RDD编程初级实践
RDD编程初级实践
- 一、spark-shell交互式编程
-
- 1.该系总共有多少学生
- 2.该系共开设了多少门课程
- 3.Tom同学的总成绩平均分是多少
- 4.求每名同学的选修的课程门数
- 5.该系DataBase课程共有多少人选修
- 6.各门课程的平均分是多少
- 7.使用累加器计算共有多少人选了DataBase这门课
- 二、编写独立应用程序实现数据去重
- 三、编写独立应用程序实现求平均值问题
一、spark-shell交互式编程
数据集链接:
链接:https://pan.baidu.com/s/1H3EscjvJxpz-kjD11bqUeA
提取码:soi3
数据集包含了某大学计算机系的成绩
文件的上传:
将本机文件拷贝到docker容器中
docker cp Data01.txt master:/home/zf/
![]()
上传本地文件到hdfs
hdfs dfs -mkdir -p /test2
![]()
hdfs dfs -put /home/zf/Data01.txt /test2
![]()
进入spark-shell
spark-shell --master spark://master:7077
根据给定的实验数据,在spark-shell中通过编程来计算以下内容
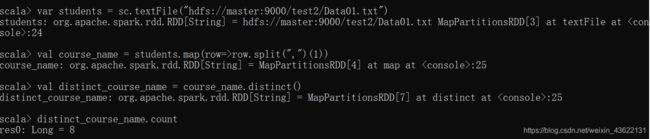
1.该系总共有多少学生
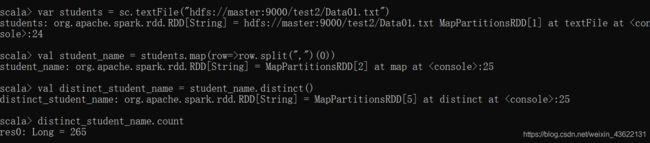
// 从hdfs中读取文件创建RDD
var students = sc.textFile("hdfs://master:9000/test2/Data01.txt")
// 由于要获得学生,而该数据集中唯一标志学生的是学生的名字,所以对RDD每一行进行遍历,将逗号作为分隔符,然后选择分割后的第一个元素,将结果返回为一个新的RDD
val student_name = students.map(row=>row.split(",")(0))
// 对RDD中的元素进行去重
val distinct_student_name = student_name.distinct()
// 返回RDD中的元素个数
distinct_student_name.count
2.该系共开设了多少门课程
类似于第一问
// 从hdfs中读取文件创建RDD
var students = sc.textFile("hdfs://master:9000/test2/Data01.txt")
// 由于要获得课程,将逗号作为分隔符,然后选择分割后的第二个元素,将结果返回为一个新的RDD
val course_name = students.map(row=>row.split(",")(1))
// 对RDD中的元素进行去重
val distinct_course_name = course_name.distinct()
// 返回RDD中的元素个数
distinct_course_name.count
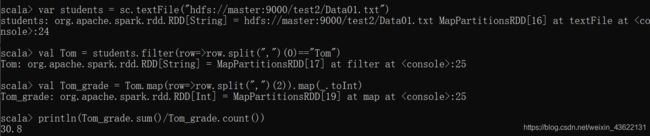
3.Tom同学的总成绩平均分是多少
// 从hdfs中读取文件创建RDD
var students = sc.textFile("hdfs://master:9000/test2/Data01.txt")
// 对RDD进行筛选,选出名字为Tom的
val Tom = students.filter(row=>row.split(",")(0)=="Tom")
// 将Tom每门课的成绩筛选出来作为一个新的RDD并将成绩转换为整数
val Tom_grade = Tom.map(row=>row.split(",")(2)).map(_.toInt)
// 对成绩求和并除上课程数即为平均成绩
println(Tom_grade.sum()/Tom_grade.count())
4.求每名同学的选修的课程门数
// 从hdfs中读取文件创建RDD
var students = sc.textFile("hdfs://master:9000/test2/Data01.txt")
// 将每个同学的名字作为键,每出现一次说明选了一门课,所以将值设为1
val student_grade = students.map(row=>(row.split(",")(0),1))
// 对上述RDD做聚合即可得到每个学生选修的课程门数
val cource_num = student_grade.reduceByKey((x,y)=>x+y)
// 输出每个学生的选课数目
cource_num.collect

5.该系DataBase课程共有多少人选修
// 从hdfs中读取文件创建RDD
var students = sc.textFile("hdfs://master:9000/test2/Data01.txt")
// 筛选出选择数据库课程的学生
