稀疏推理如何加速移动设备与网页神经网络?

文 / Artsiom Ablavatski 和 Marat Dukhan,软件工程师,Google Research
设备端的神经网络推理能够以一种低延迟和注重隐私的方式,实现如姿势预测和背景模糊等各种实时应用。如通过使用带有 ML 加速库 XNNPACK 的TensorFlow Lite 这样的 ML 推理框架,工程师可以在模型大小、推理速度和预测质量之间找到最佳平衡点,以便模型能适配于各种设备。
-
背景模糊等
https://ai.googleblog.com/2020/10/background-features-in-google-meet.html -
TensorFlow Lite
https://tensorflow.google.cn/lite
优化模型的方法之一是使用稀疏神经网络 (Sparse Neural Networks) [1, 2,3],这些网络中的很大一部分权重值都会设置为 0。通常来说,通过稀疏神经网络得到的模型符合预期质量,因为该过程不仅可以通过压缩减小模型大小,而且还可以省去很大一部分的乘加运算,从而加速推理过程。此外还可以增加模型中的参数数量,然后对其进行稀疏化处理,以匹配原始模型的质量,这同样也是通过加速推理来优化模型。然而该技术在生产过程中的应用仍相当有限,这主要是由于缺乏稀疏化处理热门卷积架构的工具,以及在设备端执行这些操作时缺乏足够的支持。
-
论文 1
https://arxiv.org/pdf/2102.00554.pdf -
论文 2
https://arxiv.org/pdf/1902.09574.pdf -
论文 3
https://arxiv.org/pdf/1911.09723.pdf
今天,我们将宣布两件事,首先是发布一组针对 XNNPACK 加速库和 TensorFlow Lite 的新功能,这些功能可以实现稀疏网络的高效推理;其次是发布有关如何稀疏处理神经网络的指南,目的是帮助研究人员在设备端开发自己的稀疏模型。
-
XNNPACK 加速库
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/delegates/xnnpack/README.md#sparse-inference
我们已与 DeepMind 携手合作,开发出一些能提供新一代实时感知体验的工具,如 MediaPipe 中的手势追踪 (https://mediapipe.dev) 及 Google Meet 中的背景特征,这些工具能将推理速度加快 1.2 到 2.4 倍不等,同时将模型大小缩减一半。在本文中,我们将提供稀疏神经网络的技术概述,包括在训练时引入稀疏概念和设备端的部署,并就研究人员如何创建稀疏模型提供一些想法。
质量相同的密集模型(左)和稀疏模型(右)在处理 Google Meet 背景特征时花费的时间比较。为了便于阅读,显示的处理时间为每移动 100 帧平均所耗费的时间
稀疏化神经网络
很多现代深度学习架构,如 MobileNet 和 EfficientNetLite,主要由具有较小空间内核的深度卷积和将输入图像中的特征线性组合在一起的 1x1 卷积组成。尽管此类架构有很多潜在的稀疏化目标,如在很多网络开端经常出现的各种 2D 卷积或深度卷积,但根据推理时间衡量,1x1 卷积是处理代价最高昂的算子。因为 1x1 卷积占计算总量的 65% 以上,所以可以将其视为最佳的稀疏化目标。
| 架构 | 推理时间 |
|---|---|
| MobileNet | 85% |
| MobileNetV2 | 71% |
| MobileNetV3 | 71% |
| EfficientNet-Lite | 66% |
现代移动架构中 1x1 卷积推理时间占比的比较情况
-
MobileNet
https://arxiv.org/abs/1704.04861 -
深度卷积
https://tensorflow.google.cn/api_docs/python/tf/keras/layers/DepthwiseConv2D
