MySQL、Oracle、Sql Server、Hive、Spark SQL、Flink SQL总结
本文主要讲解各类SQL语言的优缺点、数据类型及SQL语法的区别,其它区别可参加各官网
MySQL
官网地址:https://dev.mysql.com/doc/refman/8.0/en/programs.html
优点:
(1).体积小、速度快、总体拥有成本低,支持多种操作系统,使用简单,开放源码,稳定性高;
(2).提供的接口支持多种语言连接操作。可以工作在不同的平台上。支持C、C++、Java、Perl、PHP、Python和TCL API;
(3).它使用的核心线程是完全多线程,支持多处理器,能很容易充分利用CPU;
(4).非常灵活而且安全的权限和口令系统;
(5).支持多种可视化连接工具,操作简单;
(6).它通过一个高度优化的类库实现SQL函数库并像他们能达到的一样快速,通常在查询初始化后不该有任何内存分配。没有内存漏洞。
(7).所有列都有缺省值。你可以用INSERT插入一个表列的子集,那些没用明确给定值的列设置为他们的决省值。
缺点:
(1).是一个小型关系型数据库管理系统,不适合做海量数据的存储;
(2).不支持热备份;
(3).其安全系统复杂而非标准,另外只有到调用mysqladmin来重读用户权限时才发生改变;
(4).没有一种存储过程(Stored Procedure)语言,这是对习惯于企业级数据库的程序员的最大限制;
(5).MySQL的价格随平台和安装方式变化。Linux的MySQL如果由用户自己或系统管理员而不是第三方安装则是免费的,第三方案则必须付许可费。Unix或Linux 自行安装 免费 、Unix或Linux 第三方安装 收费;
支持的数据类型:
1.数值类型

2.日期与时间类型

3.字符串类型
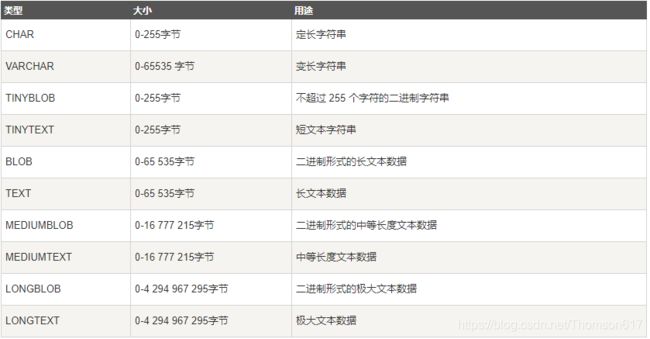
查询语法方面:
SELECT
[ALL | DISTINCT | DISTINCTROW ]
[HIGH_PRIORITY]
[STRAIGHT_JOIN]
[SQL_SMALL_RESULT] [SQL_BIG_RESULT] [SQL_BUFFER_RESULT]
SQL_NO_CACHE [SQL_CALC_FOUND_ROWS]
select_expr [, select_expr ...]
[FROM table_references
[PARTITION partition_list]
[WHERE where_condition]
[GROUP BY {col_name | expr | position}, ... [WITH ROLLUP]]
[HAVING where_condition]
[WINDOW window_name AS (window_spec)
[, window_name AS (window_spec)] ...]
[ORDER BY {col_name | expr | position}
[ASC | DESC], ... [WITH ROLLUP]]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
[INTO OUTFILE 'file_name'
[CHARACTER SET charset_name]
export_options
| INTO DUMPFILE 'file_name'
| INTO var_name [, var_name]]
[FOR {UPDATE | SHARE} [OF tbl_name [, tbl_name] ...] [NOWAIT | SKIP LOCKED]
| LOCK IN SHARE MODE]]
全面支持SQL的GROUP BY和ORDER BY子句,支持聚合函数(COUNT()、COUNT(DISTINCT)、AVG()、STD()、SUM()、MAX()和MIN())。你可以在同一查询中混来自不同数据库的表。
更多详细说明请参见官网:https://dev.mysql.com/doc/refman/8.0/en/select.html
Oracle
官方网址:https://docs.oracle.com/en/database/oracle/oracle-database/index.html
优点:
(1).开放性:Oracle 能所有主流平台上运行(包括 windows),完全支持所有工业标准,采用完全开放策略;
(2).可伸缩性,并行性:Oracle 并行服务器通过让主节点共享同簇工作来扩展windownt能力提供高可用性和高伸缩性;
(3).安全性:获得最高认证级别的ISO标准认证。
(4).性能:Oracle 性能高 保持开放平台下TPC-D和TPC-C世界记录;
(5).客户端支持及应用模式:Oracle 多层次网络计算支持多种工业标准用ODBC、JDBC、OCI等网络客户连接;
(6).使用风险:Oracle 长时间开发经验完全向下兼容得广泛应用地风险低
缺点:
(1).对硬件的要求很高;
(2).价格比较昂贵,维护成本高;
(3).操作比较复杂,需要技术含量较高.