val DataBase = students.filter(row=>row.split(",")(1)=="DataBase")
// 对其计数则可得到选数据库课程的人数
DataBase.count

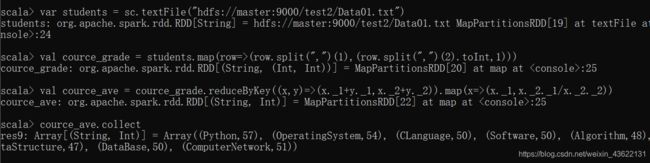
6.各门课程的平均分是多少
// 从hdfs中读取文件创建RDD
var students = sc.textFile("hdfs://master:9000/test2/Data01.txt")
// 将每门课作为键,值为一个键值对,该键值对的键为成绩,值为1(用于后面计算平均值计数用)
val cource_grade = students.map(row=>(row.split(",")(1),(row.split(",")(2).toInt,1)))
// 对上述RDD做聚合,值的聚合返回一个二元组,第一个元素是该门课的成绩求和,第二个元素是选修该门课学生学生的人数,然后再做一个映射,将课程名作为第一个元素,每门课的总成绩除以选修该门课的总人数得到平均成绩作为第二个元素
val cource_ave = cource_grade.reduceByKey((x,y)=>(x._1+y._1,x._2+y._2)).map(x=>(x._1,x._2._1/x._2._2))
// 输出每个学生的选课数目
// 输出各门课程的平均分
cource_ave.collect
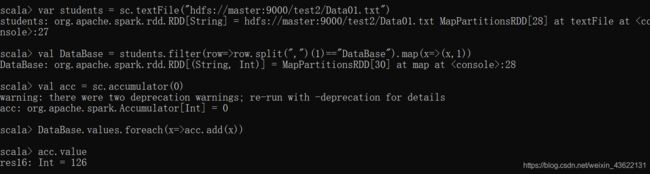
7.使用累加器计算共有多少人选了DataBase这门课
// 从hdfs中读取文件创建RDD
var students = sc.textFile("hdfs://master:9000/test2/Data01.txt")
// 筛选出选择数据库课程的学生,为了能使用累加器,将每个项后面都加个1
val DataBase = students.filter(row=>row.split(",")(1)=="DataBase").map(x=>(x,1))
// 初始化一个累加器
val acc = sc.accumulator(0)
// 通过累加器对选修数据库课程的人数进行累加
DataBase.values.foreach(x=>acc.add(x))
// 输出累加后的人数
acc.value
二、编写独立应用程序实现数据去重
对于两个输入文件A和B,编写Spark独立应用程序,对两个文件进行合并,并剔除其中重复的内容,得到一个新文件C
文件A:
20170101 x
20170102 y
20170103 x
20170104 y
20170105 z
20170106 z
文件B:
20170101 y
20170102 y
20170103 x
20170104 z
20170105 y
合并后的C应该为:
20170101 x
20170101 y
20170102 y
20170103 x
20170104 y
20170104 z
20170105 y
20170105 z
20170106 z
这里使用的是idea连接spark集群,可参考我之前的博客https://blog.csdn.net/weixin_43622131/article/details/110565692
这里为了调试方便,所以选择了local模式(local模式输入路径和输出路径都是本地,standalone模式输入路径在本地,输出路径在spark集群上,也可以使用hdfs的路径)
import java.io.FileWriter
import java.net.InetAddress
import org.apache.spark._
object test2 {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("test2").set("spark.executor.memory", "512m")
// .set("spark.driver.host", "10.0.75.1")
.set("spark.driver.cores", "2")
.setMaster("local") //spark://127.0.0.1:7077
.setJars(List("D:\\自然语言处理\\spark\\out\\artifacts\\SparkExample_jar\\spark.jar")) // maven打的jar包的路径
.set("spark.driver.allowMultipleContexts", "true")
// .set("spark.driver.port","50516")
val sc = new SparkContext(conf)
// 读取文件A
var A = sc.textFile("D:\\spark\\第二次实验\\第二次实验\\test2\\A.txt")
// 读取文件B
