大数据文摘作品
编译:张南星、笪洁琼、钱天培
深度学习三巨头Yann LeCun、Yoshua Bengio、Geoffrey Hinton曾在Nature上共同发表一篇名为《深度学习》的综述文章,讲述了深度学习为传统机器学习带来的变革。
从2006年Geoffrey Hinton为世人展示深度学习的潜能算起,深度学习已经蓬勃发展走过了10多个年头。这一路走来,深度学习究竟取得了怎样的成就,又会何去何从呢?
文摘菌节选了这篇论文的精华部分进行编译,对这些问题作出了回答。在公众号后台对话框内回复“三巨头”即可下载这篇论文~

左起:Yann LeCun(Facebook)、Geoffrey Hinton(谷歌/多伦多大学)、Yoshua Bengio(蒙特利尔大学)、吴恩达(deeplearning.ai)
借助深度学习,由多重流程层组成的计算模型能够从不同层级的抽象数据中学习数据的特征。这些方法极大促进了先进技术的发展,包括语音识别、视觉对象识别、目标检测以及许多其他领域,诸如药物识别以及基因学研究。
使用反向传播算法,深度学习能够指出机器如何基于上一层的特征,通过改变内部参数来计算出下一层的特征,以发现大型数据集中错综复杂的结构。深度卷积网络给图像、视频、语音与音频处理带来了极大突破,同时循环神经网络则给诸如文字及语音的顺序数据研究带来了希望。
机器学习在许多方面都造福了现代社会:从网页搜索到电商网站上基于社交网络内容筛选做出的推荐,并且在消费品中的存在感越来越强,例如相机、智能电话等。
机器学习系统被用于识别图像中的物体、将语音转化为文本、匹配新物体、根据用户兴趣个性化推送或生产商品,也可以用于选择搜索结果中相关的内容。有趣的是,这些应用就是大名鼎鼎的深度学习实际应用。
传统机器学习技术难以处理原始的自然数据。近几十年来,建造一个模式识别或者机器学习系统,需要细致的策划以及丰富的领域知识,以设计特征抽取器来将原始数据(例如图像的像素值)转化为合适的内部表征或者特征矢量,学习子系统(如分类器)就能够从输入值发现规律。
特征学习通过一系列方法,让机器在输入原始数据后,自动发现检测或分类所必须的特征。
深度学习方法是拥有多层级的特征学习方法,使用简单但非线性的组件将每一层(从原始数据开始)的特征转化为更高阶、更抽象化的层级特征。通过结合足够多次的转化,能够得到非常复杂的函数。
对于分类任务,高阶特征能够放大输入值中用于区分的特点,并忽略掉无关的变量。
例如,图像类数据由像素值数组组成,从第一层特征学习得到的结果就很明显代表了图像中特定方向及位置上边缘是否存在。
第二层则忽略掉边缘位置的微小变化,通过边缘的特定变化来探寻图像主要特点。第三层则将这些特点组合在一起,形成一个更大的、与常见物体某一组成部分相似的集合,后续的层次则通过将这些部分组合在一起,识别物体。
深度学习一个重要的特点就是,这些特征层并不是由人类工程学家设计的:它们来源于经过通用学习流程处理的数据。
深度学习很大程度上帮助解决了人工智能界多年来无法成功解决的问题。
它非常擅长于发掘多维数据中错综复杂的结构,也因此能够应用于科学、商业以及政府中的多个领域。
除了攻下图像识别、语音识别的城墙之外,深度学习还在其他机器学习方面攻下一城,包括预测潜在的药物分子的活性、分析粒子加速数据、重构大脑回路,以及预测基因表达及疾病中非编码DNA突变的影响。
也许更令人惊叹的,是深度学习在自然语言理解方面的突出表现,尤其是主题分类、情绪分析、问题回答以及语言翻译。
我们认为深度学习在不远的未来会取得更大的成就,而且只需要少量的人工操作,它就能充分利用可用计算资源及积累的数据。深度神经网络中新学习算法及架构的出现将会推动它的进步。