常用的数据类型
| 字段类型 | 中文说明 | 限制条件 | 其它说明 |
|---|---|---|---|
| CHAR | 固定长度字符串 | 最大长度2000 bytes | |
| VARCHAR2 | 可变长度的字符串 | 最大长度4000 bytes | 可做索引的最大长度749 |
| NCHAR | 根据字符集而定的固定长度字符串 | 最大长度2000 bytes | |
| NVARCHAR2 | 根据字符集而定的可变长度字符串 | 最大长度4000 bytes | |
| DATE | 日期(日-月-年) | DD-MM-YY(HH-MI-SS) | 经过严格测试,无千虫问题 |
| LONG | 超长字符串 | 最大长度2G(231-1) | 足够存储大部头著作 |
| RAW | 固定长度的二进制数据 | 最大长度2000 bytes | 可存放多媒体图象声音等 |
| LONG RAW | 可变长度的二进制数据 | 最大长度2G 同上 | |
| BLOB | 二进制数据 | 最大长度4G | |
| CLOB | 字符数据 | 最大长度4G | |
| NCLOB | 根据字符集而定的字符数据 | 最大长度4G | |
| BFILE | 存放在数据库外的二进制数据 | 最大长度4G | |
| ROWID | 数据表中记录的唯一行号 | 10 bytes | ********.****.****格式,*为0或1 |
| NROWID | 二进制数据表中记录的唯一行号 | 最大长度4000 bytes | |
| NUMBER(P,S) | 数字类型 | P为总位数,S为小数位数 | |
| DECIMAL(P,S) | 数字类型 | P为总位数,S为小数位数 | |
| INTEGER | 整数类型 | 小的整数 | |
| FLOAT | 浮点数类型 | NUMBER(38),双精度 | |
| REAL | 实数类型 | NUMBER(63),精度更高 |
查询语法方面
Oracle查询语法和MySQL大同小异.
更多详细说明请参见官网:https://docs.oracle.com/en/database/oracle/oracle-database/19/sqlrf/SELECT.html#GUID-CFA006CA-6FF1-4972-821E-6996142A51C6
SQL SERVER
官网地址:https://www.microsoft.com/zh-cn/sql-server/sql-server-2017
优点:
(1).易用性、适合分布式组织的可伸缩性、用于决策支持的数据仓库功能、与许多其他服务器软件紧密关联的集成性、良好的性价比等;
(2).为数据管理与分析带来了灵活性,允许单位在快速变化的环境中从容响应。
(3).充分利用任务关键型智能应用程序和数据仓库的突破性的可扩展性、性能和可用性。
(4).具备完全Web支持的数据库产品,提供了对可扩展标记语言 (XML)的核心支持以及在Internet上和防火墙外进行查询的能力;
(5).端到端移动 BI:将原始数据转化为可发送到任何设备的有意义报告 - 成本为其他自助服务解决方案的成本的四分之一;
(6).实时智能:以高达 1000,000 次预测/秒的实时分析速度获取变革性的业务见解。
缺点:
(1).开放性 :SQL Server 只能windows上运行,没有丝毫开放性操作系统;
(2).伸缩性与并行性 :SQL server 并行实施和共存模型并成熟难处理日益增多用户数和数据卷伸缩性有限;
(3).安全性:没有获得任何安全证书。
(4).客户端支持及应用模式:只支持C/S模式,SQL Server C/S结构只支持windows客户用ADO、DAO、OLEDB、ODBC连接;
Sql Server数据类型:
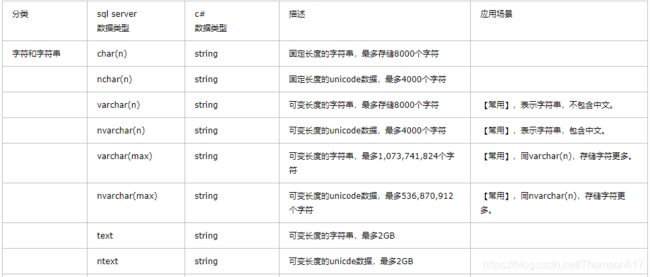
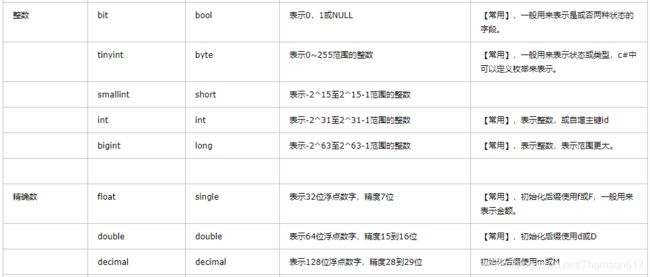
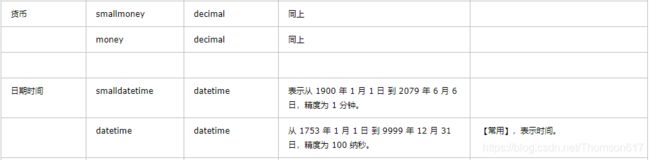

查询语法
SELECT [TOP n] [列名] FROM [表名]
[WHERE <查询条件表达式>]
[GROUP BY <字段列表>]
[HAVING 条件]
[ORDER BY <排序的列名> [ASC或DESC]]
更详细说明可查看此处.
