导言
最早为大众知晓并接受的渲染框架或者说渲染模式是前向渲染(Forward Rendering)。前向渲染,用一句话来概括,就是对于场景中的每个物件,都进行一次渲染,而在这一次渲染中,需要对场景中的所的光源都处理一遍(这种处理可以放在一个Shader中完成,也可以放在多个shader中完成,当放置在多个shader中完成时,就需要经过多个pass才能将所有的shader都运行一遍,而这种方式的成本会比较高,所以对于前向渲染而言,通常都是直接使用一个shader完成所有光源的计算处理),并将多个光源的处理结果融合起来作为最终的结果输出到屏幕上。
前向渲染的缺点主要有以下几个,
- 不管光源是否会有光线投射到物体上,都要对这个光源进行一次处理,对于无法照射到这些物体上的光源而言,这会造成极大浪费
- 不同种类的光源的处理方式是不同的,其shader的计算过程也是不同的,当所有光源的处理都放在一个shader中的话,就会需要走不同的分支,而实际上在shader的执行过程中,分支的意思就是所有的分支都要执行,最终选择一条分支的输出做为输出,也是另一个存在浪费的地方
- 如果所有光源的处理都放在一个shader中执行,那么各个光源相关的数据都会是一直放在内存中备用的,比如各个光源的shadow map等在需要计算实时阴影的时候,就需要一直保持在内存中,这种情况会导致可用显存变得紧张。
- 当光源数目过于庞大的时候,这时候寄存器的数目会变得不够用,从而不得不将一个pass的处理分割成多个pass 完成,而分割又进一步加剧了时间的消耗。
- 对于由多个小尺寸的三角形面片组成的物体而言,某个像素可能同时被多个三角面片覆盖,导致需要进行多次ps计算,这也会导致进一步的浪费。
- 对于层次复杂的场景,某个像素点可能对应多个重叠的物件,在渲染的时候,所有的物件都需要进行一次渲染,但只有最接近相机位置的物件的渲染结果是有效的(此处只讨论不透明物件),这种现象被称为OverWrite,在这种情况下,其余物件的渲染(包括VS/FS)浪费的。
上面陈述的是最简单的前向渲染的基本思路与实现效果,实际上,还是可以通过一些方法来对前向渲染进行优化的:比如建立一个光源列表,维护这个光源所覆盖的物体的清单,在渲染的时候,按照光源来进行渲染,可以避免shader分支的额外消耗,以及无关物件的计算消耗,但是这种方式也需要通过多个pass来完成,每个pass处理一个或者一组光源,之后将这些pass的输出结果融合得到最终的输出结果。
前向渲染的流程如图所示

按照前向渲染的概念,如果场景中有M个物体,N个光源,那么最坏的情况下,每个物体都处在所有光源的笼罩之下,那么最终需要处理的复杂度就是O(M * N)。每个光源对于物件上的像素的最终输出是起着怎样的一个作用呢,是各自独立对物件施加影响,并在最后将这个颜色值相加吗?按照正常情况,一张白纸,在上面投下强度相同的红光与绿光,其最终显示的颜色应该是两者的叠加,从这个角度揣测,多种光源的作用下,独立计算并叠加就可以了。在场景复杂度较高,或者光源数目较多的情况下,其渲染一帧所需要的时间代价是极为高昂的。如果能找到一种渲染方法,使得其进行光照渲染的时间成本不随场景复杂度而变化就好了,基于这种想法,人们提出了延迟渲染(Deferred Rendering)框架。
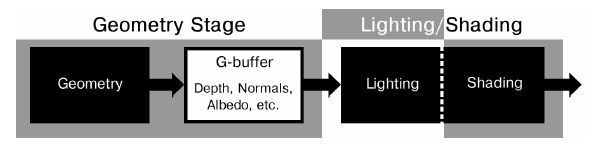
对于场景中的每个物体,在渲染的时候都需要经过Vertex Shader(VS)与Fragment Shader(FS)两个处理阶段:物体网格数据被分割成一个个的三角面片,三角面片中的顶点经过VS的处理后,经过光栅化(Rasterization)处理后变成一个个的Fragment,之后经过FS的光照计算处理(实际上,光照处理也可以放在VS阶段,不过其输出结果往往呈现出不连贯的面片状,与真实世界的表现相差太远,所以一般都将光照放在更为精细化的FS中处理,虽然消耗有所增长,但是效果是符合预期的),光照处理完成后输出到FrameBuffer中。
在前向渲染模式下,OverWrite会导致复杂场景存在极大的浪费。而延迟渲染可以将场景中的多个光源的计算处理过程一次性完成,且只有那些处在光源的覆盖范围内的,且最终在屏幕上可见的像素才会参与到光照计算中来,大大节省了时间成本?那么延迟渲染到底是怎么做到的呢?
简单来说,就是将光照的计算处理从之前的逐物体进行,改为只在最终的的back buffer上进行。这其实可以理解成是一种后处理(Post-process),准确来说,是一个multipass post-process,其总体流程如\ref{deferred}所示,总的来说,可以分成三个pass:

