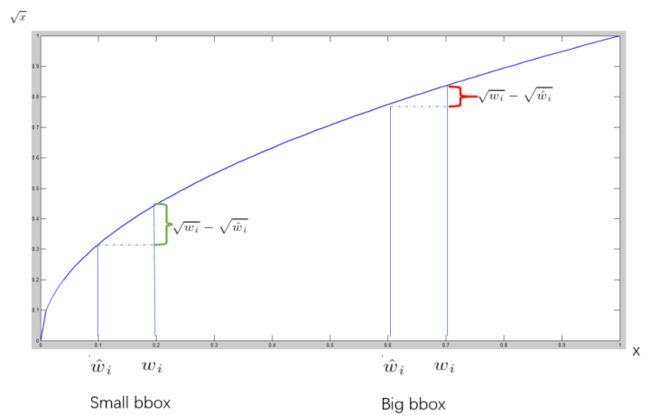 yolov1SumSquareErrorLoss
yolov1SumSquareErrorLoss 一个网格预测多个bounding box,在训练时我们希望每个object(ground true box)只有一个bounding box专门负责(一个object 一个bbox)。具体做法是与ground true box(object)的IOU最大的bounding box 负责该ground true box(object)的预测。
Non-Maximum Suppression就是需要根据score矩阵和region的坐标信息,从中找到置信度比较高的bounding box。对于有重叠在一起的预测框,只保留得分最高的那个。
(1)NMS计算出每一个bounding box的面积,然后根据score进行排序,把score最大的bounding box作为队列中首个要比较的对象;
(2)计算其余bounding box与当前最大score与box的IoU,去除IoU大于设定的阈值的bounding box,保留小的IoU得预测框;
(3)然后重复上面的过程,直至候选bounding box为空。
最终,检测了bounding box的过程中有两个阈值,一个就是IoU,另一个是在过程之后,从候选的bounding box中剔除score小于阈值的bounding box。需要注意的是:Non-Maximum Suppression一次处理一个类别,如果有N个类别,Non-Maximum Suppression就需要执行N次。
预测
-- 设置阈值,滤掉分类置信度得分(class-specific confidence score)得分低的boxes
-- 对于PASCAL VOC数据集,模型需要对每张图片预测98个bounding box和对应的类别。对于大部分目标只包含一个box;其它有些面积大的目标包含了多个boxes,采用了Non-maximal suppression(非最大值抑制)来提高准确率。
缺馅:
一,YOLO的每一个网格只预测两个boxes,一种类别。这导致模型对相邻目标预测准确率下降。因此,YOLO对成队列的目标(如 一群鸟)识别准确率较低。
二,YOLO是从数据中学习预测bounding boxes,因此,对新的或者不常见角度的目标无法识别。
三,YOLO的loss函数对small bounding boxes和large bounding boxes的error平等对待,影响了模型识别准确率。因为对于小的bounding boxes,small error影响更大。
对比
在准确率保证的情况下,YOLO速度快于其它方法。

YOLO定位错误率高于Fast R-CNN;Fast R-CNN背景预测错误率高于YOLO。基于此作者设计了 Fast-R-CNN + YOLO 检测识别模式,即先用R-CNN提取得到一组bounding box,然后用YOLO处理图像也得到一组bounding box。对比这两组bounding box是否基本一致,如果一致就用YOLO计算得到的概率对目标分类,最终的bouding box的区域选取二者的相交区域。这种组合方式将准确率提高了3个百分点。
yolov2基本思想
* [YOLO9000:Better,Faster,Stronger],YOLOv2是Joseph Redmon提出的针对YOLO算法不足的改进版本,作者使用了一系列的方法对原来的YOLO多目标检测框架进行了改进,在保持原有速度的优势之下,相比v1提高了训练图像的分辨率;引入了faster rcnn中anchor box的思想,对网络结构的设计进行了改进,输出层使用卷积层替代YOLO的全连接层,此外作者提出了一种目标分类与检测的联合训练方法,通过这种方法YOLO9000可以同时在COCO和ImageNet数据集中进行训练,训练后的模型可以实现多达9000种物体的实时检测。
* 时间:CVPR 2017(YOLO v2),Arxiv 2018(YOLO v3)
* 作者:Joseph Redmon, Ali Farhadi
* 论文:[YOLO9000: Better, Faster, Stronger](https://arxiv.org/pdf/1612.08242v1.pdf)
* 代码:[yolo_tensorflow](https://github.com/hizhangp/yolo_tensorflow)
* 源码分析参考:[YOLOv2源码分析(c版)](https://blog.csdn.net/qq_17550379/column/info/18380)
* 博客参考
* [YOLO升级版:YOLOv2和YOLO9000解析](https://zhuanlan.zhihu.com/p/25052190)
* [在Python 3中使用YOLOv2](https://www.jianshu.com/p/3e77cefeb49b)
YOLOv2 改进之处
Batch Normalization:v1中也大量用了Batch Normalization,同时在定位层后边用了dropout,v2中取消了dropout,在卷积层全部使用Batch Normalization。
高分辨率分类器:v1中使用224 × 224训练分类器网络,扩大到448用于检测网络。v2将ImageNet以448×448 的分辨率微调最初的分类网络,迭代10 epochs。
网络结构与输入的更改:去掉原来YOLO的一个池化层使得net的分辨率更高,调整了网络的输入(448->416)以使得位置坐标是奇数只有一个中心点(yolo使用pooling来下采样,有5个size=2,stride=2的max pooling,而卷积层没有降低大小,因此最后的特征是416/(2^5)=13).v1中每张图片预测7x7x2=98个box,而v2加上Anchor Boxes能预测超过1000个.检测结果从69.5mAP,81% recall变为69.2 mAP,88% recall.
