价值函数的近似表示:假如我们遇到复杂的状态集合呢?甚至很多时候,状态是连续的,那么就算离散化后,集合也很大,此时我们的传统方法,比如Q-Learning,根本无法在内存中维护这么大的一张Q表。
一个可行的建模方法是价值函数的近似表示。方法是我们引入一个状态价值函数v^, 这个函数由参数w描述,并接受状态s作为输入,计算后得到状态s的价值,即我们期望:
类似的
价值函数近似的方法很多,比如最简单的线性表示法,用ϕ(s)表示状态s的特征向量,则此时我们的状态价值函数可以近似表示为:
当然,除了线性表示法,我们还可以用决策树,最近邻,傅里叶变换,神经网络来表达我们的状态价值函数。而最常见,应用最广泛的表示方法是神经网络。因此后面我们的近似表达方法如果没有特别提到,都是指的神经网络的近似表示
对于神经网络,可以使用DNN,CNN或者RNN。没有特别的限制。如果把我们计算价值函数的神经网络看做一个黑盒子,那么整个近似过程可以看做下面这三种情况
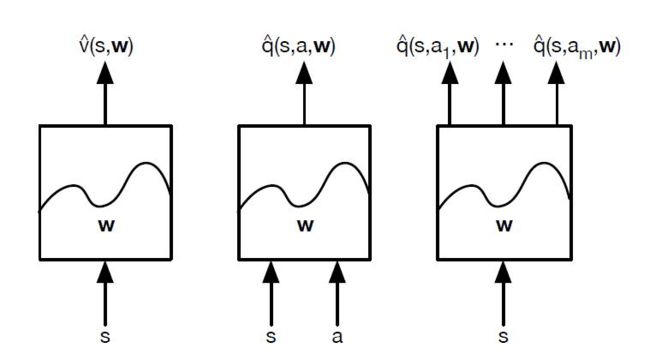
对于Qlearning 采用上面右边的第三幅图的动作价值函数建模思路来做,现在我们叫它Deep Q-Learning。
和Q-Learning不同的地方在于,它的Q值的计算不是直接通过状态值s和动作来计算,而是通过上面讲到的Q网络来计算的。这个Q网络是一个神经网络,我们一般简称Deep Q-Learning为DQN。
DQN的输入是我们的状态s对应的状态向量ϕ(s), 输出是所有动作在该状态下的动作价值函数Q,主要使用的技巧是经验回放(experience replay),即将每次和环境交互得到的奖励与状态更新情况都保存起来,用于后面目标Q值的更新。为什么需要经验回放呢?我们回忆一下Q-Learning,它是有一张Q表来保存所有的Q值的当前结果的,但是DQN是没有的,那么在做动作价值函数更新的时候,就需要其他的方法,这个方法就是经验回放。
通过经验回放得到的目标Q值和通过Q网络计算的Q值肯定是有误差的,那么我们可以通过梯度的反向传播来更新神经网络的参数w,当w收敛后,我们的就得到的近似的Q值计算方法,进而贪婪策略也就求出来了

DQN有个问题,就是它并不一定能保证Q网络的收敛,也就是说,我们不一定可以得到收敛后的Q网络参数。这会导致我们训练出的模型效果很差
进阶: Nature DQN:
注意到DQN(NIPS 2013)里面,我们使用的目标Q值的计算方式:
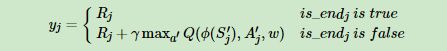
Nature DQN尝试用两个Q网络来减少目标Q值计算和要更新Q网络参数之间的依赖关系。下面我们来看看Nature DQN是怎么做的。
Nature DQN使用了两个Q网络,一个当前Q网络Q用来选择动作,更新模型参数,另一个目标Q网络Q′用于计算目标Q值。目标Q网络的网络参数不需要迭代更新,而是每隔一段时间从当前Q网络Q复制过来,即延时更新,这样可以减少目标Q值和当前的Q值相关性。