在像 XNNPACK 这样的现代设备端推理引擎中,深度学习模型中 1x1 卷积及其他操作的实现都依赖于 HWC 张量布局,其中张量维度对应输入图像的高度、宽度和通道(Height, Width, Channel,如红、绿、蓝)。推理引擎可借此张量配置并行处理与每个空间位置(如图像的每个像素)相对应的通道。然而这种张量的排序方式并不适用于稀疏推理,因为在这种排序下通道会被设置为张量最内部的维度,导致在访问时的计算成本变高。
-
依赖于 HWC 张量布局
https://arxiv.org/pdf/1907.01989.pdf
我们对 XNNPACK 进行了更新,使其能检测模型是否为稀疏模型。如果检测到稀疏模型,则 XNNPACK 将从标准的密集推理模式转换为采用 CHW(通道、高度、宽度)张量布局的稀疏推理模式。张量的重新排序可以加速稀疏 1x1 卷积内核的实现,原因有两个:
-
在单次条件检查之后,当相应的通道权重为零时,系统将跳过整个张量空间切片,而不是逐像素进行测试;
-
当通道权重不为零时,可以通过将相邻的像素加载到同一储存单元中来提高计算效率。
-
稀疏推理
https://arxiv.org/pdf/1911.09723.pdf
我们可以借此同时处理多个像素,同时还可以跨多个线程并行执行每个操作。当至少有 80% 的权重为零时,这些变化加起来可以将速度提升 1.8 至 2.3 倍。
为避免每次操作后都要在最适合稀疏推理的 CHW 张量布局和标准的 HWC 张量布局中来回切换,XNNPACK 在 CHW 布局中提供了多个 CNN 运算符的有效实现。
-
多个 CNN 运算符
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/delegates/xnnpack/README.md#sparse-inference
稀疏神经网络训练指南
要创建稀疏网络神经,我们在此次发布的指南中建议:先创建密集网络神经,然后在训练过程中逐步将其中一部分权重设置为零。这一过程也称为剪枝。在众多可用的剪枝技术中,我们建议使用基于幅值的剪枝(Magnitude Pruning,可在 TensorFlow 模型优化工具包内使用)或最新推出的 RigL 方法。只要适当增加训练时间,这两种方法都可以在不牺牲深度学习模型质量的前提下,成功稀疏化深度学习模型。生成的稀疏模型可以有效地以压缩格式存储,与同等的密集模型相比,其大小会缩减为以前的一半。
-
TensorFlow 模型优化工具包
https://tensorflow.google.cn/model_optimization -
RigL
https://ai.googleblog.com/2020/09/improving-sparse-training-with-rigl.html -
有效地以压缩格式存储
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/python/lite.py#L108
训练时间、学习速率和剪枝计划等超参数均会对稀疏网络的质量产生影响。TensorFlow 剪枝 API 提供了一个优秀示例,说明应该如何选择这些超参数,同时还提供了一些训练此类模型的技巧。我们建议您运行超参数搜索,以发现与您应用完美适配的超参数组合。
应用
我们已经证实了,可以对分类任务、密集分割(例如,Meet 背景模糊)和回归问题 (MediaPipe Hands) 进行稀疏化,这会给用户带来实实在在的好处。例如,对于 Google Meet 而言,稀疏化将模型的推理时间缩短了 30%,从而令更多用户能够访问更高质量的模型。
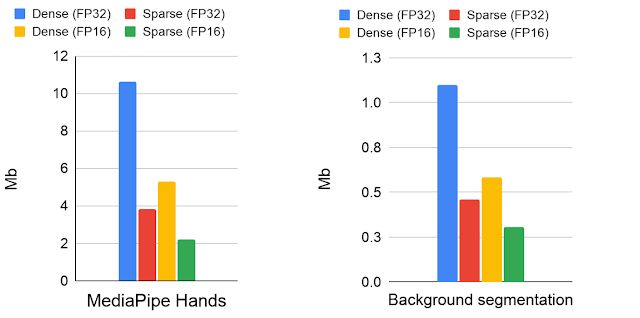
密集模型和稀疏模型的模型大小比较情况(以 Mb 为单位):模型会以 16 位和 32 位浮点格式存储这些模型
-
MediaPipe Hands
https://google.github.io/mediapipe/solutions/hands.html
