日志采集框架Flume(二)进阶
日志采集框架Flume(二)进阶
-
Flume事务:
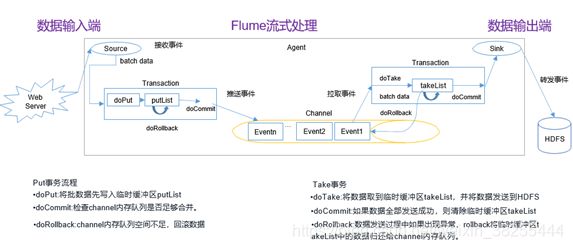
flume处理事务的流程分为两个部分(两个事件),数据输入端(Source–Channel端)和数据输出端(Channel—Sink端)。
数据输入端:Source将数据从web服务器抓取过来,然后进行doput到putList临时缓冲区,putList是一个队列形式的缓冲区,然后doCommit将putList提交到Channel中,doCommit检查Channel中的内存队列是否能够合并,如果能够合并,将一组数据放到一个事务中进行传递,当putList内存缓冲区中的空间不够使用时才会发生doRollback,进行事务回滚。
数据输出端:发生再channel与sink之间的事务,doTake将数据抓取到takeList缓冲区中,并进行写入HDFS中。doCommit将一组数据发送到Sink中,并判断数据是否全部发送成功,发送成功后,清空缓冲区。如果这一组数据中,有任何一个没有发送成功,doRollback就会将tabkeList中的数据回滚到channel中。
-
FlumeAgent内部原理

Source接收到Web服务器发送的数据后交给Channel中的事件处理器Channel Processor,时间处理器内部进行将数据传递给拦截器,对事件进行分类,加标记等一系列自定义拦截器处理,接着将每个事件交给Channe Selector(Channel选择器),进行选择相对应的Channel(传输通道),经过channel后,交给SinkProcessor,进行分配Sink(下沉组件),输出到目的地。
-
重要组件
-
ChannelSelector
ChannelSelector 的作用就是选出 Event 将要被发往哪个 Channel。其共有两种类型,分别是 Replicating(复制)和 Multiplexing(多路复用)。
ReplicatingSelector 会将同一个发往所有的,会根据相应的原则,将不同的发往不同的。
-
SinkProcessor
SinkProcessor共有三种类型,分别是:
DefaultSinkProcessor:对应的是单个的 Sink。
LoadBalancingSinkProcessor:对应的是 Sink Group,可以实现负载均衡的功能。
FailoverSinkProcessor: Sink Group
-
-
Flume的拓扑结构
-
简单串联:将多个flume线性串联起来。此模式不建议桥接过多的flume,flume数量过多会影响传输效率,一旦某个节点flume宕机,整个传输系统将会崩溃。
-
复制和多路复用

Flume支持将事件流向一个或者多个目的地。这种模式可以将相同数据复制到多个channel中,或者将不同数据分发到不同的channel中,sink可以选择传送到不同的目的地。
-
负载均衡和故障转移

Flume 支持使用将多个sink 逻辑上分到一个sink 组,sink 组配合不同的SinkProcessor可以实现负载均衡和错误恢复的功能。
-
聚合
-

这种模式是我们最常见的,也非常实用,日常 web 应用通常分布在上百个服务器,大者甚至上千个、上万个服务器。产生的日志,处理起来也非常麻烦。用 flume 的这种组合方式能很好的解决这一问题,每台服务器部署一个 flume 采集日志,传送到一个集中收集日志的flume,再由此 flume 上传到 hdfs、hive、hbase 等,进行日志分析。
-
企业开发
-
复制和多路复用
1 案例需求 使用 Flume-1 监控文件变动,Flume-1 将变动内容传递给 Flume-2,Flume-2 负责存储到 HDFS。同时 Flume-1 将变动内容传递给Flume-3,Flume-3 负责输出到Local FileSystem。 2 需求分析 flume-1:Exec Source -- Memory Channel --Avro、 Sink flume-2:Avro Source -- Memory Channel --HDFS Sink flume-3:Avro Source -- Memory Channel -- File_roll Sink 3 实现步骤 1. 准备工作 在/opt/module/flume/job 目录下创建 group1 文件夹 [ityouxin@hadoop102 job]$ mkdir group1 在/opt/module/datas/目录下创建 flume3 文件夹 [ityouxin@hadoop102 datas]$ mkdir flume3 2. 创建 flume-file-flume.conf 配置 1 个接收日志文件的 source 和两个 channel、两个 sink,分别输送给 flume-flume- hdfs 和 flume-flume-dir。 编辑配置文件: [ityouxin@hadoop102 group1]$ vim flume-file-flume.conf 添加如下内容: # Name the components on this agent a1.sources = r1 a1.sinks = k1 k2 a1.channels = c1 c2 # 将数据流复制给所有 channel a1.sources.r1.selector.type = replicating # Describe/configure the source a1.sources.r1.type = exec a1.sources.r1.command = tail -F /opt/module/hive/logs/hive.log a1.sources.r1.shell = /bin/bash -c # Describe the sink # sink 端的 avro 是一个数据发送者 a1.sinks.k1.type = avro a1.sinks.k1.hostname = hadoop102 a1.sinks.k1.port = 4141 a1.sinks.k2.type = avro a1.sinks.k2.hostname = hadoop102 a1.sinks.k2.port = 4142 # Describe the channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.channels.c2.type = memory a1.channels.c2.capacity = 1000 a1.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 c2 a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c2 3. 