从虚拟内存到物理内存
原本打算针对Linux内存管理写一篇长文,准备了快一个月了,发现这里的内容实在太丰富,不是一篇能够讲解清楚的,于是作罢,还是多写几篇吧。这是第一篇,解释一下Linux从虚拟内存到物理内存的转换。
绝大部分现代操作系统是运行在所谓的“保护模式”下的,所谓“保护模式”是相对于“实模式”来说的,在上古时代,操作系统是直接访问的物理内存,所有进程都是访问的同一个地址空间,相互之间可以访问对方的数据。这样的工作方式,需要使用复杂的方式来安排各个进程的内存,非常不方便。另外,进程间可以随意访问对方的数据,这样也很不安全。
后来出现了保护模式,在此模式下,进程都有自己独立的内存地址空间,相互之间有一定的隔离性(在内核态还是互通的),进程自己的虚拟地址通过页表翻译映射到实际的物理地址。同时,内存在分配时,可以只分配虚拟内存,等到程序实际需要使用到的时候,再通过缺页错误分配实际的物理内存,提高了内存的使用效率。这种方式实际上印证了,计算机领域一项常见的模式,即通过引入一个中间层来解决问题,使用了页表,将程序使用的虚拟内存空间与物理内存空间进行了解耦。
分页和页表
还是从分页开始说吧,操作系统对内存进行管理有分段和分页两种方式,在Linux中,这两种实际上都有用到。所谓分页,就是把物理内存空间切割成多个固定大小的区域,实际使用时,每次分配一页或者多页使用。而页表是用来负责进行虚拟内存到物理内存的转换的。在Linux中,进程的地址空间是相互隔离的,每个进程都会有其自己的页表项。正常情况下,Linux系统的一页大小是4KB(212),假设一个进程使用4GB地址空间(32位情况下,64位情况下只会更多),如果只使用一级页表,那边这个进程会有(232 >> 12 = 2^20)个页表项,这是一个非常巨大的数字,实际情况尤其是在64位系统中,用户进程并不会使用到全部的虚拟空间,并不需要如此多的页表项。
在x86_64的Linux系统中,内存地址有48位(一个长整型是64位,在多余的位上,用户态为全0,内核态是全1,实际使用中,内核态和用户态地址之间还存在一个巨大的空洞),使用了4级页表来管理进程的虚拟内存。
| 页表类型 | 位数 |
|---|---|
| PGD(全局页描述符) | 9 |
| PUD(上层页描述符) | 9 |
| PMD(中层页描述符) | 9 |
| PTE(页表项) | 9 |
| offset(页内偏移) | 12 |
进程的虚拟地址被分成了5个部分来使用,如下图所示:
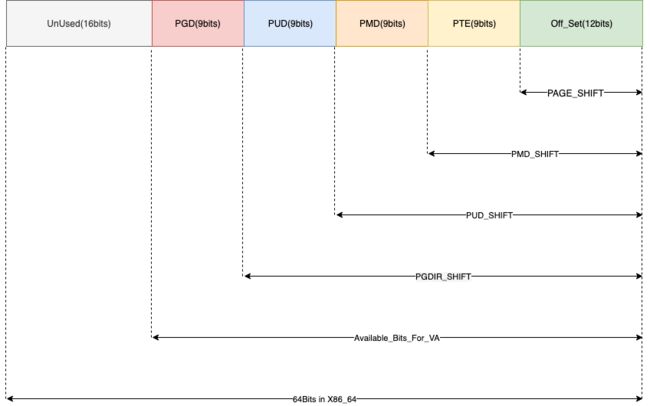
在x86_64系统中,虚拟地址是64bits长,使用一个unsigned long类型来表示,最高位的16个字节目前没有使用。(在内核态这16位全部置为1---0xFFFF,而在用户态则置为0,因此,属于内核态和用户态的虚拟内存地址是很方便判断的),那么通过将虚拟地址右移的方式,就可以获得虚拟地址在各层页表中的偏移。
比如,如果我们要获取一个虚拟地址对应的PGD项,我们首先,将虚拟地址右移PGDIR_SHITF位(12+9+9+9=39),然后保留需要的位数(PGD占用9位,可以索引2^9即512个PGD项),这样我们获得了这个虚拟地址在PGD表中的索引。根据这个索引,再从这个进程相关的pgd中去获取相关的页表项。
#define PGDIR_SHIFT 39
#define PTRS_PER_PGD 512
/*
* the pgd page can be thought of an array like this: pgd_t[PTRS_PER_PGD]
*
* this macro returns the index of the entry in the pgd page which would
* control the given virtual address
*/
#define pgd_index(address) (((address) >> PGDIR_SHIFT) & (PTRS_PER_PGD - 1))
/*
* pgd_offset() returns a (pgd_t *)
* pgd_index() is used get the offset into the pgd page's array of pgd_t's;
*/
#define pgd_offset(mm, address) ((mm)->pgd + pgd_index((address)))
