1、发送get请求
#导包
import requests
#定义一个url
url = "http://xxxxxxx"
#传递参数
payload="{\"head\":{\"accessToken\":\"\",\"lastnotice\":0,\"msgid\":\"\"},\"body\":{\"user_name\":\"super_admin\",\"password\":\"b50c34503a97e7d0d44c38f72d2e91ad\",\"role_type\":1}}"
headers = {
'Content-Type': 'text/plain',
'Cookie': 'akpsysessionid=bafc0ad457d5a99f3a4e53a1d4b32519'
}
#发送get请求
r = requests.get( url=url,headers=headers, data=payload)
#打印结果
print(r.text)
#解码
print(r.encoding)
print(r.text.encode('utf-8').decode('unicode_escape'))#先把返回的结果转换成utf-8,再去解码成中文的编码
2、发送post请求
#导包
import requests
#定义一个url
url = "http://xxxxxxx"
#传递参数
payload="{\"head\":{\"accessToken\":\"\",\"lastnotice\":0,\"msgid\":\"\"},\"body\":{\"user_name\":\"super_admin\",\"password\":\"b50c34503a97e7d0d44c38f72d2e91ad\",\"role_type\":1}}"
headers = {
'Content-Type': 'text/plain',
'Cookie': 'akpsysessionid=bafc0ad457d5a99f3a4e53a1d4b32519'
}
#发送post请求
r = requests.post( url=url,headers=headers, data=payload)
#打印结果
print(r.text)
3、发送https请求
import requests url='https://www.ctrip.com/' #第一种解决方案,发送请求的时候忽略证书,证书的参数verify用的比较多 r=requests.post(url=url,verify=False)#verify参数默认为True,值为False,表示忽略证书 #第二张解决方案,verify里面添加证书的路径 r=requests.post(url=url,verify='证书的路径')#verify参数默认为True,值为False,表示忽略证书 print(r.text)
4、文件上传
import requests
file = {
'filename':open('文件名称','rb')
}
response = requests.post("网址",file)
print(response.text)
5、文件下载
#小文件下载
import requests
r = requests.get("https://img.sitven.cn/Tencent_blog_detail.jpg")
with open(r"D:\a.jpg", "wb") as f:
f.write(r.content)
#大文件下载
import requests
def test_downloads(url, file):
s = requests.session()
r = s.get(url, stream=True, verify=False)
with open(file, "wb") as f:
for chunk in r.iter_content(chunk_size=512):
f.write(chunk)
if __name__ == "__main__":
url = "https://www.url.com/test/export"
file = "D:\\a.xlsx"
test_downloads(url=url, file=file)
6、timeout超时
#导包
import requests
#循环10次
for i in range(0,10):
try:
url="http://xxxxxxxxxxxxxxxx"
data={
"head":{"lastnotice":0,"msgid":"","accessToken":"89a08bff-15d7-4d7a-9967-0b5f4fb699ce"},
"body":{"clinicid":"978f661e-1782-43bd-8675-b0ff1138ab7c","deptid":"09b8515b-b01b-4771-9356-aed6b5aa01bf","doctorid":"65ac0251-10ff-473a-af8a-20e8969176f7","registtype":0,"card_num":"","bcc334":"","patientopt":1,"bkc368":"1","patient":{"cardid":"","medicalcardid":"","label":"","sourcetype":1,"nationid":"01","maritalstatus":0,"address":"","company":"","jobname":"","email":"","remark":"","bcc334":"","name":"11","gender":1,"phone":"","birthdate":"2020-03-23","patienttype":1,"szsbcardid":""}}
}
#发送post请求,超时时间0.03s
r=requests.post(url=url,json=data,timeout=0.03)
print(r.text)
print(r.cookies)
except:
print('error')
7、鉴权
7.1、auth参数鉴权
import requests
url = 'http://192.168.1.1'
headers = {} # 有的不带头也能请求到 不带头可以忽略这行 和headers=headers,这两处
r = requests.get(url, auth=('admin', '123456'), headers=headers, timeout=10)
print(r.text)
7.2、session操作
#实例化session session = requests.session() #使用session发起请求 response = session.post(url,headers=req_header,data=form_data)
7.3、token操作
import requests
url="http://xxxxxxxxxxxxxxx"
json={
"head":{"accessToken":"","lastnotice":0,"msgid":""},
"body":{"username":"15623720880","password":"48028d2558577c526a017883211b4066","forceLogin":0}