- 第一个pass用来对整个场景进行渲染————world pass
- 第二个pass用来对第一个pass输出的结果进行光照处理————lighting pass
- 第三个pass负责将第二个pass的输出结果显示到屏幕上————present pass
G-Buffers
延迟渲染中,最关键核心的一个概念,就是Geometry Buffer,俗成G-Buffer。G-Buffer包含了屏幕上各个像素用于计算光照shading所需的全部元素(如坐标数据,法线数据,深度数据,材质贴图数据等,而通常情况下,为了节省,一般坐标数据是不需要存储的,而是在需要的时候根据深度数据计算得到)。G-Buffer 中常见的几个元素有用于计算diffuse color 的基色贴图Albedo,用于计算高光数据的Specular 贴图(通常包含金属度与粗糙度数据?),还有光影计算必须的一些基础元素如法线贴图与深度贴图等,其表现如图所示:

一般来说,如果将G-Buffer的数据都存储在一张贴图中,那么这个贴图的单个像素的长度肯定非常大,而实际上,G-Buffer的数据通常会分别存储在多张贴图中,这就是我们俗称的Multiple Render Target (简称MRT),而为了尽可能的节省带宽与内存,在如何对数据进行存放也成为了一种艺术。如图所示,此处一共使用了五张贴图用于存储G-Buffer 的数据:

延迟渲染具体流程
延迟渲染,一般可以分成两个阶段:第一个阶段是geometry render阶段,这个阶段的输入是顶点数据,输出则是G-Buffer的各种元素,在这个阶段中,会处理之前前向渲染所应该处理的除了光照之外的一切计算,将后续计算需要的结果存入G-Buffer中;第二个阶段则是shading render阶段,这个阶段的输入就是我们前一个阶段的输出,也就是G-Buffer数据。如前面所述,这是一个后处理过程,也就是说,从本质上来说,这就是一个复杂的Fragment/Pixel Shader执行过程,这个阶段会从G-Buffer中取出与当前计算的Fragment相对应的数据,并对每个光照按照选定的光照方程(Light Equation)计算其光照输出,之后各个光源的输出按照一定的方式(Additive Blending)融合输出到FrameBuffer中。
在多个光源的情况下,延迟渲染的流程大概可以用伪代码来描述:

延迟渲染最终输出到屏幕上的图像表现跟前向渲染输出的结果是一样的,不同的是调整了渲染管线中各个子环节的渲染顺序,避免了许多不必要的计算与处理:
- 如避免了我们前面提到的各种被遮挡元素的光照处理过程,只有最终会被显示到屏幕中的像素才会经过光照处理阶段,而要想在前向渲染中实现这个效果,就需要做实时的遮挡剔除,但是遮挡剔除的消耗比较高,一般都是用在离线计算过程中的
- 如避免了多个细小三角面片在单个像素上的多次计算消耗,如图