此时,我们获得的这个pgd项中,存储的是对应的pud表的页框。要获得pud表中对应的表项,需要进行和之前类似的操作,获取pud表中的索引,与pud表的虚拟地址相加获得对应PUD项。
/*
* 3rd level page
*/
#define PUD_SHIFT 30
#define PTRS_PER_PUD 512
#define pgd_val(x) native_pgd_val(x)
static inline pgdval_t native_pgd_val(pgd_t pgd)
{
return pgd.pgd;
}
#define PAGE_OFFSET ((unsigned long)__PAGE_OFFSET)
#define __PAGE_OFFSET_BASE _AC(0xffff880000000000, UL)
#ifdef CONFIG_RANDOMIZE_MEMORY
#define __PAGE_OFFSET page_offset_base
#else
#define __PAGE_OFFSET __PAGE_OFFSET_BASE
#endif /* CONFIG_RANDOMIZE_MEMORY */
#ifndef __va
#define __va(x) ((void *)((unsigned long)(x)+PAGE_OFFSET))
#endif
static inline unsigned long pgd_page_vaddr(pgd_t pgd)
{
return (unsigned long)__va((unsigned long)pgd_val(pgd) & PTE_PFN_MASK);
}
static inline unsigned long pud_index(unsigned long address)
{
return (address >> PUD_SHIFT) & (PTRS_PER_PUD - 1);
}
static inline pud_t *pud_offset(pgd_t *pgd, unsigned long address)
{
return (pud_t *)pgd_page_vaddr(*pgd) + pud_index(address);
}
下面轮到pmd了,其实也是类似的:
#define PMD_SHIFT 21
#define PTRS_PER_PMD 512
#define PMD_SIZE (_AC(1, UL) << PMD_SHIFT)
#define PMD_MASK (~(PMD_SIZE - 1))
static inline pudval_t pud_pfn_mask(pud_t pud)
{
if (native_pud_val(pud) & _PAGE_PSE)
return PHYSICAL_PUD_PAGE_MASK;
else
return PTE_PFN_MASK;
}
static inline unsigned long pud_page_vaddr(pud_t pud)
{
return (unsigned long)__va(pud_val(pud) & pud_pfn_mask(pud));
}
/*
* the pmd page can be thought of an array like this: pmd_t[PTRS_PER_PMD]
*
* this macro returns the index of the entry in the pmd page which would
* control the given virtual address
*/
static inline unsigned long pmd_index(unsigned long address)
{
return (address >> PMD_SHIFT) & (PTRS_PER_PMD - 1);
}
static inline pmd_t *pmd_offset(pud_t *pud, unsigned long address)
{
return (pmd_t *)pud_page_vaddr(*pud) + pmd_index(address);
}
最后终于到页表项了
/*