Anchor Boxes:v1中直接在卷积层之后使用全连接层预测bbox的坐标。v2借鉴Faster R-CNN的思想预测bbox的偏移.移除了全连接层;不再是每个grid预测一个类别而是每个Box预测一个类别,实现解耦;
Dimension Clusters:对Faster R-CNN的手选先验框方法做了改进,采样k-means在训练集bbox上进行聚类产生合适的先验框.由于使用欧氏距离会使较大的bbox比小的bbox产生更大的误差,而IOU与bbox尺寸无关,因此使用IOU参与距离计算,使得通过这些anchor boxes获得好的IOU分值。距离公式:
使用聚类进行选择的优势是达到相同的IOU结果时所需的anchor box数量更少,使得模型的表示能力更强,任务更容易学习.k-means算法代码实现参考:k_means_yolo.py.算法过程是:将每个bbox的宽和高相对整张图片的比例(wr,hr)进行聚类,得到k个anchor box,由于darknet代码需要配置文件中region层的anchors参数是绝对值大小,因此需要将这个比例值乘上卷积层的输出特征的大小.如输入是416x416,那么最后卷积层的特征是13x13.-
Direct location prediction:预测边界框的宽度和高度看起来非常合理,但在实践中,训练会带来不稳定的梯度。所以,现在大部分目标检测器都是预测对数空间(log-space)变换,或者预测与预训练默认边界框(即锚点)之间的偏移,即预测tx ty tw th。
 yolo3regressorbox
yolo3regressorbox- (tx,ty):目标中心点相对于该点所在网格左上角的偏移量,使用 sigmoid 函数进行中心坐标预测。这使得输出值在 0 和 1 之间。如果预测到的 x,y 坐标大于 1,该中心在该单元右下侧的单元中,为了解决这个问题,我们对输出执行 sigmoid 函数,将输出压缩到区间 0 到 1 之间,有效确保中心处于执行预测的网格单元中。
- (cx,cy):该点所在网格的左上角距离最左上角相差的格子数。
- (pw,ph):anchor box 的边长
- (tw,th):预测边框的宽和高
细粒度特征(fine grain features):特征融合,融合了低语义层的信息,来帮助检测小目标物体。在Faster R-CNN 和 SSD 均使用了不同的feature map以适应不同尺度大小的目标.YOLOv2使用了一种不同的方法,简单添加一个 pass through layer,把浅层特征图(26x26)连接到深层特征图(连接到新加入的三个卷积核尺寸为3 * 3的卷积层最后一层的输入)。 通过叠加浅层特征图相邻特征到不同通道(而非空间位置),类似于Resnet中的identity mapping。这个方法把26x26x512的特征图叠加成13x13x2048的特征图,与原生的深层特征图相连接,使模型有了细粒度特征。此方法使得模型的性能获得了1%的提升。
Multi-Scale Training:和YOLOv1训练时网络输入的图像尺寸固定不变不同,YOLOv2网络由于去掉了fc层,因此任意输入维度都可以在整个网络上运行,(在cfg文件中random=1时)每隔几次迭代后就会微调网络的输入尺寸。训练时每迭代10次,就会随机选择新的输入图像尺寸。因为YOLOv2的网络使用的downsamples倍率为32,所以使用32的倍数调整输入图像尺寸{320,352,…,608}。训练使用的最小的图像尺寸为320 x 320,最大的图像尺寸为608 x 608。 这使得网络可以适应多种不同尺度的输入.
YOLOv2网络结构
YOLOv2的神经网络部分使用了一个带跳层的神经网络,具体结构如下所示:

- 输入尺寸变为416 × 416 × 3,识别更高分辨率的图片。
- 每个卷积层后添加了批标准化层,加速了网络的收敛。
- (跳层)在第16层开始分为两条路径,将低层的特征直接连接到高层,可提高模型性能。
- 移除全连接层,使用卷积层预测框的偏移量,最终的输出向量中保存了原来的位置信息。
训练
神经网络部分基于模型Darknet-19,该模型的训练部分分为两个部分:预训练和训练部分
a)预训练:预训练是在ImageNet上按分类的方式进行预训练160轮,使用SGD优化方法,初始学习率0.1,每次下降4倍,到0.0005时终止。除了训练224x224尺寸的图像外,还是用448x448尺寸的图片。
b)训练:去除Darknet的最后一个卷积层,并将网络结构修改为YOLOv2的网络,在VOC数据集上进行训练。训练使用的代价函数是MSE代价函数。
在训练过程中,还引入了多尺寸训练,由于网络删除了全连接层,所以该网络并不关心图片的具体大小,训练时使用320~608尺寸的图像{320,352,….,608}。使用Darknet框架在ImageNet 1000类上训练160 epochs,学习率初始为0.1,以4级多项式衰减.weight decay=0.0005 , momentum=0.9.使用标准的数据增广方法:random crops, rotations, (hue, saturation), exposure shifts.
#Darknet训练VOC的参数如下:
learning_rate=0.0001
batch=64
max_batches = 45000 # 最大迭代batch数
policy=steps # 学习率衰减策略
steps=100,25000,35000 # 训练到这些batch次数时learning_rate按scale缩放
scales=10,.1,.1 # 与steps对应
检测规则
YOLOv2使用了Anchor Box的方法,神经网络输出的向量尺寸是13 × 13 × 125,其中13 × 13是将图片划分为13行和13列共169个cell,每个cell预测125个数据。对于每个cell的125个数据,分解为125 = 5 × (5+20),即每个cell包括5个anchor box(预测框),每个anchor box(预测框)包括25个数据,分别为物体存在置信度,物体中心位置(x,y),物体尺寸(w,h)和类别信息(20个)。如下图所示:
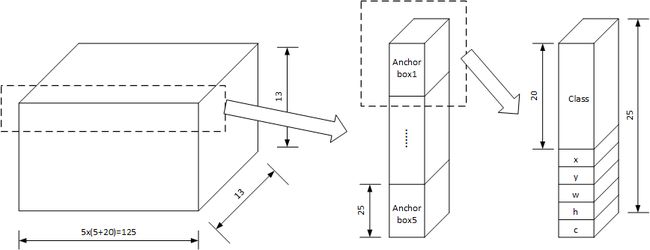
- 对于每个cell包括5个anchor box信息,每个anchor box包括25个数据,分别:
为是否有物品(1个):表示位于第i,j的cell中第K个anchor box中有物品的置信度(标签值为cell预测框与gtbox进行IOU的值)
-
物品位置(4个):物品位置(x,y,w,h)与物品位置中心点和尺寸的关系:
其中,为网络为边界框anchor box预测4个坐标,为单元格从图像的左上角偏移,为之前的边界框anchor box具有宽度和高度
物体种类(20个):softmax计算每一种物体的概率值
每个cell预测5个anchor box,这5个anchor box有不同的预设尺寸,该预设尺寸可以手动指定也可以在训练集上训练获得。在YOLOv2中,预设尺寸是通过在测试集上进行类聚获得的。
添加跨层跳跃连接(借鉴ResNet等思想),融合粗细粒度的特征:将前面最后一个3x3x512卷积的特征图,对于416x416的输入,该层输出26x26x512,直接连接到最后新加的三个3x3卷积层的最后一个的前边.将26x26x512变形为13x13x1024与后边的13x13x1024特征按channel堆起来得到13x13x3072.从yolo-voc.cfg文件可以看到,第25层为route层,逆向9层拿到第16层26 * 26 * 512的输出,并由第26层的reorg层把26 * 26 * 512 变形为13 * 13 * 2048,再有第27层的route层连接24层和26层的输出,堆叠为13 * 13 * 3072,由最后一个卷积核为3 * 3的卷积层进行跨通道的信息融合并把通道降维为1024。