创建 flume-flume-hdfs.conf 配置上级 Flume 输出的 Source,输出是到 HDFS 的Sink。 编辑配置文件: [ityouxin@hadoop102 group1]$ vim flume-flume-hdfs.conf 添加如下内容: # Name the components on this agent a2.sources = r1 a2.sinks = k1 a2.channels = c1 # Describe/configure the source # source 端的 avro 是一个数据接收服务 a2.sources.r1.type = avro a2.sources.r1.bind = hadoop102 a2.sources.r1.port = 4141 # Describe the sink a2.sinks.k1.type = hdfs a2.sinks.k1.hdfs.path = hdfs://hadoop102:9000/flume2/%Y%m%d/%H #上传文件的前缀 a2.sinks.k1.hdfs.filePrefix = flume2- #是否按照时间滚动文件夹 a2.sinks.k1.hdfs.round = true #多少时间单位创建一个新的文件夹 a2.sinks.k1.hdfs.roundValue = 1 #重新定义时间单位 a2.sinks.k1.hdfs.roundUnit = hour #是否使用本地时间戳 a2.sinks.k1.hdfs.useLocalTimeStamp = true #积攒多少个 Event 才 flush 到 HDFS 一次 a2.sinks.k1.hdfs.batchSize = 100 #设置文件类型,可支持压缩 a2.sinks.k1.hdfs.fileType = DataStream #多久生成一个新的文件 a2.sinks.k1.hdfs.rollInterval = 600 #设置每个文件的滚动大小大概是 128M a2.sinks.k1.hdfs.rollSize = 134217700 #文件的滚动与 Event 数量无关 a2.sinks.k1.hdfs.rollCount = 0 # Describe the channel a2.channels.c1.type = memory a2.channels.c1.capacity = 1000 a2.channels.c1.transactionCapacity =100 # Bind the source and sink to the channel a2.sources.r1.channels = c1 a2.sinks.k1.channel = c1 4. 创建 flume-flume-dir.conf 配置上级 Flume 输出的 Source,输出是到本地目录的 Sink。 编辑配置文件: [ityouxin@hadoop102 group1]$ vim flume-flume-dir.conf 添加如下内容: # Name the components on this agent a3.sources = r1 a3.sinks = k1 a3.channels =c2 # Describe/configure the source a3.sources.r1.type = avro a3.sources.r1.bind = hadoop102 a3.sources.r1.port = 4142 # Describe the sink a3.sinks.k1.type =file_roll a3.sinks.k1.sink.directory = /opt/module/data/flume3 # Describe the channel a3.channels.c2.type = memory a3.channels.c2.capacity =1000 a3.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel a3.sources.r1.channels = c2 a3.sinks.k1.channel = c2 提示:输出的本地目录必须是已经存在的目录,如果该目录不存在,并不会创建新的目录。 5. 执行配置文件 分别启动对应的 flume 进程: flume-flume-dir,flume-flume-hdfs,flume-file-flume。 [ityouxin@hadoop102 flume]$ bin/flume-ng agent --conf a3 --conf-file job/group1/flume-flume-dir.conf [ityouxin@hadoop102 flume]$ bin/flume-ng agent --conf a2 --conf-file job/group1/flume-flume-hdfs.conf [ityouxin@hadoop102 flume]$ bin/flume-ng agent --conf a1 --conf-file job/group1/flume-file-flume.conf 6. 启动 Hadoop 和 Hive [ityouxin@hadoop102 hadoop-2.7.2]$ sbin/start-dfs.sh [ityouxin@hadoop103 hadoop-2.7.2]$ sbin/start-yarn.sh [ityouxin@hadoop102 hive]$ bin/hive hive (default)>insert into student values(1,"lhx"); -
故障转移
