TensorFlow2学习(二):Keras 快速入门
文章目录
- 1.导入tf.keras
- 2.构建简单模型
-
- 2.1模型堆叠
-
- 2.1.1dense :全连接层
- 2.2网络配置
- 3.训练和评估
-
- 3.1设置训练流程
- 3.2输入Numpy数据
-
- 3.2.1fit参数详解
- 3.3tf.data输入数据
-
- 3.3.1构造dataset
- 3.4评估与预测
- 3.5 Sequential模型线性回归实战
- 4.构建高级模型
-
- 4.1函数式api
-
- 4.1.2 tf.keras.Input函数
- 4.2模型子类化
- 4.3自定义层
- 4.4回调
- 5保持和恢复
-
- 5.1权重保存
- 5.2保存网络结构
- 5.3保存整个模型
- 6.将keras用于Estimator
Keras 是一个用于构建和训练深度学习模型的高阶 API。它可用于快速设计原型、高级研究和生产。
keras的3个优点: 方便用户使用、模块化和可组合、易于扩展
1.导入tf.keras
tensorflow2推荐使用keras构建网络,常见的神经网络都包含在keras.layer中(最新的tf.keras的版本可能和keras不同)
import tensorflow as tf
from tensorflow.keras import layers
print(tf.__version__)
print(tf.keras.__version__)
2.构建简单模型
2.1模型堆叠
最常见的模型类型是层的堆叠:tf.keras.Sequential 模型
Sequential模型字面上的翻译是顺序模型,给人的第一感觉是那种简单的线性模型,但实际上Sequential模型可以构建非常复杂的神经网络,包括全连接神经网络、卷积神经网络(CNN)、循环神经网络(RNN)、等等。这里的Sequential更准确的应该理解为堆叠,通过堆叠许多层,构建出深度神经网络。
model = tf.keras.Sequential()
model.add(layers.Dense(32, activation='relu'))
model.add(layers.Dense(32, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
Sequential模型的核心操作是添加layers(图层),以下展示如何将一些最流行的图层:
#卷积层
model.add(Conv2D(64, (3, 3), activation='relu'))
#最大池化层
model.add(MaxPooling2D(pool_size=(2, 2)))
#全连接层
model.add(Dense(256, activation='relu'))
#dropout
model.add(Dropout(0.5))
#Flattening layer(展平层)
model.add(Flatten())
2.1.1dense :全连接层
函数如下:
tf.layers.dense(
inputs,
units,
activation=None,
use_bias=True,
kernel_initializer=None, ##卷积核的初始化器
bias_initializer=tf.zeros_initializer(), ##偏置项的初始化器,默认初始化为0
kernel_regularizer=None, ##卷积核的正则化,可选
bias_regularizer=None, ##偏置项的正则化,可选
activity_regularizer=None, ##输出的正则化函数
kernel_constraint=None,
bias_constraint=None,
trainable=True,
name=None, ##层的名字
reuse=None ##是否重复使用参数
)
部分参数解释:
inputs:输入该网络层的数据 units:输出的维度大小,改变inputs的最后一维
activation:激活函数,即神经网络的非线性变化
use_bias:使用bias为True(默认使用),不用bias改成False即可,是否使用偏置项
trainable=True:表明该层的参数是否参与训练。如果为真则变量加入到图集合中
GraphKeys.TRAINABLE_VARIABLES (see tf.Variable)
2.2网络配置
tf.keras.layers中网络配置:
activation:设置层的激活函数。此参数由内置函数的名称指定,或指定为可调用对象。默认情况下,系统不会应用任何激活函数。
kernel_initializer 和 bias_initializer:创建层权重(核和偏差)的初始化方案。此参数是一个名称或可调用对象,默认为 “Glorot uniform” 初始化器。
kernel_regularizer 和 bias_regularizer:应用层权重(核和偏差)的正则化方案,例如 L1 或 L2 正则化。默认情况下,系统不会应用正则化函数。
layers.Dense(32, activation='sigmoid')
layers.Dense(32, activation=tf.sigmoid)
layers.Dense(32, kernel_initializer='orthogonal')
layers.Dense(32, kernel_initializer=tf.keras.initializers.glorot_normal)
layers.Dense(32, kernel_regularizer=tf.keras.regularizers.l2(0.01))
layers.Dense(32, kernel_regularizer=tf.keras.regularizers.l1(0.01))
3.训练和评估
3.1设置训练流程
构建好模型后,通过调用 compile 方法配置该模型的学习流程:
tf.keras.Model.compile 采用三个重要参数:
optimizer:此对象会指定训练过程。从 tf.train 模块向其传递优化器实例,例如 AdamOptimizer、RMSPropOptimizer 或 GradientDescentOptimizer。
loss:要在优化期间最小化的函数。常见选择包括均方误差 (mse)、categorical_crossentropy 和 binary_crossentropy。损失函数由名称或通过从 tf.keras.losses 模块传递可调用对象来指定。
metrics:用于监控训练。它们是 tf.keras.metrics 模块中的字符串名称或可调用对象。
model = tf.keras.Sequential()
model.add(layers.Dense(32, activation='relu'))