监督学习
不论深度与否,机器学习中最为常见的形式是监督学习。想象一下,现在我们需要建造一个系统,它能够识别图像中的物体是否为容器,例如房子、车辆、人,或者宠物等。首先我们会收集大量房子、车辆、人、宠物的数据集,并分别用标签标记类别。
在训练过程中,机器会识别每张图像上的物体,并且以分数矢量的方式产出结果到每个类别。我们希望目标类别得分最高,但是在训练之前,这是不可能发生的。
我们推导出一个目标函数来测量实际值与目标类别分数之间的差,然后机器将修正内部的可调整参数以减少错误。
在一个典型的深度学习系统中,可能存在着上千个、甚至上百万个可调整权重,以及大量用于训练的带标签案例。
在实际生产中,许多程序员会使用随机梯度下降法(SGD)。这个方法有以下几个步骤:展示几个案例的输入向量,计算输出结果及错误值,计算这些案例的平均梯度,然后对权重做出相应的调整。
这个流程将在许多个小案例集中重复多次进行训练,直到目标函数的平均梯度不再下降。
经过训练之后,将通过另外一个由不同案例组成的测试集来评估系统的表现。其目的主要在于测试机器的推广能力——是否能在输入新结果的情况下得到合理的结果。
现在实际生产中,许多机器学习系统在人工提取特征的基础上使用线性分类器。一个两级线性分类器会对特征向量组件计算加权和,如果加权和高于阈值,这个输入将被分入为某一特定分类之下。
但是线性分类器在图像识别、语音识别中的应用有较大限制,需要诸如特征提取器等深度学习方法以实现特征学习。
一个深度学习架构是由一系列简单组件组合而成,其中所有(或者大部分)都需要学习,并且许多都能计算出非线性的输入输出映射关系。其中每个组件都会充分利用输入,以提高选择性和不变性。
这些系统拥有多个非线性层(例如5-20层),能够支持极其复杂的函数,并对微小的细节保持敏感度,例如达到能区分萨摩耶和白狼的地步,同时忽略所占范围大的不相关变量,例如背景、姿势、光线以及周围的物体。
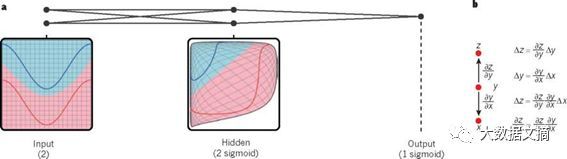

使用反向传播算法训练多层架构
使用反向传播算法计算目标函数组件中多层堆叠权重的梯度,本质上是导数链式法则的一个实际应用。其中非常重要的一点在于,目标函数组件输入的导数(也就是梯度)能够通过这个组件输出的梯度倒推出来(或者是通过下一个组件的输入倒推)。
反向传播方程能够重复在所有组件中推广梯度值,从顶部(此网络产出预测的地方)开始,一直到底部(外部输入的地方)。一旦计算出这些梯度,就能很简单地算出每个组件权重的梯度了。
许多深度学习的应用都使用了反向传播神经网络架构,通过学习映射固定大小的输入到固定大小的输出(例如每个分类的可能性)。层与层之间每个单元能计算出来自上一层输入的加权和,并把结果传给非线性函数。
20世纪90年代末,神经网络以及反向传播算法被大多数机器学习研究团体所抛弃,并且计算机视觉和语音识别研究者们也普遍忽略了它。大家都认为用很少的先验知识是不可能得到有用的多阶特征提取器。
但是在实践中,局部极小值在大型网络中并不是一个问题。无论最初的情况如何,系统得到的结果质量水平是类似的。最近的一些理论和实证结果都强有力地证明了,一般情况下局部最小值并不是一个严重问题。
2006年左右,加拿大高等研究院(CIFAR)的研究员让公众重新对深度反向传播网络产生了兴趣。研究员们发明了不需要标签数据就能进行特征发现的无监督学习程序。
这种无需训练的方法首次被大规模应用是在语音识别领域,快速图形处理器(GPU)的发明使它得以在生产中得到应用,GPU极大方便了编程,让研究员能够以10到20倍的速度训练网络。
