目录

什么是相关性检验*?
相关检验用于评估两个或多个变量之间的关联。
例如,如果我们想知道父亲和儿子的身高之间是否存在关系,可以计算相关系数来回答这个问题。
如果两个变量(父亲和儿子的身高)之间没有关系,则儿子的平均身高应该相同,而与父亲的身高无关,反之亦然。
在这里,我们将描述不同的相关方法,并使用R软件提供一些实用的示例。
安装并加载所需的R软件包
我们将使用ggpubr R软件包进行基于ggplot2的简单数据可视化
- 按照以下说明从GitHub安装最新版本(推荐):
if(!require(devtools)) install.packages("devtools")
devtools::install_github("kassambara/ggpubr")
- 或者,从CRAN安装如下:
install.packages("ggpubr")
- 加载ggpubr如下:
library("ggpubr")
相关分析方法
有多种执行相关分析的方法:
皮尔逊相关(r),它测量两个变量(x和y)之间的线性相关性。这也称为参数相关检验,因为它取决于数据的分布。仅当x和y来自 正态分布时 才可以使用它。y = f(x)的图称为 线性回归曲线。
Kendall tau和Spearman rho,它们是基于秩的相关系数(非参数)
最常用的方法是Pearson相关方法。
相关公式
在下面的公式中
- 和 是长度为 n 的两个向量
- 和 分别对应于 和 的均值。
皮尔逊相关公式
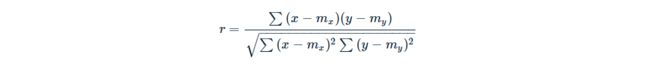
相关性的p值(显着性水平)可以确定:
通过将相关系数表用于自由度: 通过使用自由度的相关系数表:,其中是 x 和 y 变量中的观测数。
或通过如下计算 t值:
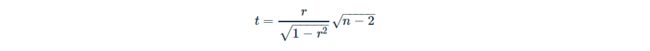
在情况2)中,使用的 t分布表 确定相应的值
如果 p < 5%,则x和y之间的相关性很显着。
Spearman相关公式
Spearman相关 方法计算x的秩和y变量的秩之间的相关性。

其中:。
肯德尔相关公式
Kendall相关法测量x和y变量的排序之间的对应关系。x与y观测值的可能配对总数为,其中 n 是x和y的大小。
程序如下:
首先按x值对这些对进行排序。如果x和y是相关的,那么它们的相对秩是相同的。
现在,对于每个yi,计算yj>yi(一致对(c))和yj
肯德尔相关距离定义如下:
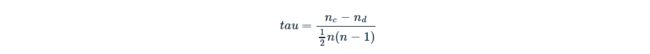
其中:
nc:一致对的总数
nd:不一致对的总数
n: x和y的大小
在R中的计算相关性
R函数
可以使用函数cor()或cor.test()计算相关系数:
- cor()计算相关系数
- cor.test()测试配对样本之间的关联/相关性。它同时返回相关系数和相关的显着性水平(或p值)。
简化格式为:
cor(x, y, method = c("pearson", "kendall", "spearman"))
cor.test(x, y, method=c("pearson", "kendall", "spearman"))
- x,y:具有相同长度的数值向量
- 方法:相关方法
如果您的数据包含缺失值,请使用以下R代码通过按大小写删除来处理缺失值。
cor(x, y, method = "pearson", use = "complete.obs")
如果x中存在NA值,则把x中的NA及y中对应的数字删除以保证x和y长度相等
将数据导入R
准备好你的数据如下规定:最佳实践为您准备的数据集的R
将数据保存在外部.txt标签或.csv文件中
如下将数据导入R:
# If .txt tab file, use this
my_data <- read.delim(file.choose())