HIVE
官网地址:https://cwiki.apache.org/confluence/display/Hive/LanguageManual
优点:
(1).支持海量数据处理,适合对实时性要求不高的场合;
(2).HQL语法为类sql语法,提供快速开发的能力,容易上手;
(3).避免了去写mapreduce的大量Java代码,降低复杂度,减少开发人员的学习成本;
(4).支持自定义函数(包括UDF一对一,UDAF多对一和UDTF一对多),可根据项目需求来实现自己的业务逻辑.
缺点:
(1).底层走的是MapReduce,高延迟;
(2).对于特别的业务逻辑不好处理,需要开发人员有很高的HQL功底和Java功底;
(3).最容易产生数据倾斜,调优困难.
数据类型
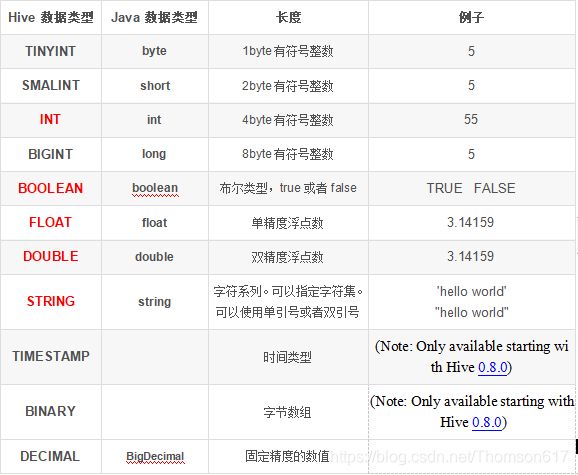
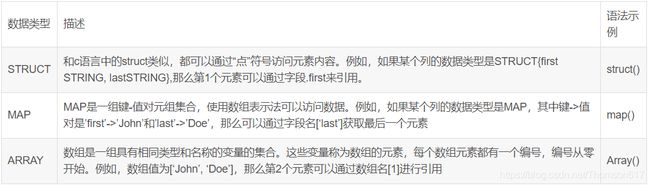
HQL语法:
[WITH CommonTableExpression (, CommonTableExpression)*] (Note: Only available starting with Hive 0.13.0)
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ORDER BY col_list]
[CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY col_list]
]
[LIMIT [offset,] rows]
SELECT语句可以是union查询的一部分,也可以是另一个查询的子查询。
table_reference表示查询的输入。它可以是常规表、视图、连接构造或子查询。
表名和列名不区分大小写。
注意事项:
(1).Hive不支持join的非等值连接,不支持or
(2).分号字符:分号是SQL语句结束标记,在HiveQL中也是.Hive不能智能识别concat(';',key),只会将 ';' 当做SQL结束符号,可以使用'\073'进行转义。
(3).不支持INSERT INTO 表 Values(), UPDATE, DELETE等操作.这样的话,就不要很复杂的锁机制来读写数据。
(4).HiveQL中String类型的字段若是空(empty)字符串, 即长度为0, 那么对它进行IS NULL的判断结果是False,使用left join可以进行筛选行。
(5).不支持 ‘< dt <’这种格式的范围查找,可以用dt in(”,”)或者between替代。
(6).Hive不支持将数据插入现有的表或分区中,仅支持覆盖重写整个表.
(7).group by的字段,必须是select后面的字段,select后面的字段不能比group by的字段多.