yolov3网络框架
* YOLOv3在YOLOv2的基础进行了一些改进,这些更改使其效果变得更好。 在320×320的图像上,YOLOv3运行速度达到了22.2毫秒,mAP为28.2。其与SSD一样准确,但速度快了三倍
* 时间:Arxiv 2018(YOLO v3)
* 作者:Joseph Redmon, Ali Farhadi
* 论文:[YOLOv3: An Incremental Improvement](https://pjreddie.com/media/files/papers/YOLOv3.pdf)
* 代码:
* [darknet](https://github.com/pjreddie/darknet)
* [keras-yolo3](https://github.com/qqwweee/keras-yolo3])
* [tensorflow-yolov3](https://github.com/YunYang1994/tensorflow-yolov3)
* 官网:[darknet](https://pjreddie.com/darknet/yolo/)
* 源码分析参考:[YOLO v3源码解读](https://luckmoonlight.github.io/2018/12/04/yolov3SourceCode/)
* 博客参考
* [YOLOv3论文中文解读](https://zhuanlan.zhihu.com/p/34945787)
* [yolo系列之yolo v3【深度解析】](https://blog.csdn.net/leviopku/article/details/82660381)
* 相关博客
* [知乎-计算机视觉论文速递](https://zhuanlan.zhihu.com/c_172507674)
* [YOLO-LITE](https://zhuanlan.zhihu.com/p/50170492)
YOLOv3 改进之处
- 网络结构改变:网络的结构由Darknet-19变为Darknet-53,跳层的现象越来越普遍。
- 多尺度预测:输出3层,每层 S × S个网格,分别为 13×13 ,26 ×26 ,52×52
- 小尺度:(13×13的feature map)网络接收一张(416×416)的图,经过5个步长为2的卷积来进行降采样(416 / 2ˆ5 = 13),输出(13×13×512),再经过7个卷积得到第一个特征图谱,在这个特征图谱上做第一次预测。
- 中尺度: (26×26的feature map)从小尺度中从后向前获得倒数第3个卷积层的输出,进行一次卷积一次x2上采样,将上采样特征(26×26×256)与第43个卷积特征(26×26×512)连接,输出(26×26×728),经过7个卷积得到第二个特征图谱(26×26×255),在这个特征图谱上做第二次预测。
- 大尺度:(52×52的feature map)操作同中尺度,从后向前获得倒数第3个卷积层的输出,进行一次卷积一次x2上采样,将上采样特征与第26个卷积特征连接,经过7个卷积得到第三个特征图谱,在这个特征图谱上做第三次预测。输出(52×52×255)
- 好处:让网络同时学习到深层和浅层的特征,通过叠加浅层特征图特征到相邻通道,类似于FPN中的umsample+concat。这个方法把26x26x512的特征图叠加13x13x256的特征图,使模型有了细粒度特征,增加对小目标的识别能力
- anchor box:yolov3 anchor box一共有9个,由k-means聚类得到。不同尺寸特征图对应不同大小的先验框
 特征图与先验框
特征图与先验框
感受一下9种先验框的尺寸,下图中蓝色框为聚类得到的先验框。黄色框式ground truth,红框是对象中心点所在的网格。
* 13×13尺度的anchor box【(116×90),(156×198),(373×326)】
* 26×26尺度的anchor box【(30×61),(62×45),(59×119)】
* 52×52尺度的anchor box【(10×13),(16×30),(33×23)】
* 原因: (越精细的grid cell就可以检测出越精细的物体)尺度越大,感受野越小,对小物体越敏感,所以选择小的anchor box
- 输入到输出映射
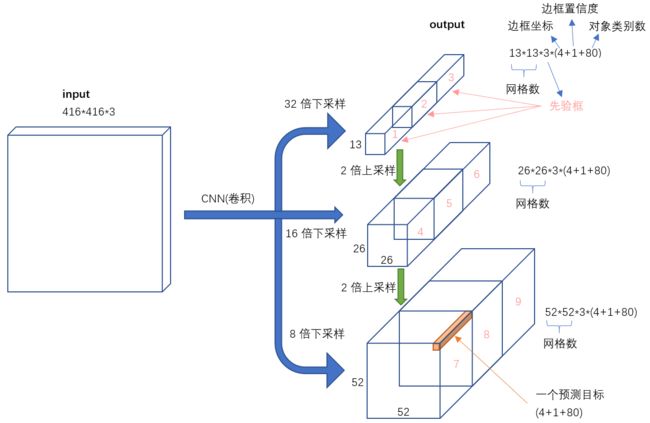 输入->输出
输入->输出
不考虑神经网络结构细节的话,总的来说,对于一个输入图像,YOLO3将其映射到3个尺度的输出张量,代表图像各个位置存在各种对象的概率。
我们看一下YOLO3共进行了多少个预测。对于一个416416的输入图像,在每个尺度的特征图的每个网格设置3个先验框,总共有 13133 + 26263 + 5252*3 = 10647 个预测。每一个预测是一个(4+1+80)=85维向量,这个85维向量包含边框坐标(4个数值),边框置信度(1个数值),对象类别的概率(对于COCO数据集,有80种对象)。
对比一下,YOLO2采用13135 = 845个预测,YOLO3的尝试预测边框数量增加了10多倍,而且是在不同分辨率上进行,所以mAP以及对小物体的检测效果有一定的提升。
* PS:最终得到的边框坐标值是bx,by,bw,bh.而网络学习目标是tx,ty,tw,th
- 损失函数LOSS:YOLO V3把YOLOV2中的Softmax loss变成Logistic loss。这样能够支持多标签对象(比如一个人有Woman 和 Person两个标签)。
网络结构
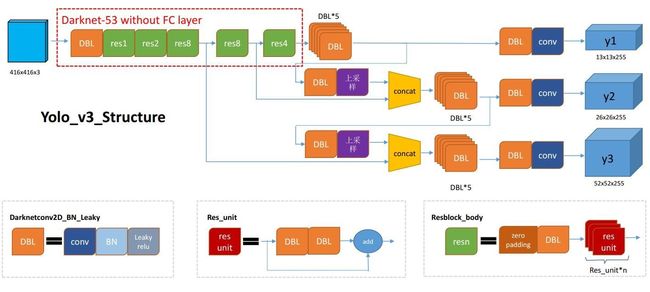
YOLO3采用了称之为Darknet-53的网络结构(含有53个卷积层)。

上图的Darknet-53网络采用256 2563作为输入,最左侧那一列的1、2、8等数字表示多少个重复的残差组件。每个残差组件有两个卷积层和一个快捷链路,示意图如下:

目标检测算法比较
YOLO3借鉴了残差网络结构,形成更深的网络层次,以及多尺度检测,提升了mAP及小物体检测效果。如果采用COCO mAP50做评估指标(不是太介意预测框的准确性的话),YOLO3的表现相当惊人,如下图所示,在精确度相当的情况下,YOLOv3的速度是其它模型的3、4倍。
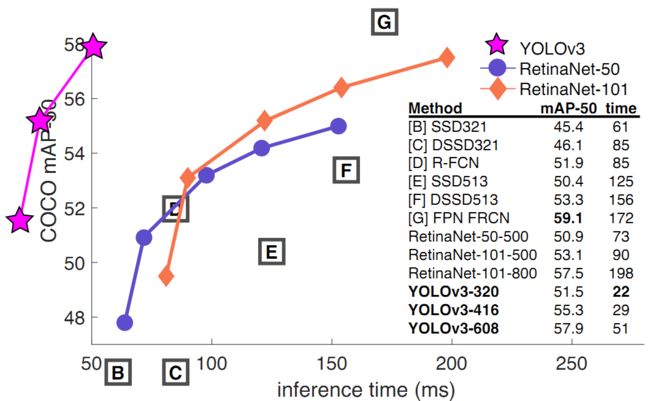
不过如果要求更精准的预测边框,采用COCO AP做评估标准的话,YOLO3在精确率上的表现就弱了一些。如下图所示。
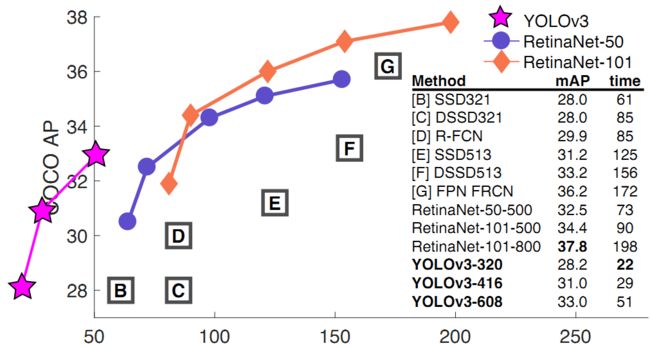
训练自己的数据集
本文介绍在darknet框架下训练yolov3网络, darknet官网地址:https://pjreddie.com/darknet/yolo/
构造自己的数据集
数据集存储目录
#目录格式
- VOCdevkit
- VOC×××
- Annotations #储存xml
- ImageSets #储存训练文本信息
- Main
- test.txt
- train.txt
- trainval.txt
- val.txt
- JPEGImages #储存图片,不支持png格式
- labels #储存标签信息
将图片保存在'JPEGImages'文件夹下,然后使用标注软件(这里使用labelImg软件)标注图片,并将标注信息保存在'Annotations'文件夹下。
labelImg标注图片
- 安装labelImg
#系统为Ubuntu,Python版本不同,安装方式也不同。
#Python 2 + Qt4
sudo apt-get install pyqt4-dev-tools
sudo pip install lxml
git clone https://github.com/tzutalin/labelImg.git
cd labelImg
make all
