推荐系统论文笔记---Neural News Recommendation with Attentive Multi-View Learning
文章目录
-
-
- 一、概述
- 二、主要解决问题
- 三、解决思路
-
- 1、News Encoder
- 2、User Encoder
- 3、Click Predictor
- 4、Model Training
- 四、实验结果
-
一、概述
名称:Neural News Recommendation with Attentive Multi-View Learning
作者:Chuhan Wu, Fangzhao Wu, Mingxiao An, Jianqiang Huang, Yongfeng Huang, Xing Xie
文献类型:IJCAI19
年份:2019
源码网站:https://github.com/wuch15/IJCAI2019-NAML 作者主页:https://wuch15.github.io/
整理日期:2020年5月13日
二、主要解决问题
现有的新闻推荐系统通常只根据一种信息如标题来进行推荐。
=>使用多种信息来进行推荐。
=>新闻编码器+用户解码器。
=>新闻编码器是一个基于attention的multi-view学习模型,可以学习多种新闻表示形式(如标题、正文、主题分类等)。用户解码器是利用attention机制根据用户的浏览记录学习用户的表示。
三、解决思路
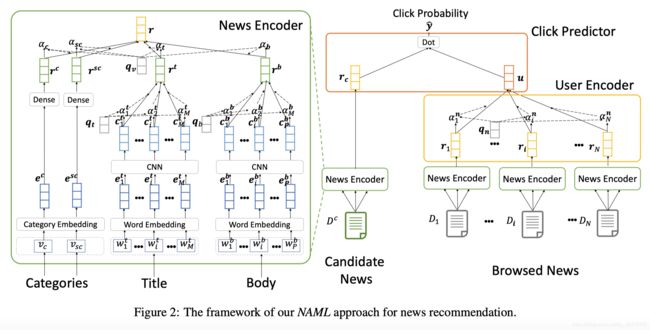
1、News Encoder
这一部分的功能是利用各种信息来学习新闻的表示,采用attention机制将各种信息看作是新闻的一个不同视角学习其共同表示。news encoder共有四个组成部分:
(1)title encoder:用于从新闻标题中学习到新闻的表示。
- 第一层:word embedding:通过 W e ∈ R V × D \mathbf{W}_e \in R^{V \times D} We∈RV×D,将新闻标题从单词序列 [ w 1 t , w 2 t , . . . , w M t ] [w^t_1, w^t_2, ..., w^t_M] [w1t,w2t,...,wMt]转换为一个低维语义向量序列 [ e 1 t , e 2 t , . . . , e M t ] [\mathbf{e}^t_1,\mathbf{e}^t_2, ..., \mathbf{e}^t_M] [e1t,e2t,...,eMt],其中M是新闻单词的个数,V是词汇量个数,D是embedding维度。
- 第二层:CNN:通过CNN来学习单词间上下文的表示,第i个单词的上下文表示为:
c i t = R e L U ( F t × e ( i − K ) : ( i + K ) t + b t ) \mathbf{c}^t_i = ReLU(\mathbf{F}_t \times \mathbf{e}^t_{(i-K):(i+K)} + \mathbf{b}_t) cit=ReLU(Ft×e(i−K):(i+K)t+bt)
其中, e ( i − K ) : ( i + K ) t \mathbf{e}^t_{(i-K):(i+K)} e(i−K):(i+K)t是(i-K)到(i+K)的单词embedding的拼接, F t ∈ R N f × ( 2 K + 1 ) D \mathbf{F}_t \in R^{N_f \times (2K + 1)D} Ft∈RNf×(2K+1)D和 b t ∈ R N f \mathbf{b}_t \in R^{N_f} bt∈RNf是CNN的核函数和偏移量, N f N_f Nf是CNN的个数,2K+1是他们的窗口大小。
这一层的输出是单词上下文表示的序列: [ c 1 t , c 2 t , . . . , c M t ] [\mathbf{c}^t_1, \mathbf{c}^t_2, ..., \mathbf{c}^t_M] [c1t,c2t,...,cMt]。 - 第三层:word-level attention network:目的是选择出标题中重要的单词。第i个单词的attention权重 α i t \alpha^t_i αit计算如下:
a i t = q t T t a n h ( V t × c i t + v t ) α i t = e x p ( a i t ) ∑ j = 1 M e x p ( a j t ) a^t_i = \mathbf{q}^T_t tanh(\mathbf{V}_t \times \mathbf{c}^t_i + \mathbf{v}_t) \\ \alpha^t_i = \frac{exp(a^t_i)}{\sum^M_{j=1} exp(a^t_j)} ait=qtTtanh(Vt×cit+vt)αit=∑j=1Mexp(ajt)exp(ait)