从而实现了整个渲染过程的加速。
延迟渲染算法的改进
延迟渲染的优点是:
- 每个几何体(geometry)只需要处理一次
- 由于是对light进行循环计算的,所以,每一个light的处理过程都是确定的,避免了前向渲染shader中杂七杂八的分支
- 每次只处理一个light,不存在光源数目过多而导致寄存器不够用的情况
- 由于延迟渲染本来就是后处理的一种,因此对于各种后处理有比较好的兼容性(比如SSAO)
而其缺点则在于:
- 由于G-Buffer的格式是固定的,所以其能够提供的参数种类就是有限的,导致其只能处理有限种类的光照情况,即所谓的Shading Model数目是有限的。
- 由于G-Buffer中对于屏幕中的每个sample都只能存储一条数据,所以延迟渲染无法处理需要前后多个sample参与的透明或者半透明的物体的渲染
- 由于每次对光源进行渲染的时候,都需要将G-Buffer数据加载一次,因而延迟渲染对于带宽有较高的要求。
- 在上面的算法中,我们看到,延迟渲染需要计算各个光源对于某个Fragment的contribution的,这就意味着,对于任意一个Fragment,任意一个光源,都要进行一次评估,这就会导致shader处理的多分支情况的浪费。而实际上,只有极少数的光源会对所有的Fragment 产生影响,而大多数的光源都只能覆盖极少一部分Fragment。
- 不支持MSAA
- 在部分情况下,可能渲染效率要低于前向渲染(比如光照数比较少,且场景简单,overlap比较少的情况下)
对于上述的缺点,是否有较好的解决方案呢?实际上,是可以做一些改进的,如:
在一次pass中,处理多个光源(这多个光源最好是在像素的覆盖上有比较高的重合度,或者有其他相似之处从而可以通过合并部分计算来达到节省的作用,比如将平行光作为主光源进行一次处理,对点光源组又进行一次处理),从而避免G-Buffer 重载的次数,降低对FrameBuffer 的写频率
-
在每个光源pass中,不再对所有的Fragment进行处理,而是只处理那些光源可能覆盖到的Fragment。
- 将光源的覆盖范围看成一个geometry(这个geometry叫做light volume,形状可以是box,也可以是sphere,也可以是cone或者pyramid),之后对这个light volume 进行渲染与光栅化,过程与结果如图所示:


将light volume光栅化后覆盖到屏幕上的形状,并计算出一个能覆盖住这个形状,且与屏幕的坐标轴对齐的quad,这种方法被称作Quad-based Culling。实际上最开始提出精确控制光源覆盖范围这个思路的时候,考虑的是使用一个能精确代表光源形状的几何体来计算其覆盖范围,但是这种方式会导致需要处理大量的面片和顶点数据,成本略高,后来考虑直接用一个或者几个BoundingBox 来模拟其形状,方法简单且计算高效。而在计算光源能影响的像素数据的时候,有两种方式,一种是对每个光源使用stencil 来判定其是否被覆盖,这种方式需要进行两个pass处理,过程繁琐且低效;另一种方式则是直接使用depth test 来判定当前的光源是否能够覆盖到当前像素(将当前像素变换到光源空间中,与shadow map比较?)。
-
降低每个光源需要从G-Buffer中读取的数据尺寸或者读取频率,或者降低写入频率,这可以通过Deferred Lighting或者Light Pre-Pass的方式来实现,其步骤大致如下:
- 将diffuse与specular拆解成两个独立的元素,分别进行计算。在这种情况下,可以只用单色来表示Specular,虽然这种做法是物理不正确的,但是其效果表现差异非常小,基本可以忽略,从而可以节省两个float数据的读入。 - 将与光源无关的元素(如Surface Albedo)单独拎出来,提前加载到显存中,避免对于每个光源都进行一遍加载。 - 对于每个光源而言,将它们计算结果的diffuse与specular等元素分别进行相加 - 最后,通过一个Resolve Pass,将diffuse与specular等元素合并起来。而这个过程可以通过SIMD得到加速。(有人可能会觉得将diffuse与specular拆解出来计算,在最后合并的时候可以选择多种灵活的方式来得到更好的效果,但实际上光照方程中精彩的变化点都出现在diffuse与specular的内部计算中,在外部合并处反而没有太多嚼头,所以从这个方面来说,拆开diffuse与specular并没有太大收益)
Tile-based Deferred Shading是另外一种对延迟渲染进行提速的实现算法。其基本思想是将G-Buffer分割成一个个的tile,之后对于每个tile,计算各个光源是否与之相交(注意,在Z轴上是需要比较MinZ与MaxZ的),之后对覆盖到这个tile的光源进行处理,即每个tile 加上若干光源作为一个group,之后逐group 的进行处理。而这种思想通过借助于GPU的SIMD特性实现CPU并行计算功能的compute shader,可以得到极大的加速:
- 由于是逐tile处理的,所以G-Buffer的数据就不需要全盘加载读入了,而且对于FrameBuffer也不再是全盘写入了。
- 对于光源数据,也不需要将所有的光源数据都读入并处理,而是只处理与当前处理的tile相关的数据即可。
- 降低了光源处理的复杂度,不再需要对所有的像素进行光源可见性判定,只需要经过一次粗糙的tile可见性判定,加上tile内的精细判定就可以保证无遗漏了。
- 这个方法是以tile中的像素为核心进行的,每个像素都需要对所有tile相关的光源进行一次计算,所以对于光源而言,不需要在shader中进行分支计算。
这种方法的具体思路大概如图所示:

其实施效果大致如图所示,可以看到,场景中光源数目越多,这种算法对于帧率提升的幅度也越高。

而Quad-based Culling与Tile-based Culling的效果对比如图所示,可以看到在光源数目越多的情况下,Tile-based Culling方法的收益越高:

关于Tile-based Culling与Deferred Shading以及Deferred Lighting(因为使用了单色specular而导致性能有所提升),也有相关的对比数据,如图:
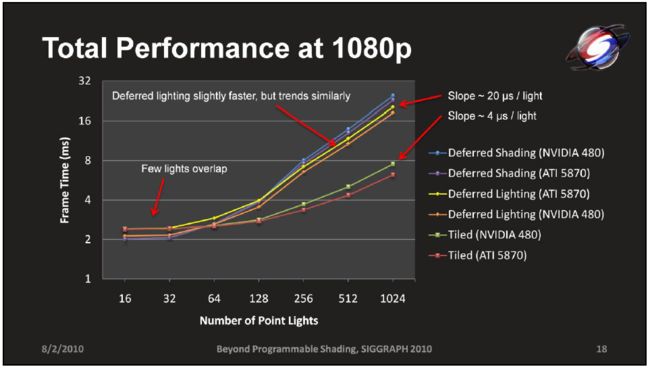
延迟渲染与MSAA
我们知道,MSAA是对于场景中的每个三角面片,都对其覆盖的每个像素进行一次FS/PS计算,之后将结果赋予这个像素中被三角面片所覆盖的采样点sample,最终在输出最终图像的时候,就将单个像素中所有sample的值加起来求平均。
而从刚才描述的延迟渲染的实现流程来看,在最终计算输出到屏幕的FrameBuffer的结果时,已经没有所谓的三角面片,每个G-Buffer 的像素只有一个sample数值,不再存在多个颜色sample,以便在最终输出的时候进行相加求平均了(而这也是透明或者半透明物件的渲染与延迟渲染不兼容的原因),所以,从这个角度来看,延迟渲染与MSAA 算法是不兼容的。
不过从MSAA的原理上来看,我们实际上可以用类似SSAA的方式来实现类似的MSAA,即只对面片的边缘处进行per-sample的计算(每个像素多次计算),而对于其他完全被面片覆盖的像素处,则只进行per-pixel的计算即可。当然,数据的存储量变成了多倍(比如最常见的2x2就是4倍),不过这些数据在其他场景中也是有用的,比如可以用在shadow map上消除锯齿。
而要实现上述MSAA,首先需要解决的问题,就是需要侦测到图像的边缘,通常对边缘的检测有以下几种方式:
- 通过深度对比,找出深度不连续的(比如使用深度的导数,也就是相邻sample的深度的差的趋势来判定是否发生了转折),即为边缘
- 对于曲面来说,深度检测方法可能会失效,因此对于这种情况,可以考虑使用sample上的shading normal(这跟普通的normal有什么区别?)来进行检测,如果相邻sample的normal差距过大,可能就是曲面的边缘了
- 上面两种检测方法已经足以应付绝大多数情况了,不过由于边缘检测的实现是开发者自己完成,所以也可以采用一些自认为合适的方法来进行。
这种自己实现的MSAA方法跟前向渲染中的MSAA方法对比,还有自己独特的好处,比如对于边缘比较光滑的三角面片的交界处,并不需要进行逐sample的渲染,进一步降低了计算量。
在Quad-based Deferred Rendering中使用MSAA一般首先要先辨别边缘像素,之后才对边缘像素进行per sample采样计算。而辨别边缘的方式又可以分成shader branch以及stencil两种,shader branch效率低,而stencil则需要使用两个pass(一个标记per sample像素并渲染,另一个标记per pixel像素并渲染),这就会导致需要对光照进行两次Culling操作,虽然如此,但还是比shader branch速度快。