python labelImg.py #打开labelImg
python labelImg.py [IMAGE_PATH] [PRE-DEFINED CLASS FILE]
#Python 3 + Qt5
sudo apt-get install pyqt5-dev-tools
sudo pip3 install lxml
git clone https://github.com/tzutalin/labelImg.git
cd labelImg
make all
python3 labelImg.py #打开labelImg
python3 labelImg.py [IMAGE_PATH] [PRE-DEFINED CLASS FILE]
使用labelImg
Open:导入单张图片。
Open Dir:打开文件夹目录,用Next Image(快捷键:A)和Prev Image(快捷键:D)查看所有图片。
Change Save Dir:更改xml文件保存的路径。
Verify Image:更改xml文件的内容。
Save(快捷键:Ctrl+S):保存xml文件。
Create\nRectBox(快捷键:W):新建标注框-
xml解释
 xml解释
xml解释 分配训练数据
python test_eval.py
test_eval.py文件
import os
if __name__ == '__main__':
path = os.getcwd()
dataAnnotated = os.listdir(path + '/Annotations')
dataNum = len(dataAnnotated) # 数据集数量
ftest = open('ImageSets/Main/test.txt', 'w') # 测试集
ftrain = open('ImageSets/Main/train.txt', 'w') # 训练集
ftrainval = open('ImageSets/Main/trainval.txt', 'w') # 训练验证集
fval = open('ImageSets/Main/val.txt', 'w') # 验证集
testScale = 0.1 # 测试集占总数据集的比例
trainScale = 0.9 # 训练集占训练验证集的比例
i = 1
testNum = int(dataNum * testScale) # 测试集的数量
trainNum = int((dataNum - testNum) * trainScale) # 训练集的数量
for name in dataAnnotated:
if i <= testNum:
ftest.write(name[0:6]+'\n')
elif i <= testNum + trainNum:
ftrain.write(name[0:6]+'\n')
ftrainval.write(name[0:6]+'\n')
else:
fval.write(name[0:6]+'\n')
ftrainval.write(name[0:6]+'\n')
i += 1
ftrain.close()
ftrainval.close()
fval.close()
ftest.close()
- 生成label文件
python voc_label.py
voc_label.py文件
import os
import pickle
import xml.etree.ElementTree as ET
from os import listdir, getcwd
from os.path import join
from PIL import Image
# Imageset目录
sets = [('×××', 'train'), ('×××', 'val'), ('×××', 'test')]
#类型名称
classes = ["××1", "××2"]
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(year, image_id):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml' % (year, image_id))
out_file = open('VOCdevkit/VOC%s/labels/%s.txt' % (year, image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
if w == 0 or h == 0:
image = Image.open('VOCdevkit/VOC%s/JPEGImages/%s.jpg' % (year, image_id))
image_size = image.size
w = image_size[0]
h = image_size[1]
size_w = size.find('width')
size_h = size.find('height')
# a = ET.SubElement(size_w, 'width')
# b = ET.SubElement(size_h, 'height')
size_w.text = str(w)
size_h.text = str(h)
tree.write('VOCdevkit/VOC%s/Annotations/%s.xml' % (year, image_id))
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/' % (year)):
os.makedirs('VOCdevkit/VOC%s/labels/' % (year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt' % (year, image_set)).read().strip().split()
list_file = open('%s_%s.txt' % (year, image_set), 'w')
for image_id in image_ids:
print(image_id)
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n' % (wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
开始训练
下载模型
git clone https://github.com/pjreddie/darknet
cd darknet
配置GPU
- 修改Makefile文件配置
vim Makefile
Darknet在GPU上运行可以得到500倍的提速,编译使用GPU要求显卡是Nvidia卡并且正确安装了CUDA。
#1.更改Makefile前两行GPU和CUDNN的配置
GPU=1
CUDNN=1
#2.更改CUDA的路径
#48~51行,在"ifeq ($(GPU), 1)"语句块中修改为自己的CUDA安装路径
#23行,修改NVCC的路径:
ifeq ($(GPU), 1)
COMMON+= -DGPU -I/usr/local/cuda-8.0/include/
CFLAGS+= -DGPU
LDFLAGS+= -L/usr/local/cuda-8.0/lib64 -lcuda -lcudart -lcublas -lcurand
NVCC=/usr/local/cuda-8.0/bin/nvcc
#3.修改ARCH配置
"""
如果经过1和2的配置修改后编译的darknet运行可能会报以下错误:
Loadingweights from yolo.weights...Done!
CUDA Error:invalid device function
darknet: ./src/cuda.c:21: check_error: Assertion `0' failed.