* the pte page can be thought of an array like this: pte_t[PTRS_PER_PTE]
*
* this function returns the index of the entry in the pte page which would
* control the given virtual address
*/
static inline unsigned long pte_index(unsigned long address)
{
return (address >> PAGE_SHIFT) & (PTRS_PER_PTE - 1);
}
static inline pte_t *pte_offset_kernel(pmd_t *pmd, unsigned long address)
{
return (pte_t *)pmd_page_vaddr(*pmd) + pte_index(address);
}
从上面的过程,我们可以看出整个内存访问过程如下:
- PGD--->PUD
- PUD--->PMD
- PMD--->PTE
- PTE--->物理内存页框
- 物理页框地址加上页内偏移得到物理地址
整个地址翻译过程访问了4次内存,如果没有一些加速的手段,这个性能是非常差的。
缓存与TLB
为了加速地址翻译的过程,一般的处理器会使用TLB来缓存虚拟地址的翻译结果。TLB和普通的缓存基本类似,其不同之处在于,因为缓存的是虚拟地址的翻译结果,TLB一定是使用的VIVT(virtual index virtual tag),基于TLB本身的特性,其不存在歧义(存在相同的tag和index)或者别名的情况(同一个物理地址映射到不同的虚拟地址)。究其原因,为了区分不同进程的虚拟地址,TLB又额外使用了ASID(address space id)进行区分。在虚拟地址翻译的过程中,MMU会另外使用ASID进行比对,只有在ASID也相同的情况下。
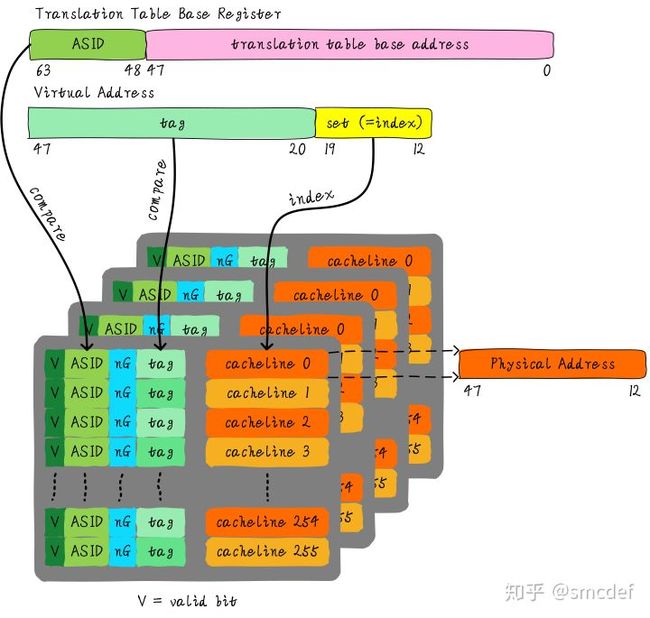
借用网上一张图来进行说明。
MMU在进行地址转译时,会先在TLB中进程查找。由于是页帧的翻译,低12位作为页内偏移,在TLB中是不需要的。在查找TLB时,会使用12-19位作为索引,20-47作为tag进行匹配。除了tag以外还是用了ASID对不同进程的地址空间进行区分,并使用一个比特位对用户态和内核态的内存进行区分,以达到较高的效率。
由于ASID的存在,在进程切换过程中,并不需要将全部TLB进行刷新,只需要在匹配时,比对ASID,将不匹配的行刷新即可。
ASID是使用时动态分配的,一般系统使用8bit或者16bit位进行管理。最多28或者216个ASID,使用位图进行管理。在位图满或者建立页表映射时,进行全部TLB刷新。
页帧和页帧号
在系统中,每个物理页框有一个page结构体对应,所有的这些page结构体是连续存放的(根据物理内存模型不同有所区别,平坦模型是完全连续,非一致内存是Zone内连续,而稀疏模型是section内一致),从内核的角度看,其存放page结构体的内存,是一个struct page结构体,通过其索引号即页帧号,即可访问对应的page结构体。由于page结构体和物理内存是一一对应的,如果获得了页帧号,同样也可算的其物理内存的位置。同时页帧和页帧号是可以相互转换的。
#elif defined(CONFIG_SPARSEMEM_VMEMMAP)
/* memmap is virtually contiguous. */
#define __pfn_to_page(pfn) (vmemmap + (pfn))
#define __page_to_pfn(page) (unsigned long)((page) - vmemmap)
/*
* Convert a physical address to a Page Frame Number and back
*/
#define __phys_to_pfn(paddr) PHYS_PFN(paddr)
#define __pfn_to_phys(pfn) PFN_PHYS(pfn)
后记
越接近底层,接近物理设备,我发现自己的语言描述能力愈发地有些,内存这块已经看了超过一个月了,但是发现自己还是很难用非常恰当的语言对其进行描述。先写成这样吧,后面对这块理解加深后,我可能会回来重新组织语言。