在Tile-based Deferred Rendering中使用MSAA相对于Quad-based Deferred Rendering中有所改进,per sampler以及per pixel的渲染都是放在一个shader pass中完成,且为了避免shader branch,在shader的主流程中只处理sample 0的计算结果,而像素中剩下的sample则通过computer shader的多线程计算功能分散到其他线程中完成。
两种方式实施的性能对比如图所示:
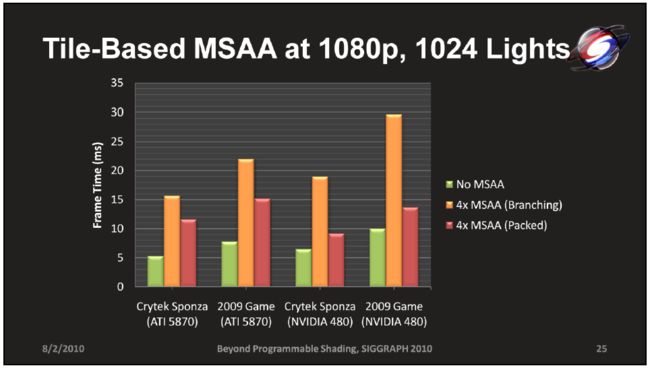
Deferred Shading 与 Deferred Lighting
在延迟渲染的概念中,经常会出现Deferred Shading以及Deferred Lighting的说法,这两者分别代表什么意思,又有什么区别呢?
实际上,Deferred Shading就是我们前面所描述的Deferred Rendering的内容:对所有的物体进行一遍渲染,将后续LIghting/Shading 所需要的所有数据存入G-Buffer,之后通过多个pass对多个灯光进行Lighting+Shading后进行混合,或者只用一个pass对所有的光源进行处理并输出结果,流程如图所示。
与Deferred Shading不同,Deferred Lighting将Lighting与Shading分开,在Lighting阶段,只处理光照相关数据,并将结果输出到一个Normal Buffer中(如这个Buffer中可能只包含Normal,Depth以及Specular相关参数,Normal占用两个float,剩余两个参数各占一个,如果Lighting阶段只需要输出一个Normal Buffer就足够的话,那么就可以去除Deferred Rendering对于MRT的限制,同时也可以避免MRT 带来的带宽与OverWrite浪费),Lighting 的输出结果是Diffuse+Specular Color,在有些项目中,为了将这两者输出到一张Buffer 中,而选择将Specular 压缩到一个通道中(单色Specular 在绝大部分情况下其实基本上都是够用的)。Lighting 之后,就进入了Shading 阶段,在这个过程中,将Lighting阶段得到的光照数据取出来,对物体进行Shading,为了能够处理物体材质相关的逻辑(比如支持头发,次表面散射,自发光等),在这个阶段会对所有的物体再进行一次Geometry Pass (由于之前已经获得了全场景的Depth 数据,这一次的Geometry Pass 要快上很多),各个物体的材质相关数据如Albedo 贴图信息等都可以在进行Geometry Pass的过程中直接取到,从而可以根据不同的材质实现不同的渲染方式。 其流程如图所示。

