图卷积神经网络笔记——第六章:(1)基于PyTorch的时序数据处理(交通流量数据)
在前面说了PyG这个框架,但是这个框架处理数据其实没那么简单,并且有时候我们想要改变底层的图卷积框架时就无能为力了,所以这一章说一下用PyTorch怎么写出图卷积并且实现交通流量数据的预测。但在这之前,需要先处理好需要的数据。
下一小节:链接
文章目录
- 一、数据来源
- 二、数据分析
- 三、数据处理
-
-
- 1、读入数据并取需要的特征
- 2、数据集处理:写成PyTorch所需要的数据集的类
-
-
- (1)读入邻接矩阵
- (2)读入流量数据
- (3)把前面读入的数据处理成模型所需要的train_data和test_data
-
-
一、数据来源
数据来自美国的加利福尼亚州的洛杉矶市,第一个CSV文件是关于节点的表示情况,一共有307个节点,第二个npz文件是交通流量的文件,时间范围是两个月(2018.1.1——2018.2.28),每5分钟测一次。
下载地址:
链接:https://pan.baidu.com/s/1GlssEHKgf9agTRsdhPPuRA
提取码:q7v9
二、数据分析
在处理数据之前,先看看拿到的数据长什么样子,我们可视化数据看看:
import numpy as np
import matplotlib.pyplot as plt
def get_flow(file_name): # 将读取文件写成一个函数
flow_data = np.load(file_name) # 载入交通流量数据
print([key for key in flow_data.keys()]) # 打印看看key是什么
print(flow_data["data"].shape) # (16992, 307, 3),16992是时间(59*24*12),307是节点数,3表示每一维特征的维度(类似于二维的列)
flow_data = flow_data['data'] # [T, N, D],T为时间,N为节点数,D为节点特征
return flow_data
# 做工程、项目等第一步对拿来的数据进行可视化的直观分析
if __name__ == "__main__":
traffic_data = get_flow("PeMS_04/PeMS04.npz")
node_id = 10
print(traffic_data.shape)
plt.plot(traffic_data[:24*12, node_id, 0]) # 0维特征
plt.savefig("node_{:3d}_1.png".format(node_id))
plt.plot(traffic_data[:24 * 12, node_id, 1]) # 1维特征
plt.savefig("node_{:3d}_2.png".format(node_id))
plt.plot(traffic_data[:24 * 12, node_id, 2]) # 2维特征
plt.savefig("node_{:3d}_3.png".format(node_id))
运行结果如下:

所以可得出:每个节点有三个特征,但是其他两个节点基本是平稳不变的,所以我们只取第一维特征。
三、数据处理
1、读入数据并取需要的特征
前面说了,只取第一维特征,并且为了后面方便,将节点的维度放在第一维,所以重写的get_flow()函数如下:
import csv
import torch
import numpy as np
from torch.utils.data import Dataset
def get_flow(file_name):
flow_data = np.load(file_name)
print([key for key in flow_data.keys()])
print(flow_data["data"].shape) # (16992, 307, 3),16992是时间(59*24*12),307是节点数,3表示每一维特征的维度(类似于二维的列)
flow_data = flow_data['data'].transpose([1, 0, 2])[:, :, 0][:, :, np.newaxis] # [N, T, D],transpose就是转置,让节点纬度在第0位,N为节点数,T为时间,D为节点特征
# 对np.newaxis说一下,就是增加一个维度,这是因为一般特征比一个多,即使是一个,保持这样的习惯,便于通用的处理问题
return flow_data
2、数据集处理:写成PyTorch所需要的数据集的类
说明:下面的所有代码都在traffic_dataset.py文件中,我为了说明把几个函数分开了,运行的时候只需要全复制到一个.py文件中即可。
(1)读入邻接矩阵
首先当然是邻接矩阵的读取,前面的.CSV文件其实就是一个直接能可视化的邻接矩阵,当然不是我们所需的那种,所以才需要处理嘛。如下所示,from和to表示的是节点,cost表示的是两个节点之间的直线距离(来表示权重),在本文中,权重都为1。

处理成邻接矩阵的程序如下:
import csv
import torch
import numpy as np
from torch.utils.data import Dataset
def get_adjacent_matrix(distance_file: str, num_nodes: int, id_file: str = None, graph_type="connect") -> np.array:
"""
:param distance_file: str, path of csv file to save the distances between nodes.