model.add(layers.Dense(32, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
model.compile(optimizer=tf.keras.optimizers.Adam(0.001),
loss=tf.keras.losses.categorical_crossentropy,
metrics=[tf.keras.metrics.categorical_accuracy])
3.2输入Numpy数据
import numpy as np
train_x = np.random.random((1000, 72))
train_y = np.random.random((1000, 10))
val_x = np.random.random((200, 72))
val_y = np.random.random((200, 10))
model.fit(train_x, train_y, epochs=10, batch_size=100,
validation_data=(val_x, val_y))
3.2.1fit参数详解
network.fit( x, y,
batch_size=32, epochs=10, verbose=1, callbacks=None,
validation_split=0.0, validation_data=None,
shuffle=True, class_weight=None,
sample_weight=None, initial_epoch=0)
x:输入数据。如果模型只有一个输入,那么x的类型是numpy
array,如果模型有多个输入,那么x的类型应当为list,list的元素是对应于各个输入的numpy array
y:标签,numpy array
batch_size:整数,指定进行梯度下降时每个batch包含的样本数。训练时一个batch的样本会被计算一次梯度下降,使目标函数优化一步。
epochs:整数,训练终止时的epoch值,训练将在达到该epoch值时停止,当没有设置initial_epoch时,它就是训练的总轮数,否则训练的总轮数为epochs - inital_epoch
verbose:日志显示,0为不在标准输出流输出日志信息,1为输出进度条记录,2为每个epoch输出一行记录
callbacks:list,其中的元素是keras.callbacks.Callback的对象。这个list中的回调函数将会在训练过程中的适当时机被调用,参考回调函数
validation_split:0~1之间的浮点数,用来指定训练集的一定比例数据作为验证集。验证集将不参与训练,并在每个epoch结束后测试的模型的指标,如损失函数、精确度等。注意,validation_split的划分在shuffle之前,因此如果你的数据本身是有序的,需要先手工打乱再指定validation_split,否则可能会出现验证集样本不均匀。
validation_data:形式为(X,y)的tuple,是指定的验证集。此参数将覆盖validation_spilt。
shuffle:布尔值或字符串,一般为布尔值,表示是否在训练过程中随机打乱输入样本的顺序。若为字符串“batch”,则是用来处理HDF5数据的特殊情况,它将在batch内部将数据打乱。
class_weight:字典,将不同的类别映射为不同的权值,该参数用来在训练过程中调整损失函数(只能用于训练)
sample_weight:权值的numpy array,用于在训练时调整损失函数(仅用于训练)。可以传递一个1D的与样本等长的向量用于对样本进行1对1的加权,或者在面对时序数据时,传递一个的形式为(samples,sequence_length)的矩阵来为每个时间步上的样本赋不同的权。这种情况下请确定在编译模型时添加了sample_weight_mode=’temporal’。
initial_epoch: 从该参数指定的epoch开始训练,在继续之前的训练时有用。
返回值
fit函数返回一个History的对象,其History.history属性记录了损失函数和其他指标的数值随epoch变化的情况,如果有验证集的话,也包含了验证集的这些指标变化情况
3.3tf.data输入数据
dataset = tf.data.Dataset.from_tensor_slices((train_x, train_y))
dataset = dataset.batch(32)
dataset = dataset.repeat()
val_dataset = tf.data.Dataset.from_tensor_slices((val_x, val_y))
val_dataset = val_dataset.batch(32)
val_dataset = val_dataset.repeat()
model.fit(dataset, epochs=10, steps_per_epoch=30,
validation_data=val_dataset, validation_steps=3)
3.3.1构造dataset
tf.data.Dataset.from_tensors((features, labels)) #从一个tensor tuple创建一个单元素的dataset
tf.data.Dataset.from_tensor_slices((features, labels)) #创建一个包含多个元素的dataset
tf.data.TextLineDataset(filenames) #读取一个文件名列表,将每个文件中的每一行作为一个元素
tf.data.TFRecordDataset(filenames) #读取硬盘中的TFRecord格式文件,构造dataset
dataset.map(lambda x: tf.decode_jpeg(x)) #用map对dataset中的每个元素进行处理
dataset.repeat(NUM_EPOCHS) #将dataset重复一定数目的次数用于多个epoch的训练
dataset.batch(BATCH_SIZE) #将原来的dataset中的元素按照某个数量叠在一起,生成mini batch
数据集定义好后,相应的采用迭代器访问数据,由简单到复杂,主要有以下几种迭代器
1、one-shot
2、initializable
3、reinitializable
4、feedable
one-shot
代码实例如下:
dataset = tf.data.Dataset.from_tensor_slices(data)
dataset.batch(128)
iterator = dataset.make_one_shot_iterator()
next_element = iterator.get_next()
for i in range(epoch):
try:
sess.run(next_element)
except tf.errors.OutOfRangeError: #数据遍历一遍结束
...