Aborted (core dumped)
这是因为配置文件Makefile中配置的GPU架构和本机GPU型号不一致导致的。
更改前默认配置如下(不同版本可能有变):
ARCH= -gencode arch=compute_30,code=sm_30 \
-gencode arch=compute_35,code=sm_35 \
-gencode arch=compute_50,code=[sm_50,compute_50] \
-gencode arch=compute_52,code=[sm_52,compute_52]
# -gencode arch=compute_20,code=[sm_20,sm_21] \ This one is deprecated?
# This is what I use, uncomment if you know your arch and want to specify
# ARCH= -gencode arch=compute_52,code=compute_52
compute_30表示显卡的计算能力是3.0,几款主流GPU的compute capability列表:
GTX Titan x : 5.2
GTX 980 : 5.2
Tesla K80 : 3.7
Tesla K40 : 3.5
K4200 : 3.0
所以Tesla K80对应compute_30,Tesla K40c对应compute_35,Titan X对应compute_52,根据自己的GPU型号的计算能力进行配置,例如配置为:
"""
ARCH= -gencode arch=compute_35,code=compute_35 \
- 编译
make
- 若前面的路径错误或GPU算力不匹配都会报错,在服务器上跑的话将Makefile中的opencv置0,否则报错。
- 修改Makefile需要重新make,修改config.cfg不需要make
下载预训练模型
在darknet目录下
wget https://pjreddie.com/media/files/yolov3.weights
./darknet detector test cfg/coco.data cfg/yolov3.cfg yolov3.weights data/dog.jpg
若demo运行成功,则说明没问题。
修改配置文件
- 修改cfg/yolov3.cfg文件
[net] ★ [xxx]开始的行表示网络的一层,其后的内容为该层的参数配置,[net]为特殊的层,配置整个网络
# Testing ★ #号开头的行为注释行,在解析cfg的文件时会忽略该行
# batch=1
# subdivisions=1
# Training
batch=64 ★ 这儿batch与机器学习中的batch有少许差别,仅表示网络积累多少个样本后进行一次BP
subdivisions=16 ★ 这个参数表示将一个batch的图片分sub次完成网络的前向传播
★★ 敲黑板:在Darknet中,batch和sub是结合使用的,例如这儿的batch=64,sub=16表示训练的过
程中将一次性加载64张图片进内存,然后分16次完成前向传播,意思是每次4张,前向传播的循环过程中
累加loss求平均,待64张图片都完成前向传播后,再一次性后传更新参数
★★★ 调参经验:sub一般设置16,不能太大或太小,且为8的倍数,其实也没啥硬性规定,看着舒服就好
batch的值可以根据显存占用情况动态调整,一次性加减sub大小即可,通常情况下batch越大越好,还需
注意一点,在测试的时候batch和sub都设置为1,避免发生神秘错误!
width=608 ★ 网络输入的宽width
height=608 ★ 网络输入的高height
channels=3 ★ 网络输入的通道数channels
★★★ width和height一定要为32的倍数,否则不能加载网络
★ 提示:width也可以设置为不等于height,通常情况下,width和height的值越大,对于小目标的识别
效果越好,但受到了显存的限制,读者可以自行尝试不同组合
momentum=0.9 ★ 动量 DeepLearning1中最优化方法中的动量参数,这个值影响着梯度下降到最优值得速度
decay=0.0005 ★ 权重衰减正则项,防止过拟合
angle=0 ★ 数据增强参数,通过旋转角度来生成更多训练样本
saturation = 1.5 ★ 数据增强参数,通过调整饱和度来生成更多训练样本
exposure = 1.5 ★ 数据增强参数,通过调整曝光量来生成更多训练样本
hue=.1 ★ 数据增强参数,通过调整色调来生成更多训练样本
learning_rate=0.001 ★ 学习率决定着权值更新的速度,设置得太大会使结果超过最优值,太小会使下降速度过慢。
如果仅靠人为干预调整参数,需要不断修改学习率。刚开始训练时可以将学习率设置的高一点,
而一定轮数之后,将其减小在训练过程中,一般根据训练轮数设置动态变化的学习率。
刚开始训练时:学习率以 0.01 ~ 0.001 为宜。一定轮数过后:逐渐减缓。
接近训练结束:学习速率的衰减应该在100倍以上。
学习率的调整参考https://blog.csdn.net/qq_33485434/article/details/80452941
★★★ 学习率调整一定不要太死,实际训练过程中根据loss的变化和其他指标动态调整,手动ctrl+c结
束此次训练后,修改学习率,再加载刚才保存的模型继续训练即可完成手动调参,调整的依据是根据训练
日志来,如果loss波动太大,说明学习率过大,适当减小,变为1/5,1/10均可,如果loss几乎不变,
可能网络已经收敛或者陷入了局部极小,此时可以适当增大学习率,注意每次调整学习率后一定要训练久
一点,充分观察,调参是个细活,慢慢琢磨
★★ 一点小说明:实际学习率与GPU的个数有关,例如你的学习率设置为0.001,如果你有4块GPU,那
真实学习率为0.001/4
burn_in=1000 ★ 在迭代次数小于burn_in时,其学习率的更新有一种方式,大于burn_in时,才采用policy的更新方式
max_batches = 500200 ★ 训练次数达到max_batches后停止学习,一次为跑完一个batch
policy=steps ★ 学习率调整的策略:constant, steps, exp, poly, step, sig, RANDOM,constant等方式
参考https://nanfei.ink/2018/01/23/YOLOv2%E8%B0%83%E5%8F%82%E6%80%BB%E7%BB%93/#more
steps=400000,450000
scales=.1,.1 ★ steps和scale是设置学习率的变化,比如迭代到400000次时,学习率衰减十倍,45000次迭代时,学
习率又会在前一个学习率的基础上衰减十倍
[convolutional] ★ 一层卷积层的配置说明
batch_normalize=1 ★ 是否进行BN处理,什么是BN此处不赘述,1为是,0为不是
filters=32 ★ 卷积核个数,也是输出通道数
size=3 ★ 卷积核尺寸
stride=1 ★ 卷积步长
pad=1 ★ 卷积时是否进行0 padding,padding的个数与卷积核尺寸有关,为size/2向下取整,如3/2=1
activation=leaky ★ 网络层激活函数
★★ 卷积核尺寸3*3配合padding且步长为1时,不改变feature map的大小
# Downsample
[convolutional] ★ 下采样层的配置说明
batch_normalize=1
filters=64
size=3
stride=2
pad=1
activation=leaky ★★ 卷积核尺寸为3*3,配合padding且步长为2时,feature map变为原来的一半大小
[shortcut] ★ shotcut层配置说明
from=-3 ★ 与前面的多少次进行融合,-3表示前面第三层
activation=linear ★ 层次激活函数
......
......
[convolutional] ★ YOLO层前面一层卷积层配置说明
size=1
stride=1
pad=1
filters=255 ★ filters=num(预测框个数)*(classes+5),5的意义是4个坐标加一个置信率,论文中的tx,ty,tw,th,
c,classes为类别数,COCO为80,num表示YOLO中每个cell预测的框的个数,YOLOV3中为3
★★★ 自己使用时,此处的值一定要根据自己的数据集进行更改,例如你识别4个类,则:
filters=3*(4+5)=27,三个fileters都需要修改,切记
activation=linear
[yolo] ★ YOLO层配置说明
mask = 0,1,2 ★ 使用anchor的索引,0,1,2表示使用下面定义的anchors中的前三个anchor
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=80 ★ 类别数目
num=9 ★ 每个grid cell总共预测几个box,和anchors的数量一致。当想要使用更多anchors时需要调大num
jitter=.3 ★ 数据增强手段,此处jitter为随机调整宽高比的范围,该参数不好理解,在我的源代码注释中有详细说明
ignore_thresh = .7
truth_thresh = 1 ★ 参与计算的IOU阈值大小.当预测的检测框与ground true的IOU大于ignore_thresh的时候,参与
loss的计算,否则,检测框的不参与损失计算。
★ 理解:目的是控制参与loss计算的检测框的规模,当ignore_thresh过于大,接近于1的时候,那么参与
检测框回归loss的个数就会比较少,同时也容易造成过拟合;而如果ignore_thresh设置的过于小,那么
参与计算的会数量规模就会很大。同时也容易在进行检测框回归的时候造成欠拟合。
★ 参数设置:一般选取0.5-0.7之间的一个值,之前的计算基础都是小尺度(13*13)用的是0.7,
(26*26)用的是0.5。这次先将0.5更改为0.7。参考:https://www.e-learn.cn/content/qita/804953
random=1 ★ 为1打开随机多尺度训练,为0则关闭
★★ 提示:当打开随机多尺度训练时,前面设置的网络输入尺寸width和height其实就不起作用了,width
会在320到608之间随机取值,且width=height,没10轮随机改变一次,一般建议可以根据自己需要修改
随机尺度训练的范围,这样可以增大batch,望读者自行尝试!
