论文:

论文地址:https://arxiv.org/pdf/2006.11632v1.pdf
论文题目:《Embedding-based Retrieval in Facebook Search》
一 、背景
搜索引擎一直是帮助人们在线访问大量信息的重要工具。 在过去的几十年中,已经开发出各种技术来提高搜索质量,尤其是在包括Bing和Google在内的网络搜索引擎中。由于很难从查询文本准确地计算出搜索意图并表示文档的语义,因此搜索技术主要基于各种术语匹配方法,在关键字匹配可以解决的情况下效果很好。 语义匹配仍然是一个具有挑战性的问题,该问题是要解决与查询文本不完全匹配但可以满足用户搜索意图的期望结果。
不管是在搜索还是推荐领域,Embedding技术都被广泛的使用,这些领域中还划分为召回和排序两个阶段。一般而言,搜索引擎包括:召回层,旨在以低延迟和低计算量来检索一组相关文档(通常称为“检索”);以及精确层,其目标是通过更复杂的算法或模型将最需要的文档排在最前面, 通常称为排序。 尽管可以将Embedding应用于这两个层,但是在海量物品中挑选出一定数量级的候选集才是Embedding发挥作用的地方,因为与排序相比,召回更底层,是系统的瓶颈。
与传统的网络搜索相比,诸如Facebook之类的社交网络中的搜索面临着不同的挑战:除了查询文本外,重要的是要考虑搜索者的上下文,并根据这两者的信息来提供相关结果。他们的社交图谱是这种情况的组成部分,也是Facebook搜索的独特服务。尽管基于Embedding的检索(EBR)已在eb搜索引擎中应用了很多年,但Facebook搜索仍主要基于Boolean matching model(布尔匹配模型)。也就是说,在FB中搜索不单单是搜索文本和文档的匹配了,而要考虑用户信息和搜索的上下文环境了,演变成了个性化搜索的问题了。接下来我们就来介绍一下这篇工程性极强的论文吧。
二 、模型
facebook这篇文章从三个方面去阐述了他们应对的挑战--modeling, serving, and full-stack optimization.。所谓modelling其实就是如何建模的问题。在这个地方facebook提出了一种统一的embedding方式,也采用了经典的双塔结构,一侧是query,搜索者,上下文,另一侧则是document。
先看一下整个系统的构成吧:

可以看到整个搜索分为两个阶段,在这篇文章中重点讲的是召回阶段。我们可以从整个系统的架构图中看到,在召回阶段之前要先对query进行处理,也就是进行带有用户信息+上下文信息+搜索文本进行Embedding以便后面跟doc进行相似度计算。在看对doc的处理,在doc的处理中,Fb采用的也是经典的倒排索引技术以便能冲亿万级别的doc中快速选择对应的文档。在得到query和doc向量后,就会采用KNN近邻搜索算法来选取topk。
2.1 Model
2.1.1 评价标准
对于搜索引擎的召回模型而言,我们希望最大化top-K的recall结果。给定一个query,以及目标结果集T,和top-K个返回的结果。也就是,给定一个query,假设target集合是{t1,t2...},模型得到的结果是{d1,d2,...},那么recall@K的计算方式如下:

2.1.2 Loss

Fb用的是pairwise的优化方式,q是query,d+是正样本,d-是负样本,m是在正负两对之间强制加入的边距,N是从训练集中选择的三元组的总数。 该损失函数的直觉是将正对与负对分开一定距离。 Fb发现调整边距值很重要,最佳边距值在不同的训练任务中变化很大,并且不同的边距值会导致5-10%的KNN召回差异。
至于负样本是怎么来的,Fb在论文中也给了解释,他们认为负样本采用随机抽样的方式能给模型带来更好的提升效果。原因如下, 如果我们为训练数据中的每个正样本采样n个负样本,那么当候选库大小为n时,该模型将针对top 1这个位置的召回进行优化。而实际上,当候选库大小为N的时候,我们大约在top K ≈ N/n 处优化召回率。
2.1.3 Unified Embedding Model