:param num_nodes: int, number of nodes in the graph
:param id_file: str, path of txt file to save the order of the nodes.就是排序节点的绝对编号所用到的,这里排好了,不需要
:param graph_type: str, ["connect", "distance"],这个就是考不考虑节点之间的距离
:return:
np.array(N, N)
"""
A = np.zeros([int(num_nodes), int(num_nodes)]) # 构造全0的邻接矩阵
if id_file: # 就是给节点排序的绝对文件,这里是None,则表示不需要
with open(id_file, "r") as f_id:
# 将绝对编号用enumerate()函数打包成一个索引序列,然后用node_id这个绝对编号做key,用idx这个索引做value
node_id_dict = {
int(node_id): idx for idx, node_id in enumerate(f_id.read().strip().split("\n"))}
with open(distance_file, "r") as f_d:
f_d.readline() # 表头,跳过第一行.
reader = csv.reader(f_d) # 读取.csv文件.
for item in reader: # 将一行给item组成列表
if len(item) != 3: # 长度应为3,不为3则数据有问题,跳过
continue
i, j, distance = int(item[0]), int(item[1]), float(item[2]) # 节点i,节点j,距离distance
if graph_type == "connect": # 这个就是将两个节点的权重都设为1,也就相当于不要权重
A[node_id_dict[i], node_id_dict[j]] = 1.
A[node_id_dict[j], node_id_dict[i]] = 1.
elif graph_type == "distance": # 这个是有权重,下面是权重计算方法
A[node_id_dict[i], node_id_dict[j]] = 1. / distance
A[node_id_dict[j], node_id_dict[i]] = 1. / distance
else:
raise ValueError("graph type is not correct (connect or distance)")
return A
with open(distance_file, "r") as f_d:
f_d.readline() # 表头,跳过第一行.
reader = csv.reader(f_d) # 读取.csv文件.
for item in reader: # 将一行给item组成列表
if len(item) != 3: # 长度应为3,不为3则数据有问题,跳过
continue
i, j, distance = int(item[0]), int(item[1]), float(item[2])
if graph_type == "connect": # 这个就是将两个节点的权重都设为1,也就相当于不要权重
A[i, j], A[j, i] = 1., 1.
elif graph_type == "distance": # 这个是有权重,下面是权重计算方法
A[i, j] = 1. / distance
A[j, i] = 1. / distance
else:
raise ValueError("graph type is not correct (connect or distance)")
return A
(2)读入流量数据
流量数据就是每个节点的特征数据,这个函数在说数据分析的时候其实已经写的差不多了,这里再看看,代码如下:
def get_flow_data(flow_file: str) -> np.array: # 这个是载入流量数据,返回numpy的多维数组
"""
:param flow_file: str, path of .npz file to save the traffic flow data
:return:
np.array(N, T, D)
"""
data = np.load(flow_file)
flow_data = data['data'].transpose([1, 0, 2])[:, :, 0][:, :, np.newaxis] # [N, T, D],transpose就是转置,让节点纬度在第0位,N为节点数,T为时间,D为节点特征
# [:, :, 0]就是只取第一个特征,[:, :, np.newaxis]就是增加一个维度,因为:一般特征比一个多,即使是一个,保持这样的习惯,便于通用的处理问题
return flow_data # [N, T, D]
(3)把前面读入的数据处理成模型所需要的train_data和test_data
交通数据处理和普通的数据处理是不太一样的,比如说计算机视觉中,一般一张图片就是一个样本,每个图片有一个标签,那这个就已经组合成了模型的训练标签数据,而交通数据是一连串的时序数据,怎么找到训练样本和测试样本呢?下面看看对于时序数据是怎么划分训练和测试数据的。
首先,对于时间序列,需要知道 滑动窗口 这个概念:
比如,2019-2020年里的365天数据,如果我们单拿出来2019-6-3 这个点的数据,用这个点的数据来描绘当前情况是可以的,但是有没有更好的方案呢。
分析:好像单拿出2019-6-3这个点的数据来描绘当前情况有点太绝对,它会不会有或多或少的误差,如果我想看一下2019-6-3的大致情况,我是不是可以取它的一个范围,比如2019-6-1、2019-6-2、···、2019-6-5,取这个区间的平均值来大概当做2019-6-3这天的情况,这是不是更科学些,尤其是当我们要进行预测的时候,单独拿出来一个或多或少会有些离群会有些差异,会影响我们的结果,所以我们可以基于这样一个窗口,通过窗口取平均,使得我们的数据是更平稳些。
那什么是窗口呢?