- 修改cfg/voc.data文件
classes= 2 #你的数据及类别
train = .../VOCdevkit/VOC×××/ImageSets/Main/train.txt #产生的train.txt文件路径
valid = .../VOCdevkit/VOC×××/ImageSets/Main/val.txt #生成的val.txt文件路径
names = data/voc.names
backup = backup
- 修改data/voc.names文件
man #自己的数据集标签
woman
darknet命令
#训练模型(将log信息打印到nohuo.out中,并后台运行)
nohup ./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74 &
#继续训练
nohup ./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg backup/yolov3.backup &
#单张图片测试
./darknet detector test cfg/voc.data cfg/yolov3.cfg backup/yolov3.weights img_abs_path
训练log中各参数的意义
- log示例

- 关键参数为:IOU .5R .75R Loss Avg loss rate

训练结果
评价指标
准确率 (Accuracy),混淆矩阵 (Confusion Matrix),精确率(Precision),召回率(Recall),平均正确率(AP),mean Average Precision(mAP),交除并(IoU),ROC + AUC
1、准确率 (Accuracy)
分对的样本数除以所有的样本数 ,即:准确(分类)率 = 正确预测的正反例数 / 总数。
准确率一般用来评估模型的全局准确程度,不能包含太多信息,无法全面评价一个模型性能。
2、混淆矩阵 (Confusion Matrix)
混淆矩阵中的横轴是模型预测的类别数量统计,纵轴是数据真实标签的数量统计。
对角线,表示模型预测和数据标签一致的数目,所以对角线之和除以测试集总数就是准确率。对角线上数字越大越好,在可视化结果中颜色越深,说明模型在该类的预测准确率越高。如果按行来看,每行不在对角线位置的就是错误预测的类别。总的来说,我们希望对角线越高越好,非对角线越低越好。
3、精确率(Precision)与召回率(Recall)

一些相关的定义。假设现在有这样一个测试集,测试集中的图片只由大雁和飞机两种图片组成,假设你的分类系统最终的目的是:能取出测试集中所有飞机的图片,而不是大雁的图片。
- True positives : 正样本被正确识别为正样本,飞机的图片被正确的识别成了飞机。
- True negatives: 负样本被正确识别为负样本,大雁的图片没有被识别出来,系统正确地认为它们是大雁。
- False positives: 假的正样本,即负样本被错误识别为正样本,大雁的图片被错误地识别成了飞机。
- False negatives: 假的负样本,即正样本被错误识别为负样本,飞机的图片没有被识别出来,系统错误地认为它们是大雁。
Precision其实就是在识别出来的图片中,True positives所占的比率。也就是本假设中,所有被识别出来的飞机中,真正的飞机所占的比例。

Recall 是测试集中所有正样本样例中,被正确识别为正样本的比例。也就是本假设中,被正确识别出来的飞机个数与测试集中所有真实飞机的个数的比值。

Precision-recall 曲线:改变识别阈值,使得系统依次能够识别前K张图片,阈值的变化同时会导致Precision与Recall值发生变化,从而得到曲线。
如果一个分类器的性能比较好,那么它应该有如下的表现:在Recall值增长的同时,Precision的值保持在一个很高的水平。而性能比较差的分类器可能会损失很多Precision值才能换来Recall值的提高。通常情况下,文章中都会使用Precision-recall曲线,来显示出分类器在Precision与Recall之间的权衡。
4、平均精度(Average-Precision,AP)与 ****mean Average Precision(mAP)
AP就是Precision-recall 曲线下面的面积,通常来说一个越好的分类器,AP值越高。
mAP是多个类别AP的平均值。这个mean的意思是对每个类的AP再求平均,得到的就是mAP的值,mAP的大小一定在[0,1]区间,越大越好。该指标是目标检测算法中最重要的一个。
在正样本非常少的情况下,PR表现的效果会更好。

5、IoU
IoU这一值,可以理解为系统预测出来的框与原来图片中标记的框的重合程度。 计算方法即检测结果Detection Result与 Ground Truth 的交集比上它们的并集,即为检测的准确率。
IOU正是表达这种bounding box和groundtruth的差异的指标:

6、ROC(Receiver Operating Characteristic)曲线与AUC(Area Under Curve)
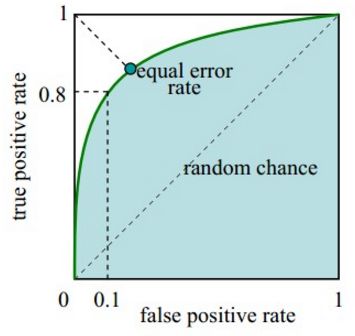
ROC曲线:
- 横坐标:假正率(False positive rate, FPR),FPR = FP / [ FP + TN] ,代表所有负样本中错误预测为正样本的概率,假警报率;
- 纵坐标:真正率(True positive rate, TPR),TPR = TP / [ TP + FN] ,代表所有正样本中预测正确的概率,命中率。
对角线对应于随机猜测模型,而(0,1)对应于所有整理排在所有反例之前的理想模型。曲线越接近左上角,分类器的性能越好。
ROC曲线有个很好的特性:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化。
- ROC曲线绘制:
(1)根据每个测试样本属于正样本的概率值从大到小排序;
(2)从高到低,依次将“Score”值作为阈值threshold,当测试样本属于正样本的概率大于或等于这个threshold时,我们认为它为正样本,否则为负样本;
(3)每次选取一个不同的threshold,我们就可以得到一组FPR和TPR,即ROC曲线上的一点。
当我们将threshold设置为1和0时,分别可以得到ROC曲线上的(0,0)和(1,1)两个点。将这些(FPR,TPR)对连接起来,就得到了ROC曲线。当threshold取值越多,ROC曲线越平滑。
AUC(Area Under Curve)即为ROC曲线下的面积。AUC越接近于1,分类器性能越好。
物理意义:首先AUC值是一个概率值,当你随机挑选一个正样本以及一个负样本,当前的分类算法根据计算得到的Score值将这个正样本排在负样本前面的概率就是AUC值。当然,AUC值越大,当前的分类算法越有可能将正样本排在负样本前面,即能够更好的分类。
计算公式:就是求曲线下矩形面积。

7、PR曲线和ROC曲线比较
- ROC曲线特点:
(1)优点:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。因为TPR聚焦于正例,FPR聚焦于与负例,使其成为一个比较均衡的评估方法。在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化。
(2)缺点:上文提到ROC曲线的优点是不会随着类别分布的改变而改变,但这在某种程度上也是其缺点。因为负例N增加了很多,而曲线却没变,这等于产生了大量FP。像信息检索中如果主要关心正例的预测准确性的话,这就不可接受了。在类别不平衡的背景下,负例的数目众多致使FPR的增长不明显,导致ROC曲线呈现一个过分乐观的效果估计。ROC曲线的横轴采用FPR,根据FPR ,当负例N的数量远超正例P时,FP的大幅增长只能换来FPR的微小改变。结果是虽然大量负例被错判成正例,在ROC曲线上却无法直观地看出来。(当然也可以只分析ROC曲线左边一小段) - PR曲线:
(1)PR曲线使用了Precision,因此PR曲线的两个指标都聚焦于正例。类别不平衡问题中由于主要关心正例,所以在此情况下PR曲线被广泛认为优于ROC曲线。
8、使用场景
- ROC曲线由于兼顾正例与负例,所以适用于评估分类器的整体性能,相比而言PR曲线完全聚焦于正例。
- 如果有多份数据且存在不同的类别分布,比如信用卡欺诈问题中每个月正例和负例的比例可能都不相同,这时候如果只想单纯地比较分类器的性能且剔除类别分布改变的影响,则ROC曲线比较适合,因为类别分布改变可能使得PR曲线发生变化时好时坏,这种时候难以进行模型比较;反之,如果想测试不同类别分布下对分类器的性能的影响,则PR曲线比较适合。
- 如果想要评估在相同的类别分布下正例的预测情况,则宜选PR曲线。
- 类别不平衡问题中,ROC曲线通常会给出一个乐观的效果估计,所以大部分时候还是PR曲线更好。
- 最后可以根据具体的应用,在曲线上找到最优的点,得到相对应的precision,recall,f1 score等指标,去调整模型的阈值,从而得到一个符合具体应用的模型。
批量化测试图片
- step1:修改darknet/examples目录下的detector.c文件
\\在文件开头添加*GetFilename(char *p)函数如下:
#include "darknet.h"
static int coco_ids[] = {1,2,3,4,5,6,7,8,9,10,11,13,14,15,16,17,18,19,20,21,22,23,24,25,27,28,31,32,33,34,35,36,37,38,39,40,41,42,43,44,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,67,70,72,73,74,75,76,77,78,79,80,81,82,84,85,86,87,88,89,90};
char *GetFilename(char *p) //此函数为在原文件中新加的