依然是我们熟悉的双塔模型,左塔是query+searcher+context信息的Embedding,右塔是doc+social+location等信息的Embedding,相似度的计算选取余弦相似度:
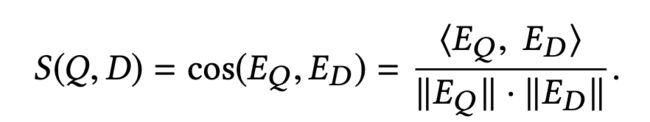
2.2.4 Training Data Mining
这节主要来讲一下负样本的采样方式,Fb通过采用来多种采样策略,并进行对比来得到最佳负采样方式。
FB采用未点击的样本作为负样本,有两种方式:
1. 随机负样本:从所有的样本池中随机sample出负样本。
2.曝光未点击作为负样本
对比一下这两种方式,Fb发现,采用曝光非点击的情况召回率比另一种少了将近55%,这是什么概念呢,就是说,这种负采样的方式给模型带来了负作用的影响。对此,Fb也给了解释,这些负面因素倾向于可能在一个或多个因素中与查询相匹配的困难案例中,而索引中的大多数文档都是简单案例,根本不与查询匹配。通俗的来说,在曝光未点击中,这些没点击的物品作为负样本只是在特定的case下与query不匹配的样本,但是在实际上大多数样本是不与query不匹配的简单案例,所以如果采用曝光未点击的话就不符合实际中的正负样本分布,模型训起来肯定会有问题。
在正样本的选取上,主要是:
1. click,这个是毫无疑问的
2.impression,论文的想法是,将检索视为排名的近似值,但可以快速执行。 此后,我们希望设计检索模型以学习返回将由排名者排名高的相同结果集。 从这个意义上说,显示给用户或印象深刻的所有结果对于检索模型学习都是同样积极的。
这两种在实验中的效果是差不多的,但是impression数据量是比click大得多的,起初Fb希望添加部分imprssion数据到click中进行训练,但是并没有带来效果上的提升。
三 、特征工程
facebook系列的文章都比较注重特征工程的东西,unified embeddings 大体上采用了三个方面的特征。
3.1 Text features
text embedding 采用了Character n-gram的形式来形成embedding。对比word n-gram这样做有两个好处一个是embedding table的大小会比较小,利于训练的效率。第二个是缓解OOV的问题。同时这块也比较了采用word n-gram的方式,发现Character n-gram 对于 word n-gram 有1.5%的提升。
3.2 Location features
位置特征对于社交网络还是比较重要的,很多搜索的述求还是限定在本地的商业/组等。所以facebook的模型引入了seacher的一些位置信息,以及document的位置信息。这个信息感觉在社交网络检索中比较由于在电商或者网页搜索位置信息就没那么重要了。
3.3 Social embedding features
这块Facebook额外的训练了一个Social graph embedding,然后把这个embedding作为特征输入到模型中。
四 、Serving
4.1 ANN
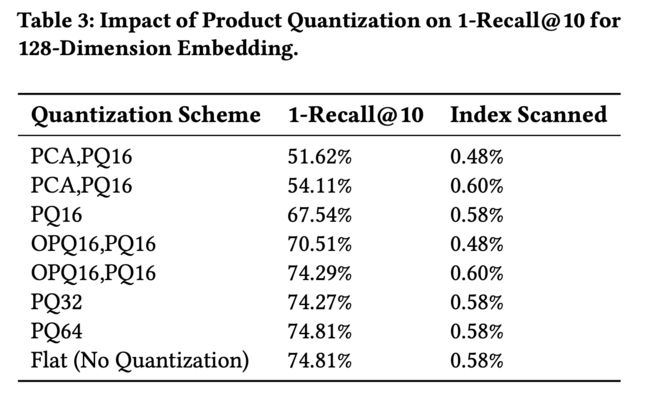
上面都是如何离线建模的问题,下面这块则是如何线上serving的问题。这块facebook也是采用了自家的Faiss 库进行线上的ANN的查询。同时对比了一下离线时几个重要的参数的使用Coarse quantization.,Product quantization,nprobe。
Fb是将Embedding技术跟倒排索引结合在一起了,Embedding量化有两个主要组成部分,一个是粗略量化,通常通过K-means算法将嵌入向量量化为粗聚类,另一个是乘积量化,它会进行细粒度量化以实现对 距离的计算。
Fb的各种参数这里就不进行解释了,感兴趣的可以去看看原论文。
4.2 System Implementation
为了将基于Embedding的检索集成到我们的服务堆栈中,FB在Unicorn 中实现了对NN搜索的一流支持,Unicorn是为Facebook上大多数搜索产品提供支持的检索引擎。 Unicorn将每个文档表示为一揽子术语,这些术语是任意字符串,用于表达有关文档的二进制属性,通常使用其语义来命名。 例如,居住在西雅图的用户John的术语为text:john和location:seattle。 术语可以附有有效载荷。
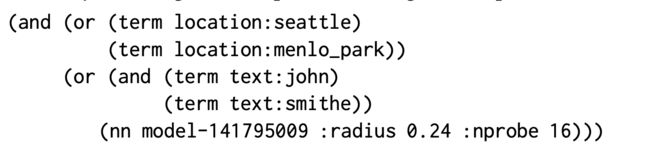
查询可以是条件上的任何布尔表达式:
例如,以下查询将返回名称中有john和smithe并且居住在Seattle或Menlo Park的所有人员:

模型在faiss的基础上,加上了对location和term text的索引,例如,假设一个错误拼写的查询约翰·史密斯(John smithe)在西雅图或门洛帕克(Menlo Park)寻找一个名叫约翰·史密斯(john smith)的人; 检索表达式将类似于上面的表达式,该表达式将无法检索有问题的用户,因为术语text:smithe将无法匹配该文档。 我们可以通过(nn)运算符为该表达式添加模糊匹配:
4.2.2 Model Serving
FB通过以下方式提供了embedding模型。 训练完双方embedding模型后,我们将该模型分解为query embedding模型和doc embedding模型,然后分别为这两个模型提供服务。 对于query embedding,我们将模型部署在在线嵌入推理服务中以进行实时推理。 对于文档,我们使用Spark在脱机批处理中进行模型推断,然后将生成的embedding内容与其他元数据一起发布到正向索引中。 我们还进行了其他嵌入量化,包括粗略量化和PQ,以将其发布为倒排索引。
4.3 Query and Index Selection
全量的document进行索引是非常耗存储和费时的,所以facebook在构建索引的时候,只选择了月活用户,近期事件,热门的事件,以及热门group。这块大部分公司在构建索引的时候都会采取这样的策略,很多长时间不活跃的可以不构建索引。
五、LATER-STAGE OPTIMIZATION
Facebook搜索排名是一个复杂的多阶段排名系统,其中每个阶段逐步完善前一阶段的结果。 该堆栈的最底部是检索层,在该层应用了基于Embedding的检索。 然后,将检索层的结果按一堆排名层进行排序和过滤。 在每个阶段的模型应该针对上一层返回的结果的分布进行优化。 但是,由于当前排名阶段是为现有检索方案设计的,因此这可能导致从基于嵌入的检索返回的新结果被现有排名者进行次优排名。 为了解决这个问题,我们提出了两种方法:
Embedding as ranking feature.
搜索包含了召回和排序两个阶段,召回分数高的用户不一定会点击,而且召回和ranking的排序列表不一致,所以可以将召回的分数(也就是向量的相似度)作为ranking阶段的一个特征,通过ranking模型进行统一排序。
Training data feedback loop
由于语义召回的结果召回高但是精度低,所以他们就采用了人工的方式对语义召回的结果进行标注,对每个query召回的结果进行标注。这样能够过滤掉不相关的结果,提升模型精度。(人工大法好)
六、 ADVANCED TOPICS
基于embedding的语义召回需要更加深入的分析才能不断提升性能,facebook给出了其中可以提升的重要方向一个是Hard Mining,另一个是Embedding Ensemble
6.1 Hard Mining
这部分主要是让模型充分进行学习,主要是从负样本入手。负样本如果只是简单随机的话还是不能对一些相近对doc进行区分的。同时,我们需要在训练过程中sample出来负样本,而不是训练之前就生成。
6.1.1 Hard negative mining (HNM)
文章发现很多时候同语义召回的结果,大部分都是相似的,而且没有区分度,最相似的结果往往还排不到前面,这些就是之前的训练样本太简单了,导致模型学习的不够充分。所以就想到了对应了解决方案,把那些和positive sample很近的样本作为负样本去训练,这样模型就能学到这种困难样本的区分信息。
6.1.2 Online hard negative mining.
因为模型是采用mini-batch的方式进行更新的,所以对每个batch中的positive pairs,都随机一些非常相似的负样本作为训练集,模型效果提升非常明显,同时页注意到了每隔 positive的pairs,最多只能有两个hard negative,不然的模型的效果会下降。
6.1.3 Offline hard negative mining

其实就是先对每隔query参数n个结果然后选择一些hard negative samples 进行重新训练。然后重复整个过程。同时根据经验 easy:hard=100:1
6.1.4 Hard positive mining
模型采用了用户点击的样本为正样本,但是还有一些用户未点击但是也能被认为是正样本的样本。这块他们从用户的session日志中挖掘到潜在的正样本。(如何挖掘文章没有提及)这块对模型的效果也是有一部分提升。
6.1.5 Embedding Ensemble
这块其实就是如何将多个模型融合的问题,采用不同正负样本比例训练出来的模型在不同的方面具有不同的优势,如何对这些模型进行融合。
第一种方案是采用加权求和的方式,Weighted Concatenation:
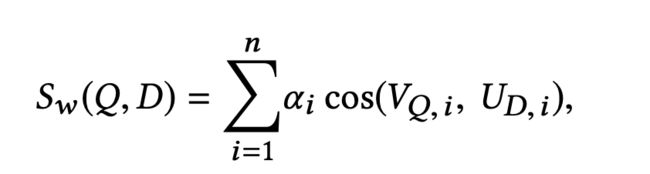

最后计算的方式:

采用融合的方式对于单模型而言有4.39%的提升。
这种加权融合的方式其实就是并行的方式,有点像bagging。
另一种方式是串行的方式,第二个模型在第一个模型的基础上训练。感觉就像bagging和boosting的区别。采用Cascade 的方式,模型也有3.4%的提升。
总结
这篇文章是工程性极强的论文,整个模型其实在算法上没有太大的创新性,但是,在工程方面给读者带来了很大的帮助,比如说是负样本的采样问题,以及怎么解决在线serving和离线训练等各种问题。这种论文想来在以后工作后在看一定会有不同的理解的。