其中, V t \mathbf{V}_t Vt和 v t \mathbf{v}_t vt是投影参数, q t \mathbf{q}_t qt是attention中的query向量。 - 最终,新闻标题的表示形式为加权上下文表示: r t = ∑ j = 1 M α j t c j t \mathbf{r}_t = \sum^M_{j=1}\alpha^t_j \mathbf{c}^t_j rt=∑j=1Mαjtcjt
(2)body encoder:用于从新闻正文中学习到新闻的表示。同title encoder类似。
- 第一层:word embedding:同title encoder的word embedding层一致。通过 W e ∈ R V × D \mathbf{W}_e \in R^{V \times D} We∈RV×D,正文的单词序列 [ w 1 b , w 2 b , . . . , w P b ] [w^b_1, w^b_2, ..., w^b_P] [w1b,w2b,...,wPb]转换为一个低维向量序列 [ e 1 b , e 2 b , . . . , e P b ] [\mathbf{e}^b_1, \mathbf{e}^b_2, ..., \mathbf{e}^b_P] [e1b,e2b,...,ePb],其中,P是正文的长度。
- 第二层:CNN:从 [ e 1 b , e 2 b , . . . , e P b ] [\mathbf{e}^b_1, \mathbf{e}^b_2, ..., \mathbf{e}^b_P] [e1b,e2b,...,ePb]中学习到上下文表示 [ c 1 b , c 2 b , . . . , c P b ] [\mathbf{c}^b_1, \mathbf{c}^b_2, ..., \mathbf{c}^b_P] [c1b,c2b,...,cPb]
- 第三层:attention network:目的是选择出正文中重要的单词。第i个单词的attention权重 α i b \alpha^b_i αib计算如下:
a i b = q b T t a n h ( V b × c i b + v b ) α i b = e x p ( a i b ) ∑ j = 1 P e x p ( a j b ) a^b_i = \mathbf{q}^T_b tanh(\mathbf{V}_b \times \mathbf{c}^b_i + \mathbf{v}_b) \\ \alpha^b_i = \frac{exp(a^b_i)}{\sum^P_{j=1} exp(a^b_j)} aib=qbTtanh(Vb×cib+vb)αib=∑j=1Pexp(ajb)exp(aib)
其中, V b \mathbf{V}_b Vb和 v b \mathbf{v}_b vb是投影参数, q b \mathbf{q}_b qb是attention中的query向量。 - 最终,新闻正文的表示形式为加权上下文表示: r b = ∑ j = 1 P α j b c j b \mathbf{r}_b = \sum^P_{j=1}\alpha^b_j \mathbf{c}^b_j rb=∑j=1Pαjbcjb
(3)category encoder:用于从新闻类别中学习到新闻的表示。
catogory encoder的输入是一级分类 v c v_c vc的ID和二级分类 v s c v_{sc} vsc的ID。category encoder有两层。
- 第一层:分类ID embedding层。将离散的一级分类和二级分类ID转换到低维空间 e c \mathbf{e}^c ec和 e s c \mathbf{e}^{sc} esc。
- 第二层:dense层,获得一级分类和二级分类的表示:
r c = R e L U ( V v × e c + v c ) r s c = R e L U ( V s × e s c + v s ) \mathbf{r}^c = ReLU(\mathbf{V}_v \times \mathbf{e}^c + \mathbf{v}_c) \\ \mathbf{r}^{sc} = ReLU(\mathbf{V}_s \times \mathbf{e}^{sc} + \mathbf{v}_s) rc=ReLU(Vv×ec+vc)rsc=ReLU(Vs×esc+vs)
其中, V c , v c , V s , v s \mathbf{V}_c, \mathbf{v}_c, \mathbf{V}_s, \mathbf{v}_s Vc,vc,Vs,vs是dense层的参数。
(4)attention pooling:利用attention机制来学习不同信息的权重。标题、正文、一级分类和二级分类的attention权重分别为 α t , α b , α c , α s c \alpha_t, \alpha_b, \alpha_c, \alpha_{sc} αt,αb,αc,αsc, α t \alpha_t αt计算如下(其余同理):