1 案例需求 使用 Flume1 监控一个端口,其 sink 组中的 sink 分别对接 Flume2 和Flume3,采用FailoverSinkProcessor,实现故障转移的功能。 2 需求分析 flume-1:netcat Source -- Memory Channel -- avro Sink flume-2:avro Source -- Memory Channel -- logger Sink flume-3:avro Source -- Memory Channel -- logger Sink 3 实现步骤 1. 准备工作 在/opt/module/flume/job 目录下创建 group2 文件夹 [ityouxin@hadoop102 job]$ cd group2/ 2. 创建 flume-netcat-flume.conf 配置 1 个 netcat source 和 1 个 channel、1 个 sink group(2 个 sink),分别输送给 flume- flume-console1 和 flume-flume-console2。 编辑配置文件: [ityouxin@hadoop102 group2]$ vim flume-netcat-flume.conf 添加如下内容: # Name the components on this agent a1.sources = r1 a1.channels = c1 a1.sinkgroups = g1 a1.sinks = k1 k2 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 a1.sinkgroups.g1.processor.type = failover a1.sinkgroups.g1.processor.priority.k1 = 5 a1.sinkgroups.g1.processor.priority.k2 = 10 # 退避期是10秒 a1.sinkgroups.g1.processor.maxpenalty = 10000 # Describe the sink a1.sinks.k1.type = avro a1.sinks.k1.hostname = hadoop102 a1.sinks.k1.port = 4141 a1.sinks.k2.type = avro a1.sinks.k2.hostname = hadoop102 a1.sinks.k2.port = 4142 # Describe the channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinkgroups.g1.sinks = k1 k2 a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c1 3. 创建 flume-flume-console1.conf 配置上级 Flume 输出的 Source,输出是到本地控制台。 编辑配置文件: [ityouxin@hadoop102 group2]$ vim flume-flume-console1.conf 添加如下内容: # Name the components on this agent a2.sources = r1 a2.sinks = k1 a2.channels = c1 # Describe/configure the source a2.sources.r1.type = avro a2.sources.r1.bind = hadoop102 a2.sources.r1.port = 4141 # Describe the sink a2.sinks.k1.type = logger # Describe the channel a2.channels.c1.type = memory a2.channels.c1.capacity = 1000 a2.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a2.sources.r1.channels = c1 a2.sinks.k1.channel = c1 4. 创建 flume-flume-console2.conf 配置上级 Flume 输出的 Source,输出是到本地控制台。 编辑配置文件: [ityouxin@hadoop102 group2]$ vim flume-flume-console2.conf 添加如下内容: # Name the components on this agent a3.sources = r1 a3.sinks = k1 a3.channels = c2 # Describe/configure the source a3.sources.r1.type = avro a3.sources.r1.bind = hadoop102 a3.sources.r1.port = 4142 # Describe the sink a3.sinks.k1.type = logger # Describe the channel a3.channels.c2.type = memory a3.channels.c2.capacity = 1000 a3.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel a3.sources.r1.channels = c2 a3.sinks.k1.channel = c2 5. 执行配置文件 分别开启对应配置文件:flume-flume-console2,flume-flume-console1,flume-netcat-flume。 [ityouxin@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a3 --conf-file job/group2/flume-flume-console2.conf -Dflume.root.logger=INFO,console [ityouxin@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a2 --conf-file job/group2/flume-flume-console1.conf -Dflume.root.logger=INFO,console [ityouxin@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a1 --conf-file job/group2/flume-netcat-flume.conf 6. 使用 netcat 工具向本机的 44444 端口发送内容 $ nc localhost 44444 7. 查看 Flume2 及 Flume3 的控制台打印日志 8. 将 Flume2 kill,观察 Flume3 的控制台打印情况。 注:使用 jps -ml 查看 Flume 进程。 -
负载均衡