initializable
使用之前显式的通过调用iterator.initializer操作初始化,这使得在定义数据集时可以结合tf.placeholder传入参数
max_value = tf.placeholder(tf.int64, shape=[])
dataset = tf.data.Dataset.range(max_value)
iterator = dataset.make_initializable_iterator()
next_element = iterator.get_next()
#Initialize an iterator over a dataset with 10 elements.
sess.run(iterator.initializer, feed_dict={max_value: 10})
for i in range(10):
value = sess.run(next_element)
assert i == value
#Initialize the same iterator over a dataset with 100 elements.
sess.run(iterator.initializer, feed_dict={max_value: 100})
for i in range(100):
value = sess.run(next_element)
assert i == value
reinitializable
reinitializable iterator 可以被不同的 dataset 对象初始化,比如对于训练集进行了shuffle的操作,对于验证集则没有处理,通常这种情况会使用两个具有相同结构的dataset对象,很常用
training_dataset = tf.data.Dataset.range(100).map(lambda x: x + tf.random_uniform([], -10, 10, tf.int64))
validation_dataset = tf.data.Dataset.range(50)
iterator = tf.Iterator.from_structure(training_dataset.output_types,training_dataset.output_shapes)
next_element = iterator.get_next()
training_init = iterator.make_initializer(training_dataset)
validation_init = iterator.make_initializer(validation_dataset)
for _ in range(epoch):
sess.run(training_init_op) #train初始化
try:
sess.run(next_element)
except tf.errors.OutOfRangeError:
...
sess.run(validation_init_op) #test初始化
try:
sess.run(next_element)
except tf.errors.OutOfRangeError:
...
feedable
feedable iterator 可以通过和tf.placeholder结合在一起,同通过feed_dict机制来选择在每次调用tf.Session.run的时候选择哪种Iterator。
training_dataset = tf.data.Dataset.range(100).map( lambda x: x + tf.random_uniform([], -10, 10, tf.int64)).repeat()
validation_dataset = tf.data.Dataset.range(50)
handle = tf.placeholder(tf.string, shape=[])
iterator = tf.data.Iterator.from_string_handle(handle, training_dataset.output_types, training_dataset.output_shapes)
next_element = iterator.get_next()
training_iterator = training_dataset.make_one_shot_iterator()
validation_iterator = validation_dataset.make_initializable_iterator()
training_handle = sess.run(training_iterator.string_handle())
validation_handle = sess.run(validation_iterator.string_handle())
while True:
for _ in range(200):
sess.run(next_element, feed_dict={handle: training_handle})
sess.run(validation_iterator.initializer)
for _ in range(50):
sess.run(next_element, feed_dict={handle: validation_handle})
3.4评估与预测
test_x = np.random.random((1000, 72))
test_y = np.random.random((1000, 10))
model.evaluate(test_x, test_y, batch_size=32)
test_data = tf.data.Dataset.from_tensor_slices((test_x, test_y))
test_data = test_data.batch(32).repeat()
model.evaluate(test_data, steps=30)
# predict
result = model.predict(test_x, batch_size=32)
print(result)
model.evaluate 该函数第一个返回值是损失(loss),第二个返回值是准确率(acc)。可以通过打印model.metrics_names来查看
3.5 Sequential模型线性回归实战