{
static char name[20]={""};
char *q = strrchr(p,'/') + 1;
strncpy(name,q,6);//注意后面的6,如果你的测试集的图片的名字字符(不包括后缀)是其他长度,请改为你需要的长度(官方的默认的长度是6)
return name;
}
- step2:修改detector.c的test_detector函数
void test_detector(char *datacfg, char *cfgfile, char *weightfile, char *filename, float thresh, float hier_thresh, char *outfile, int fullscreen)
{
list *options = read_data_cfg(datacfg);
char *name_list = option_find_str(options, "names", "data/names.list");
char **names = get_labels(name_list);
image **alphabet = load_alphabet();
network *net = load_network(cfgfile, weightfile, 0);
set_batch_network(net, 1);
srand(2222222);
double time;
char buff[256];
char *input = buff;
float nms=.45;
int i=0;
while(1){
if(filename){
strncpy(input, filename, 256);
image im = load_image_color(input,0,0);
image sized = letterbox_image(im, net->w, net->h);
//image sized = resize_image(im, net->w, net->h);
//image sized2 = resize_max(im, net->w);
//image sized = crop_image(sized2, -((net->w - sized2.w)/2), -((net->h - sized2.h)/2), net->w, net->h);
//resize_network(net, sized.w, sized.h);
layer l = net->layers[net->n-1];
float *X = sized.data;
time=what_time_is_it_now();
network_predict(net, X);
printf("%s: Predicted in %f seconds.\n", input, what_time_is_it_now()-time);
int nboxes = 0;
detection *dets = get_network_boxes(net, im.w, im.h, thresh, hier_thresh, 0, 1, &nboxes);
//printf("%d\n", nboxes);
//if (nms) do_nms_obj(boxes, probs, l.w*l.h*l.n, l.classes, nms);
if (nms) do_nms_sort(dets, nboxes, l.classes, nms);
draw_detections(im, dets, nboxes, thresh, names, alphabet, l.classes);
free_detections(dets, nboxes);
if(outfile)
{
save_image(im, outfile);
}
else{
save_image(im, "predictions");
#ifdef OPENCV
//cvNamedWindow("predictions", CV_WINDOW_NORMAL);
//if(fullscreen){
//cvSetWindowProperty("predictions", CV_WND_PROP_FULLSCREEN, CV_WINDOW_FULLSCREEN);
// }
// show_image(im, "predictions");
// cvWaitKey(0);
// cvDestroyAllWindows();
#endif
}
free_image(im);
free_image(sized);
if (filename) break;
}
else {
printf("Enter Image Path: ");
fflush(stdout);
input = fgets(input, 256, stdin);
if(!input) return;
strtok(input, "\n");
list *plist = get_paths(input);
char **paths = (char **)list_to_array(plist);
printf("Start Testing!\n");
int m = plist->size;
if(access("/home/pxt/darknet/data/out",0)==-1)//"/home/FENGsl/darknet/data"修改成自己的路径
{
if (mkdir("/home/pxt/darknet/data/out",0777))//"/home/FENGsl/darknet/data"修改成自己的路径
{
printf("creat file bag failed!!!");
}
}
for(i = 0; i < m; ++i){
char *path = paths[i];
image im = load_image_color(path,0,0);
image sized = letterbox_image(im, net->w, net->h);
//image sized = resize_image(im, net->w, net->h);
//image sized2 = resize_max(im, net->w);
//image sized = crop_image(sized2, -((net->w - sized2.w)/2), -((net->h - sized2.h)/2), net->w, net->h);
//resize_network(net, sized.w, sized.h);
layer l = net->layers[net->n-1];
float *X = sized.data;
time=what_time_is_it_now();
network_predict(net, X);
printf("Try Very Hard:");
printf("%s: Predicted in %f seconds.\n", path, what_time_is_it_now()-time);
int nboxes = 0;
detection *dets = get_network_boxes(net, im.w, im.h, thresh, hier_thresh, 0, 1, &nboxes);
//printf("%d\n", nboxes);
//if (nms) do_nms_obj(boxes, probs, l.w*l.h*l.n, l.classes, nms);
if (nms) do_nms_sort(dets, nboxes, l.classes, nms);
draw_detections(im, dets, nboxes, thresh, names, alphabet, l.classes);
free_detections(dets, nboxes);
if(outfile){
save_image(im, outfile);
}
else{
char b[2048];
sprintf(b,"/home/pxt/darknet/data/out/%s",GetFilename(path));//"/home/FENGsl/darknet/data"修改成自己的路径
save_image(im, b);
printf("save %s successfully!\n",GetFilename(path));
#ifdef OPENCV
//cvNamedWindow("predictions", CV_WINDOW_NORMAL);
//if(fullscreen){
// cvSetWindowProperty("predictions", CV_WND_PROP_FULLSCREEN, CV_WINDOW_FULLSCREEN);
// }
// show_image(im, "predictions");
//cvWaitKey(0);
//cvDestroyAllWindows();
#endif
}
free_image(im);
free_image(sized);
if (filename) break;
}
}
}
}
- step3:打开中端进入/darknet目录下,重新编译(编译中可能有warning,不影响最终结果)
make
- step4:将想要测试的图片路径,放到一个.txt文档中,然后运行测试
vim test.txt
./darknet detector test cfg/voc.data cfg/yolov3-voc.cfg yolov3-voc_final.weights
- step5: 运行加载模型成功后提示你在中断输入图片路径,将刚才新建的test.txt文件路径输入按回车即可,或者也可以将训练时生成的2007_test.txt文件路径输入。按照前面修改detector.c文件时设置的检测后图片保存路径,我将图片保存在data/out路径下,测试结束后即可在该文件夹下看到保存的图片。
Loading weights from yolov3-voc_final.weights...Done!