1 案例需求 使用 Flume1 监控一个端口,其 sink 组中的 sink 分别对接 Flume2 和Flume3,采用LoadBalancingSinkProcessor,实现负载均衡的功能。 2 需求分析 flume-1:netcat Source -- Memory Channel -- avro Sink flume-2:avro Source -- Memory Channel -- logger Sink flume-3:avro Source -- Memory channel -- logger Sink 3 实现步骤 1. 准备工作 在/opt/module/flume/job 目录下创建 group2 文件夹 [ityouxin@hadoop102 job]$ cd group2/ 2. 创建 flume-netcat-flume.conf 配置 1 个 netcat source 和 1 个 channel、1 个 sink group(2 个 sink),分别输送给 flume- flume-console1 和 flume-flume-console2。 编辑配置文件: [ityouxin@hadoop102 group2]$ vim flume-netcat-flume.conf 添加如下内容: # Name the components on this agent a1.sources = r1 a1.channels = c1 a1.sinkgroups = g1 a1.sinks = k1 k2 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # 配置负载均衡 a1.sinkgroups.g1.sinks = k1 k2 a1.sinkgroups.g1.processor.type = load_balance a1.sinkgroups.g1.processor.backoff = true a1.sinkgroups.g1.processor.selector = random # Describe the sink a1.sinks.k1.type = avro a1.sinks.k1.hostname = hadoop102 a1.sinks.k1.port = 4141 a1.sinks.k2.type = avro a1.sinks.k2.hostname = hadoop102 a1.sinks.k2.port = 4142 # Describe the channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinkgroups.g1.sinks = k1 k2 a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c1 3. 创建 flume-flume-console1.conf 配置上级 Flume 输出的 Source,输出是到本地控制台。 编辑配置文件: [ityouxin@hadoop102 group2]$ vim flume-flume-console1.conf 添加如下内容: # Name the components on this agent a2.sources = r1 a2.sinks = k1 a2.channels = c1 # Describe/configure the source a2.sources.r1.type = avro a2.sources.r1.bind = hadoop102 a2.sources.r1.port = 4141 # Describe the sink a2.sinks.k1.type = logger # Describe the channel a2.channels.c1.type = memory a2.channels.c1.capacity = 1000 a2.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a2.sources.r1.channels = c1 a2.sinks.k1.channel = c1 4. 创建 flume-flume-console2.conf 配置上级 Flume 输出的 Source,输出是到本地控制台。 编辑配置文件: [ityouxin@hadoop102 group2]$ vim flume-flume-console2.conf 添加如下内容: # Name the components on this agent a3.sources = r1 a3.sinks = k1 a3.channels = c2 # Describe/configure the source a3.sources.r1.type = avro a3.sources.r1.bind = hadoop102 a3.sources.r1.port = 4142 # Describe the sink a3.sinks.k1.type = logger # Describe the channel a3.channels.c2.type = memory a3.channels.c2.capacity = 1000 a3.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel a3.sources.r1.channels = c2 a3.sinks.k1.channel = c2 5. 执行配置文件 分别开启对应配置文件:flume-flume-console2,flume-flume-console1,flume-netcat-flume。 [ityouxin@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a3 --conf-file job/group2/flume-flume-console2.conf -Dflume.root.logger=INFO,console [ityouxin@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a2 --conf-file job/group2/flume-flume-console1.conf -Dflume.root.logger=INFO,console [ityouxin@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a1 --conf-file job/group2/flume-netcat-flume.conf 6. 使用 netcat 工具向本机的 44444 端口发送内容 $ nc localhost 44444 7. 查看 Flume2 及 Flume3 的控制台打印日志 8. 将 Flume2 kill,观察 Flume3 的控制台打印情况。 注:使用 jps -ml 查看 Flume 进程。 -
聚合
