[toc]
1.事务
1.1 隔离级别和特性
事务的特性ACID
- A Atomicity 原子性 执行的完整性,不可拆分
- C Consistency 一致性 数据库一致性保持不变
- I Isolation 隔离性 隔离性确保事务并发执行后的系统状态与这些事务以某种次序串行执行以后的状态是等价的。
- D Durability 持久性 执行后结果存储
事务隔离级别
可串行化(Serializable):sql中最高的隔离性级别,能够避免脏读,幻读,不可重复读。代价也相对沉重,会大大影响数据库的性能。可重复读(Repeatable read):只允许读取已提交的数据,而且在一个事务两次读取一个数据项期间,其他事务不得更新该数据。这种状态不能避免幻读。
已提交读(Read committed):只允许读取已提交数据,但不要求可重复读。这种状态只能避免脏读。
未提交读(Read uncommitted):允许读取未提交的数据。这是最低的隔离级别,脏读,幻读,不可重复读都无法避免。
mysql innodb 默认隔离级别 Repeatable read
1.2 事务日志
https://www.cnblogs.com/f-ck-need-u/archive/2018/05/08/9010872.html
https://blog.csdn.net/yu757371316/article/details/81081669
https://liuzhengyang.github.io/2017/04/18/innodb-mvcc/#Redo-log-bin-log-Undo-log
1.redo log通常是物理日志,记录的是数据页的物理修改,而不是某一行或某几行修改成怎样怎样,它用来恢复提交后的物理数据页(恢复数据页,且只能恢复到最后一次提交的位置。
2.undo用来回滚行记录到某个版本。undo log一般是逻辑日志,根据每行记录进行记录
事务日志可以帮助提高事务的效率。保证事务的持久性。
写日志采用追加方式。
数据库重启和奔溃时可以从redolog慢慢刷会磁盘。
事务恢复策略
A. 进行恢复时,只重做已经提交了的事务。
B. 进行恢复时,重做所有事务包括未提交的事务和回滚了的事务。然后通过Undo Log回滚那些
未提交的事务。 innodb 采用
1.3 事务的相关操作
1.查看当前会话隔离级别
select @@tx_isolation;
2.查看系统当前隔离级别
select @@global.tx_isolation;
3.设置当前会话隔离级别
set session transaction isolatin level repeatable read;
4.设置系统当前隔离级别
set global transaction isolation level repeatable read;
2.锁
https://segmentfault.com/a/1190000014133576
https://lanjingling.github.io/2015/10/10/mysql-hangsuo/
https://blog.csdn.net/wushiwude/article/details/76042509
https://www.zhihu.com/question/51513268
https://liuzhengyang.github.io/2017/04/18/innodb-mvcc/
https://sq.163yun.com/blog/article/174660532728422400
https://segmentfault.com/a/1190000012650596

2.1 锁的类型
2.1.1 共享锁S
允许一个事务去读一行,阻止其他事务获得相同的数据集的排他锁。
select ... in share mode
共享锁就是我读的时候,你可以读,但是不能写。
2.1.2 排他锁X
允许获得排他锁的事务更新数据,但是组织其他事务获得相同数据集的共享锁和排他锁。
select ... for update
排他锁就是我写的时候,你不能读也不能写。。
2.1.3 意向共享锁IS
表示事务准备给数据行加入共享锁,也就是说一个数据行加共享锁前必须先取得该表的IS锁
2.1.4 意向排他锁 IX
表示事务准备给数据行加入排他锁,说明事务在一个数据行加排他锁前必须先取得该表的IX锁。
2.1.5 锁的兼容+ 意向锁的意义
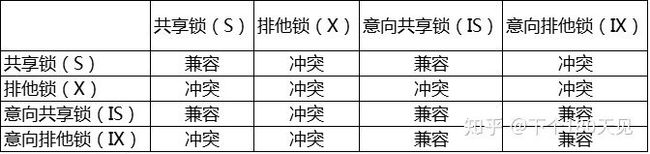
当一个事务请求的锁模式与当前的锁兼容,InnoDB就将请求的锁授予该事务;反之如果请求不兼容,则该事务就等待锁释放。
意向锁是为了实现多粒度锁,是数据库自动加持的。
对于意向锁的理解
意向锁是一种快速判断表锁与之前可能存在的行锁冲突的机制
事务A锁住了表中的一行,让这一行只能读,不能写。之后,事务B申请整个表的写锁。如果事务B申请成功,那么理论上它就能修改表中的任意一行,这与A持有的行锁是冲突的。数据库需要避免这种冲突,就是说要让B的申请被阻塞,直到A释放了行锁。数据库要怎么判断这个冲突呢?step1:判断表是否已被其他事务用表锁锁表step2:判断表中的每一行是否已被行锁锁住。注意step2,这样的判断方法效率实在不高,因为需要遍历整个表。于是就有了意向锁。在意向锁存在的情况下,事务A必须先申请表的意向共享锁,成功后再申请一行的行锁。在意向锁存在的情况下,上面的判断可以改成step1:不变step2:发现表上有意向共享锁,说明表中有些行被共享行锁锁住了,因此,事务B申请表的写锁会被阻塞。
。
2.2 加锁机制和思想
2.2.1 乐观锁
乐观锁会“乐观地”假定大概率不会发生并发更新冲突,访问、处理数据过程中不加锁,只在更新数据时再根据版本号或时间戳判断是否有冲突,有则处理,无则提交事务
实践 伪代码
select version from xxxxx
......