}
r=requests.post(url=url,json=json)
print(r.text)
print(r.cookies)
#登录成功后返回token,带入下一个接口
for i in range(0,1):
try:
url="xxxxxxxxxxxxxxxxxx"
data={
"head":{"lastnotice":0,"msgid":"","accessToken":"89a08bff-15d7-4d7a-9967-0b5f4fb699ce"},
"body":{"clinicid":"978f661e-1782-43bd-8675-b0ff1138ab7c","deptid":"09b8515b-b01b-4771-9356-aed6b5aa01bf","doctorid":"65ac0251-10ff-473a-af8a-20e8969176f7","registtype":0,"card_num":"","bcc334":"","patientopt":1,"bkc368":"1","patient":{"cardid":"","medicalcardid":"","label":"","sourcetype":1,"nationid":"01","maritalstatus":0,"address":"","company":"","jobname":"","email":"","remark":"","bcc334":"","name":"11","gender":1,"phone":"","birthdate":"2020-03-23","patienttype":1,"szsbcardid":""}}
}
r=requests.post(url=url,json=data,timeout=0.09)
print(r.text)
print(r.cookies)
except:
print('error')
7.4、sign签名
# appid: wxd930ea5d5a258f4f # mch_id: 10000100 # device_info: 1000 # body: test # nonce_str: ibuaiVcKdpRxkhJA import hashlib #需要加密的字符串 stringA="appid=wxd930ea5d5a258f4f&body=test&device_info=1000&mch_id=10000100&nonce_str=ibuaiVcKdpRxkhJA"; #构建一个对象为md md=hashlib.md5() #对stringA字符串进行编码 md.update(stringA.encode()) #生成后的加密值 AES=md.hexdigest() #把加密的结果,小写转大写 upper函数 AES=AES.upper() print(AES)
参考微信支付:https://pay.weixin.qq.com/wiki/doc/api/jsapi.php?chapter=4_3
8、自动化模块划分
- config 配置文件(python package)#directory和python package大同小异
- common 公共的方法(python package)
- testdata 测试数据(python package)
- test_case测试用例(python package)
- report 报告(directory)
- run_case 测试执行(python package)
- log 日志
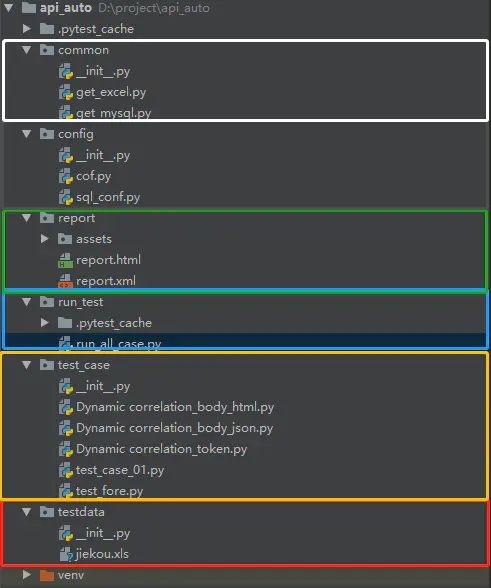
8.1、config配置文件
def server_ip():
'''
ait_ip=''开发环境的服务器ip
sit_ip=''测试环境的服务器ip
:return: 返回不同服务器的地址
'''
server_add={
'dev_ip' : 'http://his.xxxxxxxxxxx.com',
'sit_ip' : 'http://his.xxxxxxxxxxxx.comm'
}
return server_add['dev_ip']
------------------------------------------------------------------------------------
def sql_conf():
'''
host数据库ip
user数据库用户名
password数据库密码
database:连接数据库名
port数据库端口
chrset数据库字符集 中文utf-8
:return:
'''
host='localhost'
user='root'
password='123456'
database='mysql'
port=3306
charset='utf8' #这用utf8,utf-8会报错
return host,user,password,database,port,charset
8.2、common 公共的方法
# 封装一个读取Excel表格数据的函数
# 对Excel表格数据的读取需要用到一个库——xlrd库
import xlrd
def get_excel_value(i):
'''
读取表中一行的数据
:return:返回2,3行数据
'''
filename = r"../testdata/jiekou.xls" #文件要用相对路径
book = xlrd.open_workbook(filename) # 打开一个工作薄,不需要手动进行关闭
# sheet = book.sheet_by_name("Sheet1") 根据工作表的名字,获取一个工作表对象
sheet = book.sheet_by_index(0) # 获取一个工作表,以index的方式,这里是获取第1个工作表
return sheet.cell_value(i,1),sheet.cell_value(i,2)
# print(sheet.nrows) #打印所有行
# print(sheet.ncols) #打印所有列
# print(sheet.row_values(0)) #打印第一行
# print(sheet.col_values(0)) #打印第一列
# print(sheet.cell_value(0,1)) #打印第一行,第二列
# for i in range(1, sheet.nrows):
# print(sheet.cell_value(i,1),sheet.cell_value(i,2))# 打印单元格[所有数据]的值
# str='(sheet.cell_value(i,1),sheet.cell_value(i,2)))'
# print(str)
# for i in range(1, sheet.nrows):
# # for j in range(0, sheet.ncols):
# print(sheet.cell_value(i,j)) # 打印单元格[i,j]的值
---------------------------------------------------------------------------------------------
import pymysql
from config.sql_conf import *
