1、 gap statistic
以k-means聚类为例,对于一个聚类个数k,首先利用k-means聚类将样本聚成k类,然后计算k类中各类内各点与类中心的距离加和W(ki),进而计算k类的距离加和W(k)=sum(W(k1),…,W(ki),…,W(kk));根据原始数据的特点产生B个均匀分布的参考数据集,对于每个数据集都计算W(sk),计算B个数据集的平均E.W(k)=mean(W(1k),…,W(sk),…,W(bk));
那么对于每个k就有:gap(k)=log(E.W(k))-log(W(k));然后选取最小的k,使得gap(k)为局部最大值,并且超出了其邻居1个标准差,即gap(k)-gap(k+1)>0.25*sd(W(s(k+1)))
参考文献:Single-cell messenger RNA sequencing reveals rare intestinal celltypes. Nature 2015
这里需要注意的是,gap statistic适用于可以直接设定聚类个数的聚类方法,如k均值和层次聚类,而类似密度聚类和PhenoGraph聚类方法,这两者是用参数(半径,resolution)来划分样本,无法直接设定类别个数。[谨慎!!!可以先调整参数使得得出的聚类个数和该方法得出的结果相同!!!]
2、 Silhouette Coefficient(轮廓系数)
轮廓系数,是聚类效果好坏的一种评价方式。最早由 Peter J. Rousseeuw 在 1986 提出。它结合内聚度和分离度两种因素。可以用来在相同原始数据的基础上评价不同算法、或者算法不同运行方式对聚类结果所产生的影响。
方法:
1. 计算样本i到同簇其他样本的平均距离ai。ai 越小,说明样本i越应该被聚类到该簇。将ai 称为样本i的簇内不相似度。簇C中所有样本的a i 均值称为簇C的簇不相似度。
2. 计算样本i到其他某簇Cj 的所有样本的平均距离bij,称为样本i与簇Cj 的不相似度。定义为样本i的簇间不相似度:bi =min{bi1, bi2, ..., bik}。bi越大,说明样本i越不属于其他簇。
3. 根据样本i的簇内不相似度ai和簇间不相似度bi,定义样本i的轮廓系数:
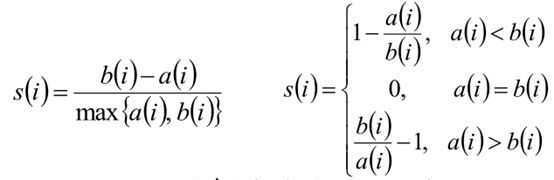
4. 判断:
a) si接近1,则说明样本i聚类合理;
b) si接近-1,则说明样本i更应该分类到另外的簇;
c) 若si近似为0,则说明样本i在两个簇的边界上。
所有样本的si的均值称为聚类结果的轮廓系数,si越大,说明聚类效果越好。
参考自: CSDN
引用文献: Cluster analysis of novel isometric strength measures produces a valid and evidence-based classification structure for wheelchair track racing. (Br J Sports Med. 2018 11.645)