α t = q v T t a n h ( U v × r t + u v ) α t = e x p ( a t ) e x p ( a t ) + e x p ( a b ) + e x p ( a c ) + e x p ( a s c ) \alpha_t = \mathbf{q}^T_v tanh(\mathbf{U}_v \times \mathbf{r}^t + \mathbf{u}_v) \\ \alpha_t = \frac{exp(a_t)}{exp(a_t) + exp(a_b) + exp(a_c) + exp(a_{sc})} αt=qvTtanh(Uv×rt+uv)αt=exp(at)+exp(ab)+exp(ac)+exp(asc)exp(at)
其中, U v \mathbf{U}_v Uv和 u v \mathbf{u}_v uv是投影参数, q v \mathbf{q}_v qv是attention中的query向量。
- news encoder最终的输出是加权的新闻表示形式: r = α c r c + α s c r s c + α t r t + α b r b \mathbf{r} = \alpha_c \mathbf{r}^c + \alpha_{sc} \mathbf{r}^{sc} + \alpha_t \mathbf{r}^t + \alpha_b \mathbf{r}^b r=αcrc+αscrsc+αtrt+αbrb
2、User Encoder
这一部分的目的是从用户历史浏览记录中学习用户的表示。user encoder模块采用attention机制来学习各个浏览记录的权重。
用户浏览过的第i个新闻的attention权重是 α i n \alpha^n_i αin,计算如下:
a i n = q n T t a n h ( W n × r i + b n ) α i n = e x p ( a i n ) ∑ j = 1 N e x p ( a j n ) a^n_i = \mathbf{q}^T_n tanh(\mathbf{W}_n \times \mathbf{r}_i + \mathbf{b}_n) \\ \alpha^n_i = \frac{exp(a^n_i)}{\sum^N_{j=1}exp(a^n_j)} ain=qnTtanh(Wn×ri+bn)αin=∑j=1Nexp(ajn)exp(ain)
其中, q n , W n , b n \mathbf{q}_n, \mathbf{W}_n, \mathbf{b}_n qn,Wn,bn是attention机制的参数。
最终,用户的表示为加权和: u = ∑ i = 1 N α i n r i \mathbf{u} = \sum^N_{i=1} \alpha^n_i \mathbf{r}_i u=∑i=1Nαinri,N是浏览过的新闻总数。
3、Click Predictor
候选新闻 D c D^c Dc的表示为 r c \mathbf{r}_c rc,用户u的表示为u。点击概率 y ^ \hat{y} y^通过候选新闻和用户表示的内积得到: y ^ = u T r c \hat{y} = \mathbf{u}^T\mathbf{r}_c y^=uTrc。
4、Model Training
采用negative samlping技术来进行模型训练。用户浏览过的新闻作为正样本,在同一个session中随机选择K条用户没有点击过的新闻作为负样本,我们可以获得正样本的概率 y ^ + \hat{y}^+ y^+和K个负样本的概率 [ y ^ 1 − , y ^ 2 − , . . . , y ^ K − ] [\hat{y}^-_1,\hat{y}^-_2,...,\hat{y}^-_K] [y^1−,y^2−,...,y^K−]。推荐问题可以转变为K+1-分类问题,使用softmax对这些概率进行正则化得到正样本的后验点击概率:
p i = e x p ( y ^ i + ) e x p ( y ^ i + ) + ∑ j = 1 K e x p ( y ^ i , j − ) p_i = \frac{exp(\hat{y}^+_i)}{exp(\hat{y}^+_i) + \sum^K_{j=1}exp(\hat{y}^-_{i,j})} pi=exp(y^i+)+∑j=1Kexp(y^i,j−)exp(y^i+)
其中, y ^ + \hat{y}^+ y^+是第i个正样本的点击概率分数, y ^ i , j − \hat{y}^-_{i,j} y^i,j−是同第i个正样本处于相同session的第j个负样本的点击概率分数。
最终得到损失函数为:
L = − ∑ i ∈ S l o g ( p i ) L = - \sum_{i \in S} log(p_i) L=−i∈S∑log(pi)
其中,S是正训练样本的集合。
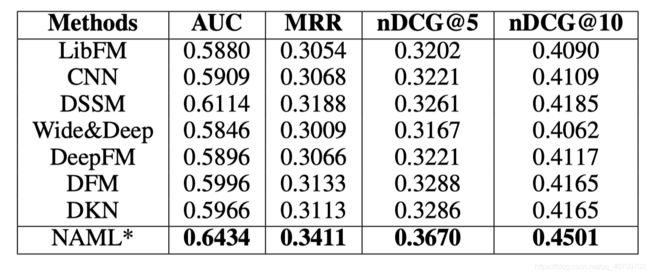
四、实验结果