Enter Image Path: 2007_test.txt
log可视化
- 处理log文件
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
#this code is to extract the yolov3 train log
'''
import inspect
import os
import random
import sys
'''
def extract_log(log_file,new_log_file,key_word):
f=open(log_file,'r')
train_log=open(new_log_file,'w')
for line in f:
if 'Syncing' in line: #多gpu同步信息,我就一个GPU,这里是可以不要的。
continue
if 'nan' in line: #包含nan的不要
continue
if key_word in line: #包含关键字
train_log.write(line)
f.close()
train_log.close()
extract_log('train_yolov3.log','DJI_yolov3_train_loss.txt','images')
extract_log('train_yolov3.log','DJI_yolov3_train_iou.txt','IOU')
- loss可视化
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#%matplotlib inline
lines =16000 #rows to be draw
result = pd.read_csv('DJI_yolov3_train_loss.txt', skiprows=[x for x in range(lines) if ((x%10!=9) |(x<1000))] ,error_bad_lines=False, names=['loss', 'avg', 'rate', 'seconds', 'images'])
result.head()
#print(result)
result['loss']=result['loss'].str.split(' ').str.get(1)
result['avg']=result['avg'].str.split(' ').str.get(1)
result['rate']=result['rate'].str.split(' ').str.get(1)
result['seconds']=result['seconds'].str.split(' ').str.get(1)
result['images']=result['images'].str.split(' ').str.get(1)
result.head()
result.tail()
#print(result.head())
# print(result.tail())
# print(result.dtypes)
'''
print(result['loss'])
print(result['avg'])
print(result['rate'])
print(result['seconds'])
print(result['images'])
'''
result['loss']=pd.to_numeric(result['loss'])
result['avg']=pd.to_numeric(result['avg'])
result['rate']=pd.to_numeric(result['rate'])
result['seconds']=pd.to_numeric(result['seconds'])
result['images']=pd.to_numeric(result['images'])
result.dtypes
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
ax.plot(result['avg'].values,label='avg_loss')
#ax.plot(result['loss'].values,label='loss')
ax.legend(loc='best')
ax.set_title('The loss curves')
ax.set_xlabel('batches*10')
fig.savefig('avg_loss',dpi=600)
#fig.savefig('loss')
- IOU可视化
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#%matplotlib inline
lines = 16000 #根据train_log_iou.txt的行数修改
result = pd.read_csv('DJI_yolov3_train_iou.txt', skiprows=[x for x in range(lines) if (x%10==0 or x%10==9) ] ,error_bad_lines=False, names=['Region Avg IOU', 'Class', 'Obj', 'No Obj', 'Avg Recall','count'])
result.head()
result['Region Avg IOU']=result['Region Avg IOU'].str.split(': ').str.get(1)
result['Class']=result['Class'].str.split(': ').str.get(1)
result['Obj']=result['Obj'].str.split(': ').str.get(1)
result['No Obj']=result['No Obj'].str.split(': ').str.get(1)
result['Avg Recall']=result['Avg Recall'].str.split(': ').str.get(1)
result['count']=result['count'].str.split(': ').str.get(1)
result.head()
result.tail()
# print(result.head())
# print(result.tail())
# print(result.dtypes)
print(result['Region Avg IOU'])
result['Region Avg IOU']=pd.to_numeric(result['Region Avg IOU'])
result['Class']=pd.to_numeric(result['Class'])
result['Obj']=pd.to_numeric(result['Obj'])
result['No Obj']=pd.to_numeric(result['No Obj'])
result['Avg Recall']=pd.to_numeric(result['Avg Recall'])
result['count']=pd.to_numeric(result['count'])
result.dtypes
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
ax.plot(result['Region Avg IOU'].values,label='Region Avg IOU')
# ax.plot(result['Class'].values,label='Class')
# ax.plot(result['Obj'].values,label='Obj')
# ax.plot(result['No Obj'].values,label='No Obj')
# ax.plot(result['Avg Recall'].values,label='Avg Recall')
# ax.plot(result['count'].values,label='count')
ax.legend(loc='best')
# ax.set_title('The Region Avg IOU curves')
ax.set_title('The Region Avg IOU curves')
ax.set_xlabel('batches')
# fig.savefig('Avg IOU')
fig.savefig('Region Avg IOU')
常见问题
- final其实就是max_batch训练完之后的那一个
- CUDA: out of memory 以及 resizing 问题:显存不够,调小batch,增大subservision,关闭多尺度训练
- fix error in validate_detector_recall
++total;
box t = {truth[j].x, truth[j].y, truth[j].w, truth[j].h};
float best_iou = 0;
//for(k = 0; k < l.w*l.h*l.n; ++k){
for(k = 0; k < nboxes; ++k){
float iou = box_iou(dets[k].bbox, t);
if(dets[k].objectness > thresh && iou > best_iou){
best_iou = iou;
- 常见问题汇总:https://github.com/AlexeyAB/darknet#how-to-train-to-detect-your-custom-objects
cited:
[1]YOLOv3: An Incremental Improvement
[2]Deep Residual Learning for Image Recognition
[3]https://www.jianshu.com/p/d13ae1055302
[4]https://zhuanlan.zhihu.com/p/34142321
[5]https://www.twblogs.net/a/5bfd51eabd9eee7aed3316d6/zh-cn
[6]https://www.cnblogs.com/makefile/p/YOLOv3.html
[7]https://luckmoonlight.github.io/2018/11/28/yoloV1yolov2yoloV3/
[8]https://blog.csdn.net/qq_34806812/article/details/82355614
[9]https://www.cnblogs.com/yumoye/p/10548714.html
[10]https://blog.csdn.net/phinoo/article/details/83022101
[11]https://www.cnblogs.com/eilearn/p/9071440.html
[12]https://www.jianshu.com/p/9a4d5db3cf0a