这里描述的稀疏方法最适合与基于倒置残差块(如,MobileNetV2、MobileNetV3 和 EfficientNetLite)的架构一起配合使用。网络的稀疏度会同时影响推理速度和质量。从具有固定容量的密集网络开始,我们发现即使在 30% 的稀疏度下,模型也可以获得些许性能提升。在稀疏度达到 70% 之前,随着稀疏度的增加,模型质量仍然相对靠近密集基线,而稀疏度超过此数值后,准确率会有更为明显的下降。但是,可以通过将基础网络的大小增加 20% 来补偿稀疏度为 70% 时下降的准确率,这会在不降低模型质量的情况下缩短推理时间。无需进行进一步更改即可运行稀疏化模型,因为 XNNPACK 可以识别并自动启用稀疏推理。

针对与推理时间相关的不同稀疏度(越小越好)以及预测分割任务的质量(按交并比 (IoU) 衡量)的消融研究
将稀疏作为蒸馏的自动替代方案
Google Meet 中的背景模糊使用了依托于修改后的 MobileNetV3 主干网络且带有注意力模块的分割模型。通过应用 70% 的稀疏化,并同时保持前景掩膜的质量,我们能够将模型的速度提升 30%。我们检查了稀疏模型和密集模型对来自 17 个地理子区域的图像的预测,但未发现显著差异,并且在关联的模型卡中发布了详细信息。
-
模型卡
https://mediapipe.page.link/meet-segmentation-sparse-mc
同样地,MediaPipe Hands 会使用基于 EfficientNetLite 骨干网络的模型在移动设备和网页上对手部特征点进行实时预测。此骨干网络模型是从大型密集模型手动蒸馏而来,这是一个计算成本很高的迭代过程。通过使用密集模型的稀疏版本而不是蒸馏版本,我们能够保持相同的推理速度,但无需执行对密集模型进行蒸馏的费力过程。与密集模型相比,稀疏模型可将推断性能提升两倍,从而达到与蒸馏模型相同的特征点质量。在某种意义上,稀疏化可以被视为一种进行非结构化模型蒸馏的自动方法,这可以提升模型性能而无需耗费大量人力。我们使用地理多样性数据集对稀疏模型进行了评估,并公开发布了模型卡。
相同质量的密集模型(左)、蒸馏模型(中)和稀疏模型(右)的执行时间比较情况:密集模型的处理时间是稀疏模型或蒸馏模型的 2 倍。蒸馏模型取自官方 MediPipe 解决方案。密集和稀疏网络演示已发布
-
发布
https://mediapipe.page.link/handmc-sparse -
MediPipe 解决方案
https://github.com/google/mediapipe/blob/master/docs/solutions/hands.md
研究展望
我们发现,稀疏化是一项简单但功能强大的技术,可用于提高神经网络的 CPU 推理性能。稀疏推理让工程师能够运行更大的模型而不会产生显著的性能或大小开销,并且可以为研究提供一个有前景的新方向。我们将继续扩展 XNNPACK 并为 CHW 布局中的运算提供广泛支持,并且将探索如何将它与量化等其他优化技术结合使用。我们非常期待看到您使用此技术构建的成果!
致谢
特别感谢所有参与此项目的人员:Karthik Raveendran、Erich Elsen、Tingbo Hou、Trevor Gale、Siargey Pisarchyk、Yury Kartynnik、Yunlu Li、Utku Evci、Matsvei Zhdanovich、Sebastian Jansson、Stéphane Hulaud、Michael Hays、Juhyun Lee、Fan Zhang、Chuo-Ling Chang、Gregory Karpiak、Tyler Mullen、Jiuqiang Tang、Ming Guang Yong、Igor Kibalchich 和 Matthias Grundmann。
想了解稀疏推理或 TensorFlow Lite ML 推理框架,请扫描下方二维码,关注 TensorFlow 公众号,回复关键词“TensorFlow Lite”,更多文章一次看全。