DDQN:
在DDQN之前,基本上所有的目标Q值都是通过贪婪法直接得到的 使用max虽然可以快速让Q值向可能的优化目标靠拢,但是很容易过犹不及,导致过度估计(Over Estimation),所谓过度估计就是最终我们得到的算法模型有很大的偏差(bias)。为了解决这个问题, DDQN通过解耦目标Q值动作的选择和目标Q值的计算这两步,来达到消除过度估计的问题。
Nature DQN对于非终止状态,其目标Q值的计算式子是
在DDQN这里,不再是直接在目标Q网络里面找各个动作中最大Q值,而是先在当前Q网络中先找出最大Q值对应的动作,即

然后利用这个选择出来的动作在目标网络里面去计算目标Q值。即
Prioritized Replay DQN:
Nature DQN, DDQN等,他们都是通过经验回放来采样,进而做目标Q值的计算的。在采样的时候,我们是一视同仁,在经验回放池里面的所有的样本都有相同的被采样到的概率。但是注意到在经验回放池里面的不同的样本由于TD误差的不同,对我们反向传播的作用是不一样的。TD误差越大,那么对我们反向传播的作用越大。而TD误差小的样本,由于TD误差小,对反向梯度的计算影响不大。在Q网络中,TD误差就是目标Q网络计算的目标Q值和当前Q网络计算的Q值之间的差距。
这样如果TD误差的绝对值|δ(t)|较大的样本更容易被采样,则我们的算法会比较容易收敛:
Prioritized Replay DQN根据每个样本的TD误差绝对值|δ(t)|,给定该样本的优先级正比于|δ(t)|,将这个优先级的值存入经验回放池。回忆下之前的DQN算法,我们仅仅只保存和环境交互得到的样本状态,动作,奖励等数据,没有优先级这个说法。由于引入了经验回放的优先级,那么Prioritized Replay DQN的经验回放池和之前的其他DQN算法的经验回放池就不一样了。因为这个优先级大小会影响它被采样的概率。在实际使用中,我们通常使用SumTree这样的二叉树结构来做我们的带优先级的经验回放池样本的存储。
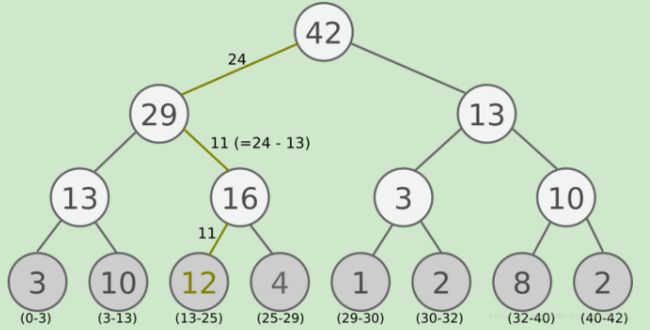
Prioritized Replay DQN和DDQN相比,收敛速度有了很大的提高,避免了一些没有价值的迭代,因此是一个不错的优化点。同时它也可以直接集成DDQN算法,所以是一个比较常用的DQN算法。
Dueling DQN:在Dueling DQN中,我们尝试通过优化神经网络的结构来优化算法,Dueling DQN考虑将Q网络分成两部分,第一部分是仅仅与状态S有关,与具体要采用的动作A无关,这部分我们叫做价值函数部分,第二部分同时与状态状态S和动作A有关,这部分叫做优势函数(Advantage Function)部分,最终我们的价值函数可以重新表示为:

DQN算是深度强化学习的中的主流流派,代表了Value-Based这一大类深度强化学习算法。但是它也有自己的一些问题,就是绝大多数DQN只能处理离散的动作集合,不能处理连续的动作集合。虽然NAF DQN可以解决这个问题,但是方法过于复杂了。而深度强化学习的另一个主流流派Policy-Based而可以较好的解决这个问题