update xxxxx set version=version+1 where version=#{version}
//更新的时候确保version是之钱读取的version
2.2.2 悲观锁
悲观锁会“悲观地”假定大概率会发生并发更新冲突,访问、处理数据前就加排他锁,在整个数据处理过程中锁定数据,事务提交或回滚后才释放锁;
实践
select xxx from xxx for update //直接获取排他锁
2.3 锁的粒度
2.3.1 行锁
行锁的解释: 对记录的锁
行锁的劣势:开销大;加锁慢;会出现死锁
行锁的优势:锁的粒度小,发生锁冲突的概率低;处理并发的能力强
2.3.2 表锁
表锁的解释: 对表的锁
表锁的优势:开销小;加锁快;无死锁
表锁的劣势:锁粒度大,发生锁冲突的概率高,并发处理能力低
注意:
InnoDB 支持表锁和行锁,使用索引作为检索条件修改数据时采用行锁,否则采用表锁。
2.4 锁的实现方式 (默认PR隔离级别)
innodb行锁是给索引项加锁实现的,所以如果没有索引,会通过隐藏的聚簇索引来加锁,和表锁效果相同。
2.4.1 锁的算法
[图片上传失败...(image-a75577-1555250715381)]
[图片上传失败...(image-f235aa-1555250715381)]
2.4.2 MVCC
MVCC (Multiversion Concurrency Control),即多版本并发控制技术,它使得大部分支持行锁的事务引擎,不再单纯的使用行锁来进行数据库的并发控制,取而代之的是把数据库的行锁与行的多个版本结合起来,只需要很小的开销,就可以实现非锁定读,从而大大提高数据库系统的并发性能
MVCC只在 READ COMMITTED 和 REPEATABLE READ 两个隔离级别下工作;
MVCC可以使用 乐观(optimistic)锁 和 悲观(pessimistic)锁来实现;
相关文章
https://segmentfault.com/a/1190000012650596
2.5 快照读和当前读
当前读:即加锁读,读取记录的最新版本,会加锁保证其他并发事务不能修改当前记录,直至获取锁的事务释放锁
快照读:即不加锁读,读取记录的快照版本而非最新版本,通过MVCC实现;
InnoDB默认的RR事务隔离级别下,不显式加『lock in share mode』与『for update』的『select』操作都属于快照读,保证事务执行过程中只有第一次读之前提交的修改和自己的修改可见,其他的均不可见;
3.索引
http://www.cnblogs.com/itdragon/p/8146439.html
https://juejin.im/post/5b55b842f265da0f9e589e79
https://juejin.im/post/5b9fad345188255ca1537022
https://www.cnblogs.com/wade-luffy/p/6292784.html
https://fangjian0423.github.io/2017/07/05/mysql-index-summary/
https://blog.csdn.net/u010648555/article/details/81102957
https://segmentfault.com/a/1190000015416513
https://www.cnblogs.com/duanxz/p/5244703.html
3.1 索引的优缺点
优点:索引可以加快数据库的检索速度
缺点:索引会降低插入、删除、修改等维护任务的速度。索引需要占物理和数据空间。
3.2 索引的原理
其实就是将无序的数据变成有序(相对):
[图片上传失败...(image-5f2ff0-1555250715381)]
要找到id为8的记录简要步骤:
[图片上传失败...(image-c6b9d8-1555250715381)]
3.3 索引的分类
3.3.1 普通索引
普通索引(单列索引):单列索引是最基本的索引,它没有任何限制。
3.3.2 复合索引
复合索引:复合索引是在多个字段上创建的索引。复合索引遵守“最左前缀”原则,即在查询条件中使用了复合索引的第一个字段,索引才会被使用。因此,在复合索引中索引列的顺序至关重要。
3.3.3 唯一索引
唯一索引:唯一索引和普通索引类似,主要的区别在于,唯一索引限制列的值必须唯一,但允许存在空值(只允许存在一条空值)。
3.3.4 主键索引
主键索引是一种特殊的唯一索引,一个表只能有一个主键,不允许有空值。一般是在建表的时候同时创建主键索引:
3.3.5 全文索引
全文索引主要用来查找文本中的关键字,而不是直接与索引中的值相比较。fulltext索引跟其它索引大不相同,它更像是一个搜索引擎,而不是简单的where语句的参数匹配。fulltext索引配合match against操作使用,而不是一般的where语句加like。目前只有char、varchar,text 列上可以创建全文索引。
3.4 聚集索引和辅助索引
聚集索引
聚集索引就是以主键创建的索引
一张表只粗在一个聚集索引
当一张表存在主键时就以主键构造一颗B+树创建聚集索引(innodb 必须存在)
辅助索引(非聚集索引,二级索引)
非聚集索引就是以非主键创建的索引
一张表可以有多个非聚集索引.
非聚集索引在叶子节点存储的是主键和索引列,使用非聚集索引查询出数据时,拿到叶子上的主键再去查到想要查找的数据。(拿到主键再查找这个过程叫做回表)
覆盖索引就是把要查询出的列和索引是对应的,不做回表操作!如下
//创建索引(username,age)
select username , age from user where username = 'Java3y' and age = 20