滑动窗口就是窗口向一端滑行,比如从左往右,每次滑动并不是窗口区间整块的滑行,而是一个单位一个单位的滑动。例如窗口2019-6-1到2019-6-5,下一个窗口并不是2019-6-5到2019-6-10,而是2019-6-2到2019-6-6(假设数据的截取是以天为单位),整体向右移动一个单位,而不是一个窗口。
窗口中的值从覆盖整个窗口的位置开始产生,在此之前即为NaN,举例如下:窗口大小为10,前9个都不足够为一个一个窗口的长度,因此都无法取值。
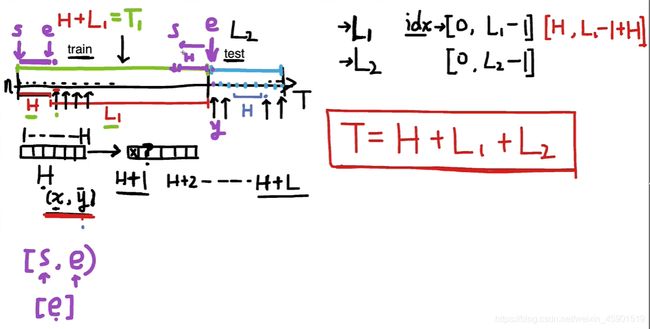
现在知道了滑动窗口,所以我们开始划分数据集,首先对于从0~T的时间序列划一刀,分为train_data 和 test_data,如下图所示:

然后我们以训练集为例来取一个一个的样本。具体而言,我们人为定义一个滑动窗口的大小,因为我要预测下一时刻的交通流量,所以这里我定义滑动窗口的大小为7。这个7就是一个样本,包含了输入样本 x x x 和 标签 y y y,具体如下图所示。我把 x x x的数据叫做历史数据 H H H,现在要做的是预测 H + 1 H+1 H+1 时刻的交通流量(当然别的问题可能是要预测多个时刻,这个同理),也就是标签 y ^ \hat y y^ ,所以正如下图所示,这就组成了一个训练的样本。最后就是把这个窗口按一个时间单位的一次移动,就得到了所有的训练样本。

理解完上面的部分,接下来就是取数据,对于取数据肯定会用到下标 idx ,也就是当我们从文件读入数据存入列表时,就要用下标 idx 来取出数据。这里需要注意,这个 idx 的范围是 ( H , L 1 − 1 + H ) (H ,L_1-1+H) (H,L1−1+H),如下图所示。下标是从0开始的,所以会减一。
L 1 L_1 L1 的值就是测试样本的数量。

测试集每个样本都能做测试,所以下标idx直接从test那里开始。
有了这些基础,还需要知道PyTorch中LoadData这个类是怎么写的,去官网看。下面看看实现的代码。
注意,看下面的代码,需要这么看:LoadData类其实就是在写下面的三个函数,其他的函数全是为了得到这三个函数而衍生的:
- init()函数
- len()函数
- getitem(self, index)
import csv
import torch
import numpy as np
from torch.utils.data import Dataset
class LoadData(Dataset): # 这个就是把读入的数据处理成模型需要的训练数据和测试数据,一个一个样本能读取出来
def __init__(self, data_path, num_nodes, divide_days, time_interval, history_length, train_mode):
"""
:param data_path: list, ["graph file name" , "flow data file name"], path to save the data file names.
:param num_nodes: int, number of nodes.
:param divide_days: list, [ days of train data, days of test data], list to divide the original data.
:param time_interval: int, time interval between two traffic data records (mins).---5 mins
:param history_length: int, length of history data to be used.
:param train_mode: list, ["train", "test"].
"""
self.data_path = data_path
self.num_nodes = num_nodes
self.train_mode = train_mode
self.train_days = divide_days[0] # 59-14 = 45, train_data
self.test_days = divide_days[1] # 7*2 = 14 ,test_data
self.history_length = history_length # 30/5 = 6, 历史长度为6
self.time_interval = time_interval # 5 min
self.one_day_length = int(24 * 60 / self.time_interval) # 一整天的数据量
self.graph = get_adjacent_matrix(distance_file=data_path[0], num_nodes=num_nodes)
self.flow_norm, self.flow_data = self.pre_process_data(data=get_flow_data(data_path[1]), norm_dim=1) # self.flow_norm为归一化的基
def __len__(self): # 表示数据集的长度
"""
:return: length of dataset (number of samples).
"""
if self.train_mode == "train":
return self.train_days * self.one_day_length - self.history_length # 训练的样本数 = 训练集总长度 - 历史数据长度
elif self.train_mode == "test":
return self.test_days * self.one_day_length # 每个样本都能测试,测试样本数 = 测试总长度
else:
raise ValueError("train mode: [{}] is not defined".format(self.train_mode))
def __getitem__(self, index): # 功能是如何取每一个样本 (x, y), index = [0, L1 - 1]这个是根据数据集的长度确定的
"""
:param index: int, range between [0, length - 1].
:return:
graph: torch.tensor, [N, N].
data_x: torch.tensor, [N, H, D].
data_y: torch.tensor, [N, 1, D].
