Python 关于pymongo插入一条文档退出
文章目录
-
- 1. 问题描述
- 2. 问题分析
- 3. 解决问题
-
- 3.1 删除_id字段
- 3.2 浅拷贝
- 3.3 主动添加_id字段
- 4. 补充
1. 问题描述
又是写爬虫的一天,今天在把数据保存在MongoDB时出现了一点问题,插入一条文档后程序直接退出
xxx/items.py 中定义了一个字典,里面有若干字段
job51_item = {
'job_name': '',
'salary': '',
'job_welf': '',
'work_area': '',
'company_name': '',
'company_size': '',
'company_type': '',
'issue_date': '',
'job_href': ''
}
xxx/spiders/job51_threading.py 是具体的爬虫程序,部分代码如下:
for job in result:
job51_item['job_name'] = job.get('job_name')
job51_item['salary'] = job.get('providesalary_text')
job51_item['job_welf'] = job.get('jobwelf')
job51_item['work_area'] = job.get('workarea_text')
job51_item['company_name'] = job.get('company_name')
job51_item['company_size'] = job.get('companysize_text')
job51_item['company_type'] = job.get('companytype_text')
job51_item['issue_date'] = job.get('issuedate')
job51_item['job_href'] = job.get('job_href')
save_to_json(job51_item)
save_to_csv(job51_item)
mongo.insert_item('job51', job51_item)
logger.success(f'{threading.currentThread().name} save\n {job51_item}')
因为我用的是线程池,所以刚开始以为是线程安全问题。在插入动作前后加锁再开锁,结果没有用。
def insert_item(self, collection: str, item: dict):
mongo_lock.acquire()
self.db[collection].insert_one(item)
mongo_lock.release()
那是什么原因呢?会不会是新增字段_id的问题。
我们知道,在插入文档时,如果没有定义_id字段,pymongo会自动添加,难道是添加_id后改变了原本的字典导致_id重复了?
2. 问题分析
查看pymongo的insert_one()代码
def insert_one(self, document, bypass_document_validation=False, session=None):
...
common.validate_is_document_type("document", document)
if not (isinstance(document, RawBSONDocument) or "_id" in document):
document["_id"] = ObjectId()
...
可以看到,在插入前pymongo判断我们的文档(字典)是否有 _id 字段,如果有则跳过,否则直接修改我们的文档添加一条_id
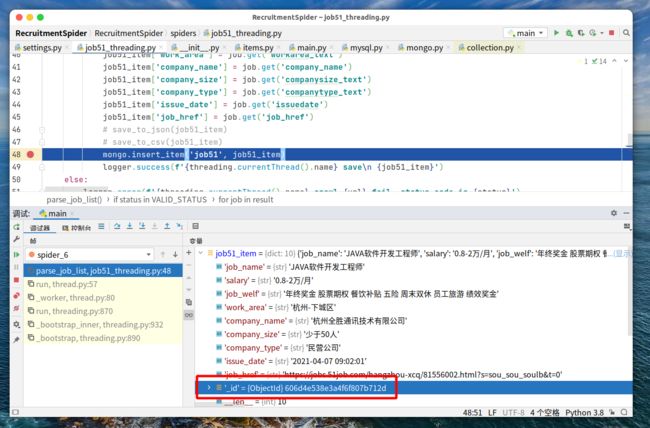
下图是在插入一条文档后,文档(job51_item)的变化,明显多了一条_id字段,那么这次插入就会失败导致程序退出,连报错都没有。
3. 解决问题
明白是_id的问题,那么下面就来解决把吧,主要想到如下几个方法
3.1 删除_id字段
每次插入数据后,把_id删除,或者直接暴力清空文档
mongo.insert_item('job51', job51_item)
job51_item.pop('_id')
# job51_item.clear()
3.2 浅拷贝
为了防止insert_one()方法修改原文档,插入文档的浅拷贝而不是文档
mongo.insert_item('job51', job51_item.copy())
3.3 主动添加_id字段
_id 字段是ObjectId对象,它是一个12字节的唯一标识符,打印出来是一个24位的16进制数字。
insert_one()方法的代码document["_id"] = ObjectId(),ObjectId源于python的bson库(一个第三方库,pymongo的依赖库)中的ObjectId类
BSON,也就是Binary JSON(二进制JSON)的缩写,BSON可以表示许多JSON不支持的数据类型,如:浮点数,长整数,日期和一些自定义类型等
来看一下它是怎么生成_id的,源码注释中写到
Initialize a new ObjectId.
An ObjectId is a 12-byte unique identifier consisting of:
- a 4-byte value representing the seconds since the Unix epoch,
- a 5-byte random value,
- a 3-byte counter, starting with a random value.
By default, ``ObjectId()`` creates a new unique identifier. The
optional parameter `oid` can be an :class:`ObjectId`, or any 12
:class:`bytes` or, in Python 2, any 12-character :class:`str`.
For example, the 12 bytes b'foo-bar-quux' do not follow the ObjectId
specification but they are acceptable input::
>>> ObjectId(b'foo-bar-quux')
ObjectId('666f6f2d6261722d71757578')
`oid` can also be a :class:`unicode` or :class:`str` of 24 hex digits::
>>> ObjectId('0123456789ab0123456789ab')
ObjectId('0123456789ab0123456789ab')
>>>
>>> # A u-prefixed unicode literal:
>>> ObjectId(u'0123456789ab0123456789ab')
ObjectId('0123456789ab0123456789ab')
Raises :class:`~bson.errors.InvalidId` if `oid` is not 12 bytes nor
24 hex digits, or :class:`TypeError` if `oid` is not an accepted type.
意思是你在实例化ObjectId对象时有三种选择
- 什么都不传
- 传入12位二进制数字
- 传入24位16进制数字
注意:
传参错误的话会抛出异常
如果什么都不传,它会根据4字节的时间戳+5字节的随机值+3字节的计数器来生成,具体过程如下:
def __generate(self):
"""Generate a new value for this ObjectId.
"""
# 4 bytes current time
oid = struct.pack(">I", int(time.time()))
# 5 bytes random
oid += ObjectId._random()
# 3 bytes inc
with ObjectId._inc_lock:
oid += struct.pack(">I", ObjectId._inc)[1:4]
ObjectId._inc = (ObjectId._inc + 1) % (_MAX_COUNTER_VALUE + 1)
self.__id = oid
就先了解这么多,总之最简单的就是直接实例化ObjectId
job51_item['_id'] = ObjectId()
mongo.insert_item('job51', job51_item)
4. 补充
在没有给MongoDB加锁的情况下,依然能够正常插入数据,而且效率很高。
原来pymongo是线程安全的,这一点比pymysql好了许多。
pymongo中每个MongoClien实例都有一个线程池,默认最大连接数maxPoolSize=100,默认最小并发数minPoolSize=0,默认保持空闲状态的最大毫秒数maxIdleTimeMS=None等
参考:
- pymongo常见问题回答:https://pymongo.readthedocs.io/en/stable/faq.html
- MongoDB官网JSON和BSON:https://www.mongodb.com/json-and-bson