但是,在深度学习重新获得大众的青睐之后,似乎这种训练前算法只对小数据集有用。实际上,存在一种特定的深度反向传播网络比相邻层之间全连接的网络更加容易训练和应用。那就是卷积神经网络(ConvNet)。
当人们开始对神经网络失去信心时,卷积神经网络取得了许多实践层面上的成功,最近在计算机视觉领域大受欢迎。
****卷积神经网络****
卷积神经网络被设计用来处理多重阵列形式的数据,例如由三个2D数组组成、包含了三个颜色通道像素灰度的彩色图像。
卷积神经网络背后有四个重要的思想,充分利用了自然信号的属性:局部联系、相同的权值、池化以及多个层级的使用。
一个典型的卷积神经网络架构由一系列阶段组成。最初的几个阶段由两个层级组成:卷积层以及池化层。
卷积层中的单元有组织地出现在特征地图中,每个单元都通过一个叫做滤波器组的权值组与上一层地图中的局部补丁连接。同一层的不同特征地图使用不同的滤波器组。
虽然卷积层主要用于探测与上一层特征的局部联系,池化层则主要是将语义上类似的特征合并为一个。一个典型的池化单元能计算一个特征地图(或者几个特征地图)中局部补丁的最大值。
相邻的池化单位从补丁中得到大于一行或一列的输入值,以减少特征的维度,并给微小的转换或变形创造不变性。
从20世纪90年代早期开始,卷积网络就已经广泛应用,即时延神经网络在语音识别以及文档阅读的应用。文档阅读系统使用卷积神经网络和规定了约束语言的概率模型进行训练。
到20世纪90年代末,这个系统阅读了全美超过10%的支票。后来微软部署了大量基于卷积网络的光学字符识别以及手写识别系统。卷积神经网络在20世纪90年代初还被用于自然图片中的目标识别,包括脸部、手部,以及人脸识别。
********基于深度卷积网络的图像理解********
从21世纪早期,卷积网络在图像目标、区域的探测、分类以及识别上取得了巨大成功。
这些领域中标签数据资源非常丰富,例如交通信号识别、神经连接组学的生物图像分类等。最近的一个重大成就在于人脸识别。
由于图像的一个重要特点——可以在像素级别打上标签,卷积网络在图像上的应用可以在科技领域里发扬光大,包括自主式移动机器人以及自动驾驶车辆。
Mobileye和NVIDIA公司在他们的车辆视觉系统中就使用了基于卷积网络的方法。
尽管取得了一些成功,卷积网络还是被主流机器视觉以及机器学习研究团体忽视,直到2012年的ImageNet大赛。
当有人使用深度卷积网络处理了来自于网络的一百万张一千种图片数据集后,比之前最好的方法几乎降低了一半错误率。
这个来源于GPU和ReLU的成就在计算视觉领域引发了一项革命。卷积神经网络现在几乎是所有识别和探测任务的主要方法,以及在一些人类行为分析的任务中也有应用。
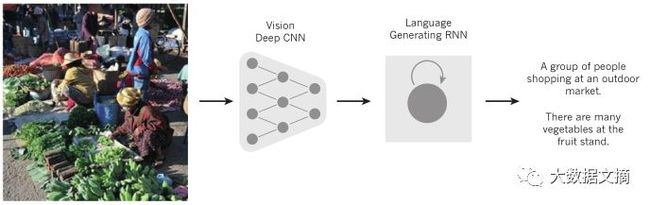

****************分布式表达以及语言处理****************
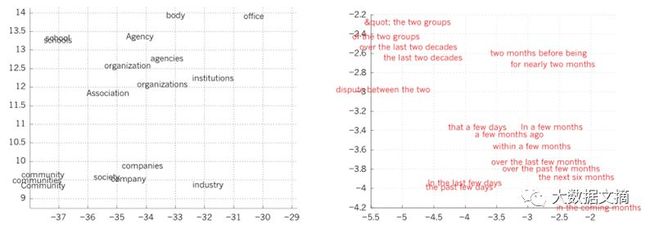
从深度学习理论中可以看出,深度网络比不使用分布式表达的传统学习算法有两个指数级的优势。
这两个优势都来源于其组成成分和内部结构。首先,学习分布式表达能够让学习到的特征值一般化为新的组合形式,而非在训练中直接观察到的结果(例如n个二进位制特征能够组合为2的n次方个)。其次,深度网络中的特征层组合可能带来了另一个指数级优势。
多层神经网络中的隐藏层能通过学习,以一种更容易预测目标输出的方式找到网络输入的特征。这能通过训练一个多层神经网络从文本中前一部分内容预测接下来一系列词语得到很好地体现。