# -*- coding: utf-8 -*-
import tensorflow as tf
from tensorflow.keras import layers
import numpy as np
import matplotlib.pyplot as plt
#创建训练数据
trX = np.linspace(-1, 1, 101)
#TrainY的值为TrainX的三倍,增加了一些随机扰动
trY = 3 * trX + np.random.randn(*trX.shape) * 0.33
#创建Sequential模型
model = tf.keras.Sequential()
model.add(layers.Dense(1,input_dim=1))
#创建一个Sequential模型,这里使用了一个采用线性激活的全连接(Dense)层。它实际上封装了输入值x乘以权重w,加上偏置(bias)b,然后进行线性激活以产生输出。
weights = model.layers[0].get_weights()
w_init = weights[0][0][0]
b_init = weights[1][0]
#查看默认初始化的权重和偏置值
print('Linear regression model is initialized with weights w: %.2f, b: %.2f' % (w_init, b_init))
#选择优化器和损失函数
model.compile(optimizer='sgd', loss='mse')
#训练模型
model.fit(trX, trY, epochs=5000)
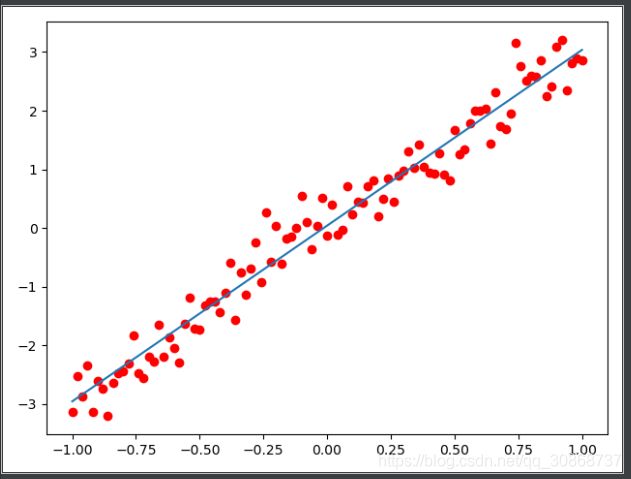
plt.scatter(trX,trY,c='r')
plt.plot(trX,model.predict(trX))
plt.show()
#评估与预测
test_x = np.linspace(1, 3, 101)
#TrainY的值为TrainX的三倍,增加了一些随机扰动
test_y = 3 * trX + np.random.randn(*trX.shape) * 0.33
score = model.evaluate(test_x, test_y, batch_size=32)
print(model.metrics_names)
print(score)
#再看看权重值和偏置值
weights = model.layers[0].get_weights()
w_final = weights[0][0][0]
b_final = weights[1][0]
print('Linear regression model is trained to have weight w: %.2f, b: %.2f' % (w_final, b_final))
#可以尝试修改迭代次数,看看不同迭代次数下得到的权重值
[‘loss’]
36.2089958190918
Linear regression model is trained to have weight w: 3.00, b: 0.04
4.构建高级模型
4.1函数式api
tf.keras.Sequential 模型是层的简单堆叠,无法表示任意模型。使用 Keras 函数式 API 可以构建复杂的模型拓扑,例如:
多输入模型,
多输出模型,
具有共享层的模型(同一层被调用多次),
具有非序列数据流的模型(例如,残差连接)。
使用函数式 API 构建的模型具有以下特征:
层实例可调用并返回张量。 输入张量和输出张量用于定义 tf.keras.Model 实例。 此模型的训练方式和 Sequential 模型一样。
input_x = tf.keras.Input(shape=(72,))
hidden1 = layers.Dense(32, activation='relu')(input_x)
hidden2 = layers.Dense(16, activation='relu')(hidden1)
pred = layers.Dense(10, activation='softmax')(hidden2)
model = tf.keras.Model(inputs=input_x, outputs=pred)
model.compile(optimizer=tf.keras.optimizers.Adam(0.001),
loss=tf.keras.losses.categorical_crossentropy,
metrics=['accuracy'])
model.fit(train_x, train_y, batch_size=32, epochs=5)
4.1.2 tf.keras.Input函数
tf.keras.Input函数用于向模型中输入数据,并指定数据的形状、数据类型等信息。其实这个函数的参数中,batch_size和sparse的意义我还没有太理解,不知道这里指定的batch_size会对后面的模型训练产生什么影响以及指定创建的占位符是否稀疏的意义。
首先给出tf.keras.Input的函数定义:
tf.keras.Input(
shape=None,
batch_size=None,
name=None,
dtype=None,
sparse=False,
tensor=None,
**kwargs
)
其中各个参数的含义为:
shape:一个形状元组(由整数组成),其中并不指定batch size,只是定义输入的数据的形状。比如shape=(32, )和shape=32是等价的,表示输入都为32维的向量。
batch_size: 这是一个可选的参数,表示静态的batch size大小
name:可选参数,字符串形式表示当前层的名字。如果没有这个参数的话,会自动生成。
dtype:数据类型
一般包括以下几种:
有符号整型 tf.int8 8位整数
tf.int16 16位整数
tf.int32 32位整数
tf.int64 64位整数
无符号整数 tf.uint8 8位无符号整数
tf.uint16 16位无符号整数
浮点型 tf.float16 16位浮点数
tf.float32 32位浮点数
tf.float64 64位浮点数
tf.double 和tf.float64等价
字符串型 tf.string 字符串
布尔型 tf.bool 布尔型
复数型 tf.complex64 64位复数
tf.complex128 128位复数