3、 R包mclust
mclust使用高斯混合模型对数据进行聚类分析。具体算法过于复杂,这里不详细解释。mclust包方法有点“暴力”,聚类数目可以自定义,比如选取从1到20,然后一共有14种模型,每一种模型都计算聚类数目从1到20的BIC值,最终确定最佳聚类数目。该方法弊端在于时间消耗特别高。使用的数据为R自带数据集wine。
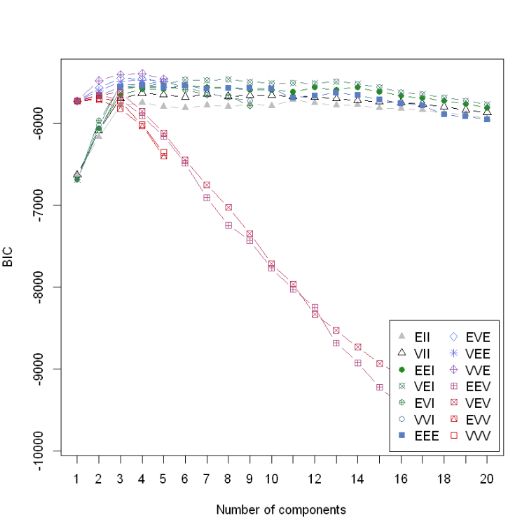
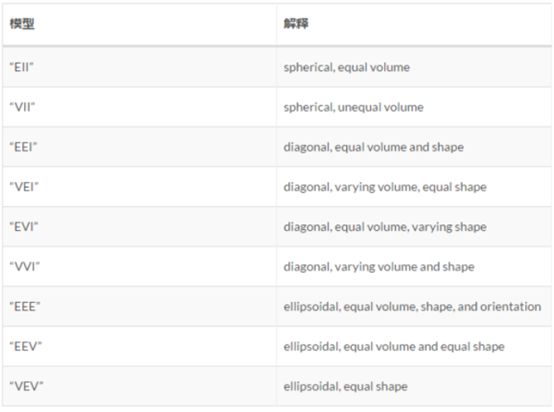
这些分别代表着相关性(完全正负相关——对角线、稍强正负相关——椭圆、无关——圆)等参数的改变对应的模型。简单的看,BIC值越大则说明所选取的变量集合拟合效果越好。上图中除了两个模型一直递增,其他的12模型数基本上都是在聚类数目为3的时候达到峰值,所以该算法由此得出最佳聚类数目为3的结论。
这里的BIC的定义为:
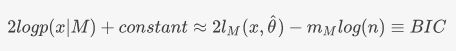
和贝叶斯信息准则不是一回事!!!
相关文献: mclust version 4 for R: normal mixture modeling for model-based clustering, classification, and density estimation. (2012,引用次数877)
4、 R包Nbclust
类似mclust,也是自己定义了几十种评估指标,然后遍历每一个设定的聚类数目,然后通过这些指标看分别在聚类数为多少时达到最优,最后选择指标支持数最多的聚类数目就是最佳聚类数目。
大体过程是用某种已有的聚类算法或者是划分类别的方法Kmeans,Ward(最小化类内方差),Single(最小距离),Complete(最大距离)和Average(平均距离)等,对每一个设定的类别个数进行聚类,得出聚类结果后用评估指标评估。
评价指标有:
"kl", "ch", "hartigan", "ccc", "scott", "marriot", "trcovw", "tracew", "friedman", "rubin", "cindex", "db", "silhouette"(轮廓系数), "duda", "pseudot2", "beale", "ratkowsky", "ball", "ptbiserial", "gap", "frey", "mcclain", "gamma", "gplus", "tau", "dunn", "hubert", "sdindex", "dindex", "sdbw"
"all" (all indices except GAP, Gamma, Gplus and Tau), "alllong" (all indices with Gap, Gamma, Gplus and Tau included).