特征寻找的主要问题在于逻辑驱动的认知算法和神经网络驱动的认知算法之间的不同。
逻辑驱动算法中,一个符号实例是唯一的资产,来推断是否与其他符号实例一致与否,其内部并没有与使用方式相关的结构。
如果需要对符号进行推断,需要选择恰当的参考标准才可以进行。相反,神经网络只需要使用大量活动向量集、权重方阵以及大规模非线性来完成“直觉性”推断,这和一些简单的常识性推断是一致的。
在引入神经语言模型之前,标准语言统计模型方式并没有涉及到分布式特征,它不能将模型推广到其他语义相关的文本中,但是神经语言模型可以,因为它能够将每个词语与具有真实值的特征联系起来,然后从语义上将与那个向量空间中相似的文本连接起来。
********************************循环神经网络********************************
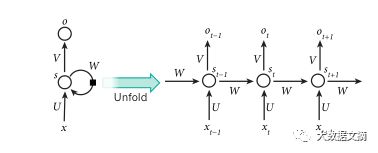
当反向传播算法最初被发明时,它最令人激动地用处在于训练循环神经网络(RNN)。涉及到顺序数据输入值时,例如语音以及语言,使用RNN是不错的办法。
RNN是非常具有优势的动态系统,当时训练这些系统是非常麻烦的,因为反向传播算法的梯度在每一时间步都有可能增长或降低,所以经过多次步骤之后,梯度会很明显的增长或消退。
幸好架构以及训练它们的办法,RNN非常擅长于预测文本中下一个词是什么,但同时也非常适合更复杂的任务。
在过去几年里,几位作者曾提出使用一个记忆模块来增强RNN。提议之一是神经图灵机器,它通过使用一个类似于磁带一样的存储器来进行增强,以方便RNN能够从中选择读取或者写入;或者通过一个规律联想记忆网络实现增强,其在标准问题回答对标上有出色的表现。
****************************************************************深度学习的未来****************************************************************
虽然非监督学习催化了深度学习的复兴,但是仍然在单纯监督学习的光芒下黯然失色。本文中并没有过多讨论非监督学习,但是我们还是希望非监督学习的重要性在未来会变得更高。人类和动物的学习大多都是非监督的:我们是通过观察来发现世界的规律,而非别人手把手告诉我们每一个事物的名字。
人类视觉能够以一种非常机智、明确的方式积极地处理连续的视觉信息,并且在一个大而低分辨率的环境之下,集中于一个小而高分辨率的中心。
我们期待着,未来计算机视觉能够端到端训练系统,通过集合ConvNets和RNN两种方式,强化学习,精确决策“看哪儿”。集合了深度学习和强化学习的系统仍然在发展初期,但是它们在使用被动视觉系统中进行分类的任务完成上超出了预期,并且在电子游戏中表现出色。
自然语言理解是未来几年另一个机器学习蓄势待发的领域。我们期待着,通过使用RNN去理解句子或整个文档的过程能够变得更加容易,系统能够懂得如何一次选择一个部分进行理解。
最终,人工智能领域主要的进步将来自于集合了特征学习和复杂推理的系统。
虽然深度学习和简单推理已经在语音识别与手写字体识别上应用了很长一段时间,但是如果希望对大型向量进行操作,而非使用基于规则的符号表达式,仍然需要新的算法进行支持。
大数据文摘公众号后台对话框内回复“三巨头”可以获得这篇售价199美元的《Deep Learning》论文哟~~
论文原地址:
https://www.nature.com/articles/nature14539