sparse:一个布尔值,指示创建的占位符是否是稀疏的。
tensor:将现有张量wrap到Input层中,如果设置了的话,Input层将不会创建占位符张量(可以理解为张量是已有的,所以不需要创建新的占位符)
**kwargs:当前并不支持的参数
以下为一个实例:
# this is a logistic regression in Keras
x = Input(shape=(32,))
y = Dense(16, activation='softmax')(x)
model = Model(x, y)
4.2模型子类化
其实所谓的“模型子类化”就是自己实现一个类来继承Model类,构建一个Model类的子类,需要实现三个方法,即:
__init__()
call()
compute_output_shape()
通过对 tf.keras.Model 进行子类化并定义您自己的前向传播来构建完全可自定义的模型。在 init 方法中创建层并将它们设置为类实例的属性;在 call 方法中定义前向传播;在compute_output_shape计算模型输出的形状。
注意:这里其实和自定义实现一个层很类似,自定义层也是实现三个方法,分别是:
build(input_shape):
call(x):
compute_output_shape(input_shape):
在启用 Eager Execution 时,模型子类化特别有用,因为可以命令式地编写前向传播。
要点:针对作业使用正确的 API。虽然模型子类化较为灵活,但代价是复杂性更高且用户出错率更高。如果可能,请首选函数式 API。
通过对 tf.keras.Model 进行子类化并定义您自己的前向传播来构建完全可自定义的模型。在 init 方法中创建层并将它们设置为类实例的属性。在 call 方法中定义前向传播
class MyModel(tf.keras.Model): # 自定义模型继承Model
def __init__(self, num_classes=10):
super(MyModel, self).__init__(name='my_model')
self.num_classes = num_classes
# 定义这个模型中的层
self.layer1 = layers.Dense(32, activation='relu')
self.layer2 = layers.Dense(num_classes, activation='softmax')
def call(self, inputs):
# 定义数据的前向传播
h1 = self.layer1(inputs)
out = self.layer2(h1)
return out
def compute_output_shape(self, input_shape):
# 如果想要使用定义的子类,则需要重载此方法,计算模型输出的形状
shape = tf.TensorShape(input_shape).as_list()
shape[-1] = self.num_classes
return tf.TensorShape(shape)
model = MyModel(num_classes=10)
model.compile(optimizer=tf.keras.optimizers.RMSprop(0.001),
loss=tf.keras.losses.categorical_crossentropy,
metrics=['accuracy'])
model.fit(train_x, train_y, batch_size=16, epochs=5)
4.3自定义层
通过对 tf.keras.layers.Layer 进行子类化并实现以下方法来创建自定义层:
build:创建层的权重。使用 add_weight 方法添加权重。
call:定义前向传播。
compute_output_shape:指定在给定输入形状的情况下如何计算层的输出形状。 或者,可以通过实现 get_config 方法和 from_config 类方法序列化层。
class MyLayer(layers.Layer):
def __init__(self, output_dim, **kwargs):
self.output_dim = output_dim
super(MyLayer, self).__init__(**kwargs)
def build(self, input_shape):
shape = tf.TensorShape((input_shape[1], self.output_dim))
self.kernel = self.add_weight(name='kernel1', shape=shape,
initializer='uniform', trainable=True)
super(MyLayer, self).build(input_shape)
def call(self, inputs):
return tf.matmul(inputs, self.kernel)
def compute_output_shape(self, input_shape):
shape = tf.TensorShape(input_shape).as_list()
shape[-1] = self.output_dim
return tf.TensorShape(shape)
def get_config(self):
base_config = super(MyLayer, self).get_config()
base_config['output_dim'] = self.output_dim
return base_config
@classmethod
def from_config(cls, config):
return cls(**config)
model = tf.keras.Sequential(
[
MyLayer(10),
layers.Activation('softmax')
])
model.compile(optimizer=tf.keras.optimizers.RMSprop(0.001),
loss=tf.keras.losses.categorical_crossentropy,
metrics=['accuracy'])
model.fit(train_x, train_y, batch_size=16, epochs=5)
4.4回调