这里不详细解释每一种评估指标。
相关文献: NbClust Package: finding the relevant number of clusters in a dataset. (2012,引用次数 25); Package 'nbclust'. (2014,引用次数 676)
5、 组内平方误差和——拐点图
一个简单可行的指标,SSE(sum of squared error组内平方误差)
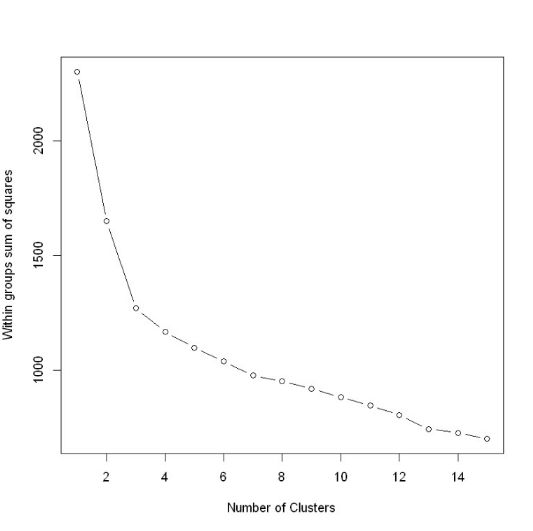
library(factoextra)
library(ggplot2)
set.seed(1234)
fviz_nbclust(scale(wine[,-1]), kmeans, method = "wss") +
geom_vline(xintercept = 3, linetype = 2)
6、 PAM(Partitioning Around Medoids) 围绕中心点的分割算法
选用簇中位置最中心的对象,试图对n个对象给出k个划分;代表对象也被称为是中心点,其他对象则被称为非代表对象;最初随机选择k个对象作为中心点,该算法反复地用非代表对象来代替代表对象,试图找出更好的中心点,以改进聚类的质量;在每次迭代中,所有可能的对象对被分析,每个对中的一个对象是中心点,而另一个是非代表对象。对可能的各种组合,估算聚类结果的质量;一个对象Oi可以被使最大平方-误差值减少的对象代替;在一次迭代中产生的最佳对象集合成为下次迭代的中心点。
对比kmeans:k-means是每次选簇的均值作为新的中心,迭代直到簇中对象分布不再变化。其缺点是对于离群点是敏感的,因为一个具有很大极端值的对象会扭曲数据分布。而PAM考虑新的簇中心不选择均值而是选择簇内的某个对象,只要使总的代价降低就可以。kmedoids算法比kmenas对于噪声和孤立点更鲁棒,因为它最小化相异点对的和(minimizes a sum of pairwise dissimilarities )而不是欧式距离的平方和(sum of squared Euclidean distances.)。一个中心点(medoid)可以这么定义:簇中某点的平均差异性在这一簇中所有点中最小。
R包fpc中的pamk函数可以确定最佳聚类个数,原理是通过尝试每一个设定的聚类数,用评价标准来看哪一个聚类数最佳,评价标准有:
1."asw" : average silhouette(平均轮廓系数) width given out by pam/clara
2."multiasw": average silhouette width computed by distcritmulti
3."ch": Calinski-Harabasz
Calinski-Harabasz公式:
其中,n表示聚类的数目 ,k 表示当前的类, trB(k)表示类间离差矩阵的迹, trW(k) 表示类内离差矩阵的迹。
相关文献: A new and efficient k-medoid algorithm for spatial clustering. (2005 引用次数: 87)
引用文献: A simple and fast algorithm for K-medoids clustering. (2009 引用数: 993)
7、 Calinsky criterion
Calinski-Harabasz准则有时称为方差比准则 (VRC),它可以用来确定聚类的最佳K值。
Calinski Harabasz 指数定义为:
其中,K是聚类数,N是样本数,SSB是组与组之间的平方和误差,SSw是组内平方和误差。因此,如果SSw越小、SSB越大,那么聚类效果就会越好,即Calinsky criterion值越大,聚类效果越好。
相关文献: A dendrite method for cluster analysis. (1974 引用数4447)
相关文献: Clustering using flower pollination algorithm and Calinski-Harabasz index. (2016 引用数19)
8、 Affinity propagation (AP) clustering
这个本质上是类似kmeans或者层次聚类一样,是一种聚类方法。
AP算法的基本思想是将全部样本看作网络的节点,然后通过网络中各条边的消息传递计算出各样本的聚类中心。聚类过程中,共有两种消息在各节点间传递,分别是吸引度(responsibility)和归属度(availability)。AP算法通过迭代过程不断更新每一个点的吸引度和归属度值,直到产生m个高质量的Exemplar(类似于质心),同时将其余的数据点分配到相应的聚类中。

相关文献: APCluster: an R package for affinity propagation clustering. (2011 引用数240)

以上内容撰写时间较早,如有参考其他文章而未标注引用的部分,实在抱歉,请及时告知,我立即修改。