"""
if self.train_mode == "train":
index = index # 训练集的数据是从时间0开始的,这个是每一个流量数据,要和样本(x,y)区别
elif self.train_mode == "test":
index += self.train_days * self.one_day_length # 有一个偏移量
else:
raise ValueError("train mode: [{}] is not defined".format(self.train_mode))
data_x, data_y = LoadData.slice_data(self.flow_data, self.history_length, index, self.train_mode) # 这个就是样本(x,y)
data_x = LoadData.to_tensor(data_x) # [N, H, D] # 转换成张量
data_y = LoadData.to_tensor(data_y).unsqueeze(1) # [N, 1, D] # 转换成张量,在时间维度上扩维
return {
"graph": LoadData.to_tensor(self.graph), "flow_x": data_x, "flow_y": data_y} #组成词典返回
@staticmethod
def slice_data(data, history_length, index, train_mode): # 根据历史长度,下标来划分数据样本
"""
:param data: np.array, normalized traffic data.
:param history_length: int, length of history data to be used.
:param index: int, index on temporal axis.
:param train_mode: str, ["train", "test"].
:return:
data_x: np.array, [N, H, D].
data_y: np.array [N, D].
"""
if train_mode == "train":
start_index = index #开始下标就是时间下标本身,这个是闭区间
end_index = index + history_length #结束下标,这个是开区间
elif train_mode == "test":
start_index = index - history_length # 开始下标,这个最后面贴图了,可以帮助理解
end_index = index # 结束下标
else:
raise ValueError("train model {} is not defined".format(train_mode))
data_x = data[:, start_index: end_index] # 在切第二维,不包括end_index
data_y = data[:, end_index] # 把上面的end_index取上
return data_x, data_y
@staticmethod
def pre_process_data(data, norm_dim): # 预处理,归一化
"""
:param data: np.array,原始的交通流量数据
:param norm_dim: int,归一化的维度,就是说在哪个维度上归一化,这里是在dim=1时间维度上
:return:
norm_base: list, [max_data, min_data], 这个是归一化的基.
norm_data: np.array, normalized traffic data.
"""
norm_base = LoadData.normalize_base(data, norm_dim) # 计算 normalize base
norm_data = LoadData.normalize_data(norm_base[0], norm_base[1], data) # 归一化后的流量数据
return norm_base, norm_data # 返回基是为了恢复数据做准备的
@staticmethod
def normalize_base(data, norm_dim): #计算归一化的基
"""
:param data: np.array, 原始的交通流量数据
:param norm_dim: int, normalization dimension.归一化的维度,就是说在哪个维度上归一化,这里是在dim=1时间维度上
:return:
max_data: np.array
min_data: np.array
"""
max_data = np.max(data, norm_dim, keepdims=True) # [N, T, D] , norm_dim=1, [N, 1, D], keepdims=True就保持了纬度一致
min_data = np.min(data, norm_dim, keepdims=True)
return max_data, min_data # 返回最大值和最小值
@staticmethod
def normalize_data(max_data, min_data, data): #计算归一化的流量数据,用的是最大值最小值归一化法
"""
:param max_data: np.array, max data.
:param min_data: np.array, min data.
:param data: np.array, original traffic data without normalization.
:return:
np.array, normalized traffic data.
"""
mid = min_data
base = max_data - min_data
normalized_data = (data - mid) / base
return normalized_data
@staticmethod
def recover_data(max_data, min_data, data): # 恢复数据时使用的,为可视化比较做准备的
"""
:param max_data: np.array, max data.
:param min_data: np.array, min data.
:param data: np.array, normalized data.
:return:
recovered_data: np.array, recovered data.
"""
mid = min_data
base = max_data - min_data
recovered_data = data * base + mid
return recovered_data #这个就是原始的数据
@staticmethod
def to_tensor(data):
return torch.tensor(data, dtype=torch.float)
对于slice_data()函数的理解看看下面,开始下标用s,结束下标用e.
最后为了测试数据处理的结果,写了一个main()函数来检测一下:
if __name__ == '__main__':
train_data = LoadData(data_path=["PeMS_04/PeMS04.csv", "PeMS_04/PeMS04.npz"], num_nodes=307, divide_days=[45, 14],
time_interval=5, history_length=6,
train_mode="train")
print(len(train_data))
print(train_data[0]["flow_x"].size())
print(train_data[0]["flow_y"].size())
运行结果:
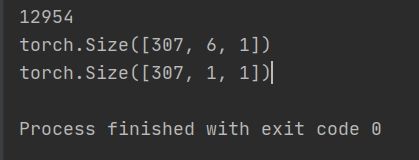
需要说明的是,保留1的维度,一是为了保持样本和标签一致,二是便于在别的数据上通用.
下一节开始基于此数据集来构造图卷积模型.