# Or, if .csv file, use this
my_data <- read.csv(file.choose())
在这里,我们以内置的R数据集mtcars为例。
下面的R代码计算mtcars数据集中mpg和wt变量之间的相关性:
my_data <- mtcars
head(my_data, 6)
mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1
我们要计算mpg和wt变量之间的相关性。
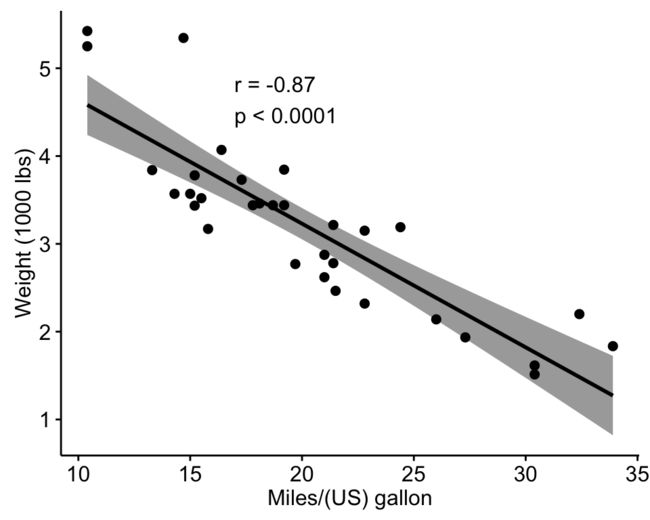
使用散点图可视化数据
要使用R基本图,请单击此链接:散点图-R基本图。在这里,我们将使用 ggpubr R包。
library("ggpubr")
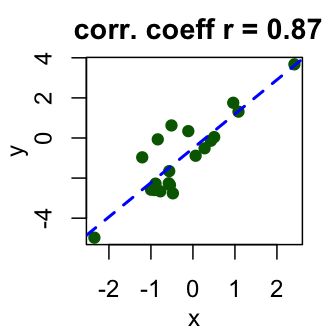
ggscatter(my_data, x = "mpg", y = "wt",
add = "reg.line", conf.int = TRUE,
cor.coef = TRUE, cor.method = "pearson",
xlab = "Miles/(US) gallon", ylab = "Weight (1000 lbs)")
初步测试以检查测试假设
协方差是线性的吗?是的,形成上面的图,关系是线性的。在散点图显示弯曲模式的情况下,我们正在处理两个变量之间的非线性关联。
-
来自两个变量(x,y)中每个变量的数据是否服从正态分布?
- 使用Shapiro-Wilk正态性检验–> R函数:shapiro.test()
- 并查看正态图—> R函数:ggpubr :: ggqqplot()
- Shapiro-Wilk测试可以执行以下操作:
- 空假设:数据呈正态分布
- 替代假设:数据不是正态分布
# Shapiro-Wilk normality test for mpg
shapiro.test(my_data$mpg) # => p = 0.1229
# Shapiro-Wilk normality test for wt
shapiro.test(my_data$wt) # => p = 0.09
从输出中,两个p值大于显着性水平0.05,这意味着数据的分布与正态分布没有显着差异。换句话说,我们可以假设正常性。
- 使用QQ图(分位数-分位数图)对数据正态性进行外观****检查。QQ图绘制给定样本与正态分布之间的相关性。
library("ggpubr")
# mpg
ggqqplot(my_data$mpg, ylab = "MPG")
# wt
ggqqplot(my_data$wt, ylab = "WT")
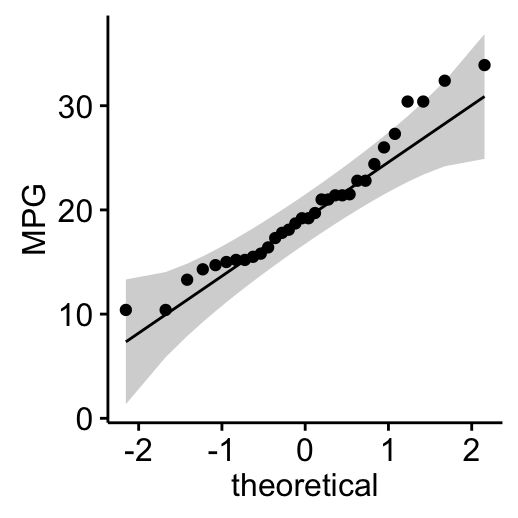
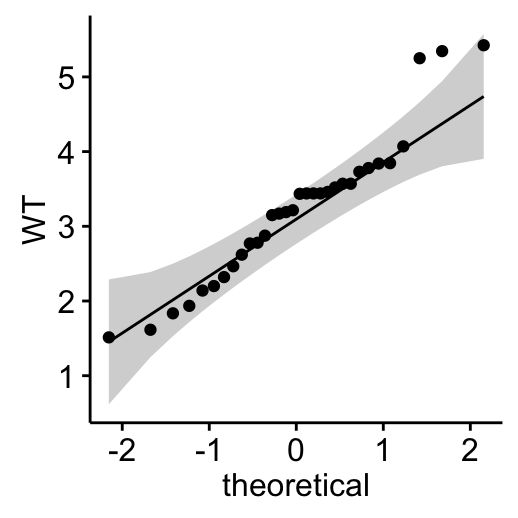
从正态分布图中,我们得出结论,两个总体都可能来自正态分布。
请注意,如果数据不是正态分布的,建议使用非参数相关,包括Spearman和Kendall基于秩的相关测试。
皮尔逊相关检验
mpg和wt变量之间的相关性测试:
res <- cor.test(my_data$wt, my_data$mpg,
method = "pearson")
res
Pearson's product-moment correlation
data: my_data$wt and my_data$mpg
t = -9.559, df = 30, p-value = 1.294e-10
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