def get_sql(sql):
'''
:param sql:运行查询的sql语句
:return:数据库查询结果
'''
#建立一个连接对象
host, user, password, database, port, charset=sql_conf()
db=pymysql.connect(host=host,user=user,password=password,database=database,port=port,charset=charset)
#建立一个游标
cursor=db.cursor()
#执行sql语句
cursor.execute(sql)
#把sql运行的数据保存在data变量里面
data=cursor.fetchall() #获取查询出的所有的值
cursor.close() #关闭游标
db.close() #关闭数据库连接
return data
# print(get_sql("SELECT help_topic_id FROM help_topic WHERE Name='MOD'")) #执行sql语句
# print(type(get_sql("SELECT help_topic_id FROM help_topic WHERE Name='MOD'")))
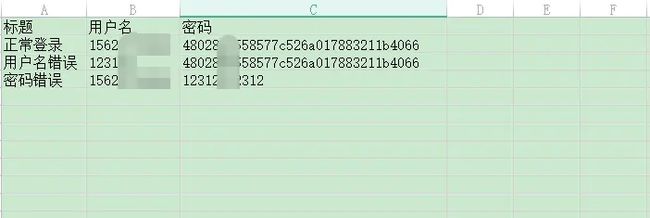
8.3、testdata 测试数据
主要存放xls,txt,csv测试数据
8.4、test_case测试用例
from common.get_mysql import get_sql
from config.cof import server_ip
from common.get_excel import *
from config.sql_conf import *
import requests
# user_id=get_sql("SELECT help_topic_id FROM help_topic WHERE Name='MOD'")#提取数据库数据
# print(user_id)#打印结果
# assert get_sql("SELECT help_topic_id FROM help_topic WHERE Name='MOD'")#断言数据库的数据是否存在
def test_aokao_login():
url=server_ip()+'/service/user/login'
username,password=get_excel_value(1) #读取文件第二行数据
json={
"head":{"accessToken":"","lastnotice":0,"msgid":""},
"body":{"username":username,"password":password,"forceLogin":0}
}
# usernamepassword=get_excel_value(4)[0] #读取文件第二行数据
# print(type(usernamepassword))
# #把str类型转为字典格式 eval 函数
# json=eval(usernamepassword)
r=requests.post(url=url,json=json)
print(r.text)
assert r.status_code==200 #断言状态码是否等于200
assert '"accessToken":"89a08bff-15d7-4d7a-9967-0b5f4fb699ce",' in r.text #断言返回信息是否包含accesstoken
def test_aokao_registadd():
url = server_ip()+'/service/registration/registadd'
data = {
"head": {"lastnotice": 0, "msgid": "", "accessToken": "89a08bff-15d7-4d7a-9967-0b5f4fb699ce"},
"body": {"clinicid": "978f661e-1782-43bd-8675-b0ff1138ab7c", "deptid": "09b8515b-b01b-4771-9356-aed6b5aa01bf",
"doctorid": "65ac0251-10ff-473a-af8a-20e8969176f7", "registtype": 0, "card_num": "", "bcc334": "",
"patientopt": 1, "bkc368": "1",
"patient": {"cardid": "", "medicalcardid": "", "label": "", "sourcetype": 1, "nationid": "01",
"maritalstatus": 0, "address": "", "company": "", "jobname": "", "email": "",
"remark": "", "bcc334": "", "name": "11", "gender": 1, "phone": "",
"birthdate": "2020-03-23", "patienttype": 1, "szsbcardid": ""}}
}
r = requests.post(url=url, json=data, timeout=0.09)
print(r.text)
print(r.cookies)
assert r.status_code == 200 # 断言状态码是否等于200
8.5、report 报告
主要存放html,xml报告

8.6、run_case 测试执行
import pytest
'''
测试文件以test_开头,(以—_test结尾也可以)
测试类以Test开头,并且不能带有init 方法
测试函数以test_开头
断言使用基本的assert即可
'''
#如何去运行测试用例,_test开头的函数就可以,判断用例运行是否成功,assert断言
if __name__=="__main__":
#单个文件运行,运行添加,对应的文件路径,路径要用相对路径
# pytest.main(['../test_case//test_case_01.py'])
#多个文件运行,运行添加多个对应的文件路径,列表的形式,去添加多个文件的路径
# pytest.main(['../test_case/test_fore.py','../test_case/Dynamic correlation_token.py'])
#运行整个目录,添加目录的路径
pytest.main(['../test_case/','--html=../report/report.html','--junitxml=../report/report.xml'])
'''
pytest生成报告:
1、生成html报告
'--html=../report/report.html'
2、生成xml报告
'--junitxml=../report/report.xml'
'''
到此这篇关于python+requests+pytest接口自动化的实现示例的文章就介绍到这了,更多相关python 接口自动化内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!