通常来说,相对于Deferred Lighting而言,Deferred Shading的主要的局限性在于:
- 后续lighting与shading所需数据较多,导致需要使用多个Render Target才能完成必须数据的输出,导致较高的带宽占用
- 在进行Geometry渲染阶段时,Depth Buffer是逐渐生成的,在生成的过程中,其实会导致较多的overwrite(Deferred
Shading的OverWrite,Deferred Lighting应该也是无法避免的吧?),而由于G-Buffer 的数据比较复杂,导致这部分浪费的计算量也比较大 - 在这种模式下,如果需要对不同的mesh指定不同的材质,以实现不同的渲染效果(如自发光,次表面散射,头发等)就需要在G-Buffer 中增加额外的空间用以输出相应的信息,而这些特定的材质往往只占据着极少部分像素,导致存储这些信息的大部分的像素其实都是浪费的。
在Deferred Lighting模式下,Geometry Rendering阶段的所有输出,只需要用以支持Lighting即可,从而大大减少了前面提到的Deferred Shading的OverWrite导致的浪费,且因为Lighting需要的信息比较少,比如只需要Normal数据+Depth数据+Specular数据(在不那么挑剔的情况下,这些数据可以直接塞入一张buffer中,从而摆脱平台不支持MRT的限制),从而也可以避免Deferred Shading的高带宽消耗。但是,需要注意的是,Deferred Lighting也有着自身的缺陷:
- 最显著的缺陷在于,Geometry会被渲染两次,虽然后面一次由于Early-Z的原因,消耗得到很大程度的降低,整个过程的消耗依然不容小觑。
- 由于在Shading阶段会需要完成Geometry处理与Shading两部分内容,所有Pixel Shader不可避免的会被分割成Geometry部分与Shading部分,从而导致Pixel Shader的指令的实施效率的降低。
实际上,仔细分析,相对于Deferred Shading,Deferred Lighting只是将Lighting与Shading分开(一个Pixel Shader变成两个,处理的功能不变),另外增加了一次Geometry Pass(相当于增加了一个Vertex Shader处理),从前面的优劣对比猜想这两者的性能消耗不一定会有比较大的差距,但实际上,大部分情况下Deferred Lighting对于Deferred Shading的改进都无法抵消新增的Vertex Shader的消耗,导致在绝大部分情况下,Deferred Shading的性能都要更胜一筹。
针对Deferred Lighting的优势与弊端,有人整出了一种混合Deferred Rendering的方式[Hybrid Deferred Rendering,Marries van de Hoef],其基本Pipeline如图所示:

其渲染效率对比如图所示:

延迟渲染下的阴影实现方式
在延迟渲染模式下,主要有以下几种实现阴影的方式:
- Stencil Shadow。在进行光照处理的同时,对那些光照覆盖的位置进行stencil处理,最后使用stencil的数值来判定当前是否处于阴影区域内。不过这种方式只能用来实现硬阴影,对于软阴影就无能为力了。
- Shadow Map。对于每个光源,生成一张类似于深度贴图的Shadow Map(从光源的角度出发),之后在进行lighting的时候,将像素转换到光源空间与shadow map进行比对而判断是否处于阴影中。这种方式,对于每个光源都需要产生一张shadow map,消耗比较高,所以,一般只对主光源(平行光)使用,其他光源采用其他方式。或者在手机等平台上,直接使用离线渲染的方式将多个光源的shadow map合成称为一个light map,用于运行时渲染。
- 平面阴影。将物件投射到某个平面上,产生一个物件的平面形状。这种方式限制比较多,比如对于处于曲面上的物体,其阴影可能会穿帮,又对于一些可以在Y轴上下沉一段距离的物体,其表现也不尽人意。