-0.9338264 -0.7440872
sample estimates:
cor
-0.8676594
在上面的结果中:
- t是t检验统计值(t = -9.559),
- df是自由度(df = 30),
- p值是t检验的显着性水平(p值= 1.29410 ^ {-10})。
- conf.int是相关系数在95%时的置信区间(conf.int = [-0.9338,-0.7441]);
- 样本估计值是相关系数(Cor.coeff = -0.87)。
结果解释
测试的p值为 1.294e-10,小于显着性水平alpha = 0.05。我们可以得出结论,wt和mpg与显着相关,其相关系数 -0.87,p值 1.294e-10。
访问由 cor.test() 函数返回的值
函数 cor.test() 返回包含以下组件的列表:
- p.value:测试的p值
- estimate:相关系数
# Extract the p.value
res$p.value
[1] 1.293959e-10
# Extract the correlation coefficient
res$estimate
cor
-0.8676594
Kendall 秩相关检验
的肯德尔秩相关系数或Kendall的tau统计来估计关联的基于排名的度量。如果数据不一定来自二元正态分布,则可以使用此检验。
res2 <- cor.test(my_data$wt, my_data$mpg, method="kendall")
res2
Kendall's rank correlation tau
data: my_data$wt and my_data$mpg
z = -5.7981, p-value = 6.706e-09
alternative hypothesis: true tau is not equal to 0
sample estimates:
tau
-0.7278321
tau是肯德尔相关系数。
x和y之间的相关系数为-0.7278,p值为 6.70610e-9。
Spearman 秩相关检验
Spearman的rho统计量也用于估计基于秩的关联度。如果数据不是来自二元正态分布,则可以使用此检验。
res2 <-cor.test(my_data$wt, my_data$mpg, method = "spearman")
res2
Spearman's rank correlation rho
data: my_data$wt and my_data$mpg
S = 10292, p-value = 1.488e-11
alternative hypothesis: true rho is not equal to 0
sample estimates:
rho
-0.886422
rho是Spearman的相关系数。
x和y之间的相关系数为-0.8864,p值为1.48810 ^ {-11}。
解释相关系数
相关系数介于-1和1之间:
- -1表示很强的负相关性:这意味着x每次增加,y减少(左图)
- 0表示两个变量(x和y)之间没有关联(中间图)
- 1表示强正相关:这意味着y随着x****增大(右图)
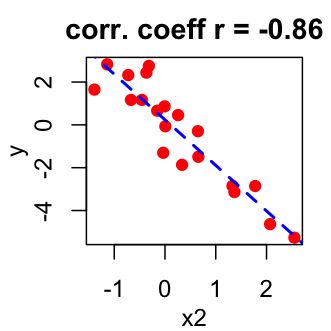
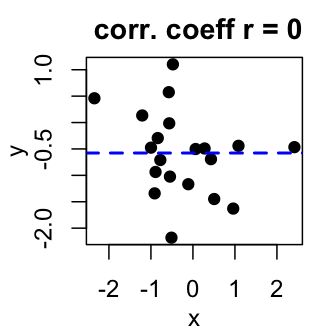
在线相关系数计算器
您可以通过单击以下链接在线计算两个变量之间的相关性,而无需进行任何安装:
相关系数计算器
概要
- 使用函数cor.test(x,y)分析两个变量之间的相关系数并获得相关的显着性水平。
- 使用函数cor.test(x,y)的三种可能的相关方法:pearson,kendall,spearman
觉得有用的老铁麻烦点个小爱心~