我们之前训练的过程是先训练一遍,然后得到一个验证集的识别率变化趋势,从而知道最佳的epoch,设置epoch,再训练一遍,得到最终结果,这样很浪费时间。
一个好方法就是在测试识别率不再上升的时候,我们终止训练就可以了,callback可以帮助我们做到这一点,callback是一个obj类型的,它可以让模型去拟合,也常在各个点被调用。它和所有模型的状态和表现的数据,能够采取措施打断训练,保存模型,加载不同的权重,或者替代模型状态。
callbacks可以用来做这些事情:
模型断点续训:保存当前模型的所有权重
提早结束:当模型的损失不再下降的时候就终止训练,当然,会保存最优的模型。
动态调整训练时的参数,比如优化的学习速度。
等等
callbacks = [
tf.keras.callbacks.EarlyStopping(patience=2, monitor='acc'),
tf.keras.callbacks.ModelCheckpoint(filepath='my_model.h5',monitor='val_loss',save_best_only=True),
tf.keras.callbacks.TensorBoard(log_dir='./logs')
]
model.fit(train_x, train_y, batch_size=16, epochs=5,
callbacks=callbacks, validation_data=(val_x, val_y))
monitor为选择的检测指标,我们这里选择检测’acc’识别率为指标,patience就是我们能让训练停止变好多少epochs才终止训练,这里选择了1,而modelcheckpoint就起到了存储最优的模型的作用,filepath为我们存储的位置和模型名称,以.h5为后缀,monitor为检测的指标,这里我们检测验证集里面的成功率,save_best_only代表我们只保存最优的训练结果。
而validation_data就是给定的验证集数据。
学习率减少callback
callbacks_list = [
keras.callbacks.ReduceLROnPlateau(
# This callback will monitor the validation loss of the model
monitor='val_loss',
# It will divide the learning by 10 when it gets triggered
factor=0.1,
# It will get triggered after the validation loss has stopped improving
# for at least 10 epochs
patience=10,
)
]# Note that since the callback will be monitor validation loss,
# we need to pass some `validation_data` to our call to `fit`.
model.fit(x, y,
epochs=10,
batch_size=32,
callbacks=callbacks_list,
validation_data=(x_val, y_val))
翻译一下,就是如果连续10个批次,val_loss不再下降,就把学习率弄到原来的0.1倍。
5保持和恢复
5.1权重保存
model = tf.keras.Sequential([
layers.Dense(64, activation='relu'),
layers.Dense(10, activation='softmax')])
model.compile(optimizer=tf.keras.optimizers.Adam(0.001),
loss='categorical_crossentropy',
metrics=['accuracy'])
model.save_weights('./weights/model')
model.load_weights('./weights/model')
model.save_weights('./model.h5')
model.load_weights('./model.h5')
5.2保存网络结构
# 序列化成json
import json
import pprint
json_str = model.to_json()
pprint.pprint(json.loads(json_str))
fresh_model = tf.keras.models.model_from_json(json_str)
# 保持为yaml格式 #需要提前安装pyyaml
yaml_str = model.to_yaml()
print(yaml_str)
fresh_model = tf.keras.models.model_from_yaml(yaml_str)
5.3保存整个模型
model = tf.keras.Sequential([
layers.Dense(10, activation='softmax', input_shape=(72,)),
layers.Dense(10, activation='softmax')
])
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(train_x, train_y, batch_size=32, epochs=5)
model.save('all_model.h5')
model = tf.keras.models.load_model('all_model.h5')
6.将keras用于Estimator
Estimator API 用于针对分布式环境训练模型。它适用于一些行业使用场景,例如用大型数据集进行分布式训练并导出模型以用于生产
model = tf.keras.Sequential([layers.Dense(10,activation='softmax'),
layers.Dense(10,activation='softmax')])
model.compile(optimizer=tf.keras.optimizers.RMSprop(0.001),
loss='categorical_crossentropy',
metrics=['accuracy'])
estimator = tf.keras.estimator.model_to_estimator(model)