1 需求分析 hadoop102 上的Flume-1 监控文件/opt/module/data/group.log,hadoop103 上的Flume-2 监控某一个端口的数据流,Flume-1 与 Flume-2 将数据发送hadoop104 上的 Flume-3,Flume-3 将最终数据打印到控制台。 2 案例分析 hadoop102:flume-1:Exec Source -- Memory Channel -- Arvo Source hadoop103:flume-2:Netcat Source -- Memory Channel --Avro Sink hadoop104:flume-3:Avro Source -- Memory Channel -- logger Channel 3 实现步骤 1. 准备工作 分发 Flume [ityouxin@hadoop102 module]$ xsync flume 在hadoop102、hadoop103 以及hadoop104 的/opt/module/flume/job 目录下创建一个group3文件夹。 [ityouxin@hadoop102 job]$ mkdir group3 [ityouxin@hadoop103 job]$ mkdir group3 [ityouxin@hadoop104 job]$ mkdir group3 2. 创建 flume1-logger-flume.conf 配置 Source 用于监控 hive.log 文件,配置 Sink 输出数据到下一级 Flume。在 hadoop102 上编辑配置文件 [ityouxin@hadoop102 group3]$ vim flume1-logger-flume.conf 添加如下内容: # Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = exec a1.sources.r1.command = tail -F /opt/module/group.log a1.sources.r1.shell = /bin/bash -c # Describe the sink a1.sinks.k1.type = avro a1.sinks.k1.hostname = hadoop104 a1.sinks.k1.port = 4141 # Describe the channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 3. 创建 flume2-netcat-flume.conf 配置 Source 监控端口 44444 数据流,配置 Sink 数据到下一级 Flume:在 hadoop103 上编辑配置文件 [ityouxin@hadoop102 group3]$ vim flume2-netcat-flume.conf 添加如下内容 # Name the components on this agent a2.sources = r1 a2.sinks = k1 a2.channels = c1 # Describe/configure the source a2.sources.r1.type = netcat a2.sources.r1.bind = hadoop103 a2.sources.r1.port = 44444 # Describe the sink a2.sinks.k1.type = avro a2.sinks.k1.hostname = hadoop104 a2.sinks.k1.port = 4141 # Use a channel which buffers events in memory a2.channels.c1.type = memory a2.channels.c1.capacity = 1000 a2.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a2.sources.r1.channels = c1 a2.sinks.k1.channel = c1 4. 创建 flume3-flume-logger.conf 配置 source 用于接收 flume1 与 flume2 发送过来的数据流,最终合并后 sink 到控制台。在 hadoop104 上编辑配置文件 [ityouxin@hadoop104 group3]$ touch flume3-flume-logger.conf [ityouxin@hadoop104 group3]$ vim flume3-flume-logger.conf 添加如下内容 # Name the components on this agent a3.sources = r1 a3.sinks = k1 a3.channels = c1 # Describe/configure the source a3.sources.r1.type = avro a3.sources.r1.bind = hadoop104 a3.sources.r1.port = 4141 # Describe the sink a3.sinks.k1.type = logger # Describe the channel a3.channels.c1.type = memory a3.channels.c1.capacity = 1000 a3.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a3.sources.r1.channels = c1 a3.sinks.k1.channel = c1 5. 执行配置文件 分别开启对应配置文件:flume3-flume-logger.conf,flume2-netcat-flume.conf,flume1- logger-flume.conf。 [ityouxin@hadoop104 flume]$ bin/flume-ng agent --conf conf/ --name a3 -conf-file job/group3/flume3-flume-logger.conf -Dflume.root.logger=INFO,console [ityouxin@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a2 --conf-file job/group3/flume1-logger-flume.conf [ityouxin@hadoop103 flume]$ bin/flume-ng agent --conf conf/ --name a1 --conf-file job/group3/flume2-netcat-flume.conf 6. 在 hadoop103 上向/opt/module 目录下的 group.log 追加内容 [ityouxin@hadoop103 module]$ echo 'hello' > group.log 7. 在 hadoop102 上向 44444 端口发送数据 [ityouxin@hadoop102 flume]$ nc localhost 44444 8. 检查 hadoop104 上数据
-