如果select后面有聚合函数,则该select语句中必须有group by语句
而且group by后面不能使用别名
(8).hive的0.13版之前select , where 及 having 之后不能跟子查询语句(一般使用left join、right join 或者inner join替代)
(9).先join(及inner join) 然后left join或right join
(10).hive不支持group_concat方法,可用 concat_ws('|', collect_set(str)) 实现
(11).not in 和 <> 不起作用,可用left join tmp on tableName.id = tmp.id where tmp.id is null 替代实现
更多详细介绍请参见官网说明:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Select
IMPALA
官网地址:http://impala.apache.org/impala-docs.html
impala是基于Hive运行的,元数据由Hive管理,这里不做过多介绍.
语法和HQL基本一个,只有少数不支持的内置函数,利于Hive中的collect_set()和collect_list()在impala中是不支持的.
SPARK SQL
官网地址:http://spark.apache.org/docs/latest/sql-programming-guide.html
Spark SQL是一个用于结构化数据处理的Spark模块。与基本的Spark RDD API不同,Spark SQL提供的接口为Spark提供了关于数据结构和正在执行的计算的更多信息。在内部,Spark SQL使用这些额外的信息来执行额外的优化。有几种与Spark SQL交互的方法,包括SQL和数据集API。
在计算结果时,使用相同的执行引擎,而不依赖于用于表示计算的API/语言。这种统一意味着开发人员可以很容易地在不同的api之间来回切换,这些api提供了最自然的方式来表达给定的转换。
Spark SQL的一个用途是执行SQL查询。Spark SQL还可以用于从现有Hive安装中读取数据。有关如何配置此功能的更多信息,请参阅Hive Tables部分。在另一种编程语言中运行SQL时,结果将作为数据集/DataFrame返回。您还可以使用命令行或JDBC/ODBC与SQL接口交互。
可以使用Scala或Java编程语言,通过一系列的算子对数据进行转化与计算;也可以通过配置直接在spark shell中运行HiveQL语句.
Spark 2.0中的SparkSession为Hive特性提供了内置支持,包括使用HiveQL编写查询、访问Hive udf和从Hive表读取数据的能力。要使用这些特性,我们不需要现有的Hive设置。
优点:
(1).易整合:将sql查询与spark程序无缝混合,可以使用java、scala、python、R等语言的API操作。
(2).统一的数据访问 :以相同的方式连接到任何数据源( 包括hive、 json、 parquet、 jdbc等等)。
(3).兼容hive.
(4).标准的数据连接.
(5).高效低延迟,查询速度快.
缺点:
(1).数据量过大(1T以上)时没有MapReduce并行处理的效果好;
(2).Spark是基于内存的,对内存要求比较高,程序设计不合理或处理数据庞大容易造成OOM异常.
(3).少量的Hive高级查询在Spark SQL中是不支持的.
更多说明请参见官网:http://spark.apache.org/docs/latest/sql-getting-started.html
Flink SQL(Streaming SQL)
官网地址:https://ci.apache.org/projects/flink/flink-docs-release-1.7/dev/api_concepts.html
Apache Flink是一个用于分布式流和批处理数据的开源平台。Flink的核心是一个流数据流引擎,它为数据流上的分布式计算提供数据分发、通信和容错功能。Flink在流引擎之上构建批处理、覆盖本地迭代支持、托管内存和程序优化。
Table API是用于流和批处理的统一关系API。表API查询可以在批量或流式输入上运行而无需修改。Table API是SQL语言的超级集合,专门用于Apache Flink。Table API是Scala和Java的语言集成API。Table API查询不是像SQL中常见的那样将查询指定为String值,而是在Java或Scala中以嵌入语言的样式定义,并支持自动完成和语法验证等IDE支持。
Flink SQL 优缺点:
Flink SQL优点:易于平台化、开发效率高、维度成本低等、查询速度快。
Flink SQL缺陷:
(1).语法和Hive SQL有一定区别;
(2).自定义函数UDF不如Hive丰富,写UDF的频率高于 Hive。
Flink Table的数据类型:

注意:泛型类型和(嵌套的)复合类型(例如,pojo、元组、行、Scala case类)也可以是行中的字段。
可以使用值访问函数访问具有任意嵌套的复合类型的字段。
泛型类型被视为黑盒,可以由用户定义的函数传递或处理。
**更多说明请参见官网:**https://ci.apache.org/projects/flink/flink-docs-release-1.7/dev/table/tableApi.html
与博文:https://blog.csdn.net/aA518189/article/details/83992129
参考文章:
https://www.cnblogs.com/ly133333333333333/p/7784605.html
http://www.runoob.com/mysql/mysql-data-types.html
http://www.cnblogs.com/mcgrady/p/5776255.html