var B = sc.textFile("D:\\spark\\第二次实验\\第二次实验\\test2\\B.txt")
// 对文件A和B进行整合并去重
var C = (A ++ B).distinct
// C.saveAsTextFile("D:\\spark\\第二次实验\\第二次实验\\test2\\C")
// println(C.collect().toBuffer)
var results = C.collect()
// 将结果输出到C.txt中
val out = new FileWriter("D:\\spark\\第二次实验\\第二次实验\\test2\\C.txt",true)
for(item<-results){
out.write(item+"\n")
println(item)
}
out.close()
}
}
可以看出结果是正确的
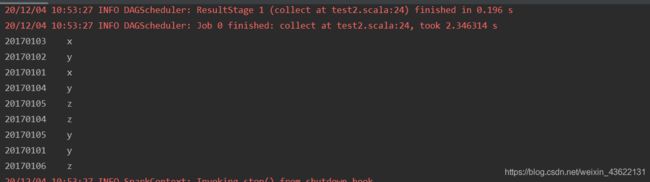
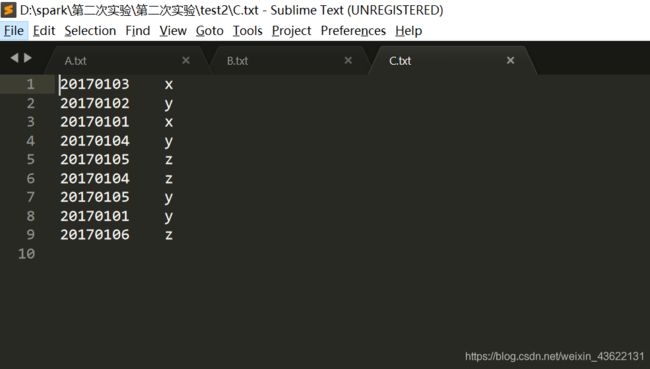
三、编写独立应用程序实现求平均值问题
每个输入文件表示班级学生某个学科的成绩,每行内容由两个字段组成,第一个是学生名字,第二个是学生的成绩;编写Spark独立应用程序求出所有学生的平均成绩,并输出到一个新文件中
Algorithm.txt:
小明 92
小红 87
小新 82
小丽 90
Database.txt:
小明 95
小红 81
小新 89
小丽 85
Python.txt:
小明 82
小红 83
小新 94
小丽 91
输出文件为output.txt:
(小红,83.67)
(小新,88.33)
(小明,89.67)
(小丽,88.67)
import java.io.FileWriter
import java.net.InetAddress
import org.apache.spark._
object test3 {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("test2").set("spark.executor.memory", "512m")
// .set("spark.driver.host", "10.0.75.1")
.set("spark.driver.cores", "2")
.setMaster("local") //spark://127.0.0.1:7077
.setJars(List("D:\\自然语言处理\\spark\\out\\artifacts\\SparkExample_jar\\spark.jar")) // maven打的jar包的路径
.set("spark.driver.allowMultipleContexts", "true")
// .set("spark.driver.port","50516")
val sc = new SparkContext(conf)
// 读取文件Algorithm.txt
var A = sc.textFile("D:\\spark\\第二次实验\\第二次实验\\test3\\Algorithm.txt")
// 读取文件Database.txt"
var B = sc.textFile("D:\\spark\\第二次实验\\第二次实验\\test3\\Database.txt")
// 读取文件Python.txt
var C = sc.textFile("D:\\spark\\第二次实验\\第二次实验\\test3\\Python.txt")
// 对三个文件进行整合
var all = A ++ B ++ C
// // 将每个名字作为键,值为一个键值对,该键值对的键为成绩,值为1(用于后面计算平均值计数用)
val student_grade = all.map(row=>(row.split(" ")(0),(row.split(" ")(1).toInt,1)))
// 对上述RDD做聚合,值的聚合返回一个二元组,第一个元素是该学生所有课的成绩求和,第二个元素是该学生选修课的数目,然后再做一个映射
// 将人名作为第一个元素,所有课的总成绩除以选修课程的数目得到该学生的平均成绩作为第二个元素
val student_ave = student_grade.reduceByKey((x,y)=>(x._1+y._1,x._2+y._2)).map(x=>(x._1,x._2._1/x._2._2))
var results = student_ave.collect
// 将结果输出到output.txt中
val out = new FileWriter("D:\\spark\\第二次实验\\第二次实验\\test3\\output.txt",true)
for(item<-results){
out.write(item+"\n")
println(item)
}
out.close()
}
}