“九韶杯”河科院程序设计协会第一届程序设计竞赛 【前六题解析】
https://ac.nowcoder.com/acm/contest/13493#rank
目录
- A: 6的个数
- B: 小明的作业
- C: 斐波那契
- D: 数列重组
- E: 三角形个数
- F: 字符串
A: 6的个数

https://ac.nowcoder.com/acm/contest/13493/A
签到题
#includeB: 小明的作业

https://ac.nowcoder.com/acm/contest/13493/B
唉,数的时候加错了,算成了68 25
正确答案是 78 和 25。
大致思路就是: 将wa转换成一个特殊的符号。aw也转换成一个特殊的符号 ;例如 &&
将其他的字符弄成空格。看输出的挨个数,&&是警告 长的例如&&&&就是错误的。
#include
cout<<78<<endl;
cout<<25<<endl;
return 0;
}

文件操作:
我上面的那种毕竟需要手数。不是纯编程的,那么我想了一下纯编程的。
才发现好麻烦。
文件操作有一个大坑,记住不要用笔记本的替换字符功能,太坑了。

大致思路就是,还是上面的处理操作。不过把输出的内容输出到一个文本。
我们从文本里读取处理后的字符串,统计个数。
处理字符的时候注意: wa 和 aw的变换字符要不相同。不然会问题。
例: wawaaw
要处理为 &&&&** 要统一处理的话就是 &&&&&& 统计的结果明显是不同的
#include
freopen("1.txt","r",stdin);//从文件中读取 统计个数
getline(cin,a);
int count1=0;//看读取了几个字符
int count2=0;//卡读取了几个字符
bool flag1=false;//判断读取到了
bool flag2=false;//判断读取到了特殊字符
for(int i=0;i<a.size();i++)
{
if(a[i]=='&')//读取到了特殊字符
{
count1++;//计数加一
flag1=true;//判断开始
continue;
}
if(flag1&&a[i]!='&')//说明是&开头的字符,且这一串的&已经读取完了
{
if(count1>2) sum2++;//说明是一个连着的字符
else sum1++;//说明是单个的字符
count1=0;
flag1=false;
}
if(a[i]=='*')
{
count2++;
flag2=true;
continue;
}
if(flag2&&a[i]!='*')
{
if(count2>2) sum2++;
else sum1++;
count2=0;
flag2=false;
}
}
cout<<sum1<<endl;
cout<<sum2<<endl;
return 0;
}

还是第一种香,方便。第二种容易出错。
C: 斐波那契
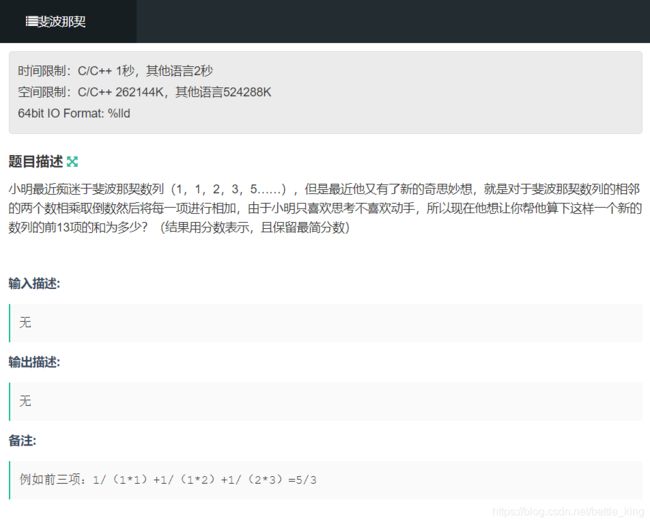
https://ac.nowcoder.com/acm/contest/13493/C
关键点: 在计算的时候要记得求分子和分母的最大共约数约分,不要会爆long long
我计算的时候是先打表 斐波那契前20项
再打表分母前13项。一边看一下有没有出错。
一边看一下,会不会爆long long 。
大致看了一下,一定会爆的。那么我们在每次两数相加的时候,通分一下就好了(即分子和分母同时除以两者的最大共约数)。
#include
return 0;
}
D: 数列重组

https://ac.nowcoder.com/acm/contest/13493/D
注意: 题目问的是有几种排列的方式。是全列列中,看有没有满足条件的。
我最开始以为是全排列后,再分不同的堆,不同的分法是不同种。好吧眼瞎了没有看提示。
本题用is_sort()函数及其的方便。感兴趣的可以搜一搜具体的用法。
#includeE: 三角形个数
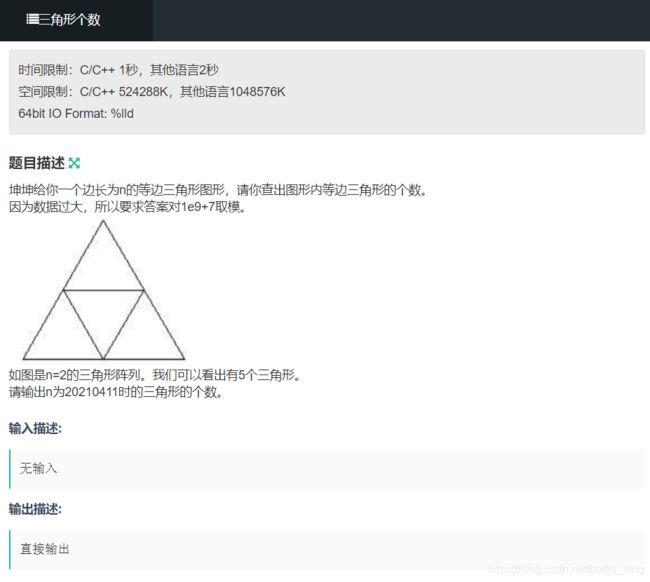
https://ac.nowcoder.com/acm/contest/13493/E
数学问题,找规律,推出公式。
官方题解是这样的:

套公式看一下规律:

其实这个道题的大致思路:
就是看 从1~n边长的所有的 正着的三角形的个数和倒着的三角形的个数之和。
说实话,这规律我觉得不容易推,何况考试的时候紧张和慌不好找,建议记住大致的公式模板。
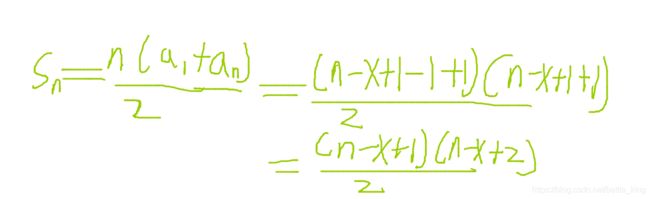
#includeF: 字符串

https://ac.nowcoder.com/acm/contest/13493/F
挺简单的,不过考完后看了一下自己AC的代码,感觉写的真的垃圾。
#include复盘的时候,一想 直接用string的find()函数它不爽么?
#include其实可以一边输入,一边统计
#include官方题解也不错
#include