上一篇说了使用Django传统写CRUD的痛点,那么现在就说解决这些痛点的方法
Django REST framework
- 简称为DRF框架或者REST freamwork框架
- 是在Django框架的基础上,进行二次开发的
- 适用于构建符合RESTful风格的API
一、特性
- 提供了强大的
Serializer序列化器,可以高效地进行序列化与反序列化操作 - 提供了丰富的类视图、Mixin扩展类、ViewSet视图集
- 强大的排序,过滤,分页,搜索,限流等功能
- 多种身份权限认证
- 可扩展性,插件丰富
- 提供了直观的Web API界面
二、快速简单使用(基于上一篇的代码上)
- 1.安装
pip install djangorestframework - 2.配置
Django_Project/settings.py的INSTALLED_APPS中,添加rest_framwork - 3.在login文件夹下添加
serializer.py,内容如下:
from rest_framework.serializers import ModelSerializer
from users.models import User
class UserModelSerializer(ModelSerializer):
class Meta:
model = User
fields = '__all__'
- 4.
login/views.py添加下面内容
from login.serializer import UserModelSerializer
from rest_framework.viewsets import ModelViewSet
class UserViewsSet(ModelViewSet):
""" rest_framework 序列化所需"""
queryset = User.objects.all()
serializer_class = UserModelSerializer
- 5.
login/urls.py路由修改成
from django.urls import path
from login import views
from rest_framework.routers import DefaultRouter
app_name = 'login'
urlpatterns = [
path(r'users/', views.Users.as_view()),
path(r'users//', views.UserDetail.as_view()),
]
""" 下面是res_framework所新增 """
# 1.注册路由
router = DefaultRouter()
router.register('user', views.UserViewsSet)
# 2.增加路由
urlpatterns += router.urls
- 5.
Django_Project/urls.py路由修改成:
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('admin/', admin.site.urls),
path('', include('login.urls')),
# rest_framework增加的路由
path('api/', include('rest_framework.urls'))
]
-
6.访问127.0.0.1:8000:
 首页
首页
 点击"http://127.0.0.1:8000/users/跳转的页面"
点击"http://127.0.0.1:8000/users/跳转的页面"
三、序列化优化:单个结果的查询集
修改上一篇的代码_根据id查询User信息
注意!需清空上面步骤二所写的代码
- 1、创建项目序列化器类:需要序列化输出哪些字段,那么就在序列化器中定义这些字段
log/serializer.py
from rest_framework import serializers
class UserSerializer(serializers.Serializer):
"""
创建项目序列化器类:需继承Serializer类或其子类
"""
# 和model类的字段进行对比;注意:max_length的位置需注意,并且有些类型是没有这个字段的
# label:相当于verbose_name
# hole_text:相当于帮助信息
# max_length:最大长度
# !!下面两个是配对的
# allow_null:相当于null(指定字段非必填,否则是必填)
# allow_blank:相当于blank(指定字段非必填,否则是必填)
name = serializers.CharField(label='用户名', max_length=128, help_text='用户名', )
password = serializers.CharField(label='账号密码', max_length=256, help_text='账号密码', )
email = serializers.EmailField(label='账号密码', max_length=128, help_text='账号密码',
allow_null=True, allow_blank=True, default='')
sex = serializers.CharField(label='账号密码', max_length=128, help_text='账号密码',)
c_time = serializers.DateTimeField(label='创建时间', help_text='创建时间',)
- 2、在
view的接口中使用序列化器
步骤:
a.传递查询集给序列化器的instance参数,获得序列化器对象
b.从序列化对象的data获取序列化后的dict类型的数据
例子:修改login/views.py中根据id查询user信息的接口
class UserDetail(View):
def get(self, request, pk):
""" 根据id=pk查询(pk是django默认创建的主键,和id一样) """
# 0.校验传入的id在数据库中是否存在;可封装成一个方法调用
try:
user = User.objects.get(id=pk)
except User.DoesNotExist:
raise Http404
# 1.传递查询集给序列化器,并返回序列化器对象
serializer = UserSerializer(instance=user)
# 2.通过序列化器对象的data属性,获取序列化后的dict
return JsonResponse(serializer.data, status=200)
- 3.访问http://127.0.0.1:8000/users/2/,结果:
 根据id查询用户信息结果
根据id查询用户信息结果
四、序列化优化:多个结果的查询集
- 1.修改上一篇的代码_查询所有User信息
步骤和之前一样,只不过因为需要序列化的内容中包含多个结果的查询集,所以在传递查询集给序列化器处理的时候,需要定义many=True
class Users(View):
def get(self, request): # get请求中,就算用不上request,也需要设置这个参数
"""获取所有的User信息,返回类型为json"""
# 查询全部
user_all = User.objects.all()
# 查询集中有多个结果,需要定义many=True
serializer = UserSerializer(instance=user_all, many=True)
# 返回序列化后的内容
return JsonResponse(serializer.data, safe=False)
- 2.访问访问http://127.0.0.1:8000/users/,结果:
 image.png
image.png
三、反序列化优化:校验前端参数
之前的代码中,因为太繁琐,就省略了对前端传递的参数进行正确性校验。在这里,我们对这部分进行优化
- 调用序列化器对象的
is_valid方法,校验前端参数的正确性
1.校验成功返回True
2.校验失败返回False -
serializer.is_vaild(raise_exception = True)
1.校验失败会抛出异常
2.当调用is_valid()方法后,就可以调用serializer.errors属性,抛出dict格式的错误信息 -
xxx.objects.create(**serializer.validated_data)
1.可以使用serializer.validated_data来获取校验成功后的前端传入的参数
2.可直接用来进行数据库的操作 - 修改创建用户接口
class Users(View):
def post(self, request):
""" 新创建User """
# 1.获取请求中body的值,并解码
user = request.body.decode('utf8')
# 2.反序列化成dict
user_dict = json.loads(user, encoding='utf8')
# 3.序列化前端传来的参数,为了得到序列化对象
serializer = UserSerializer(data=user_dict)
# 4.校验传递的参数是否符合规则
try:
serializer.is_valid(raise_exception=True) # 不符合规则则抛出错误
except Exception as e:
return JsonResponse(serializer.errors) # 返回序列化器原有的dict类型的错误信息
# 5.创建数据,注意这里传的值
user_new = User.objects.create(**serializer.validated_data)
# 6.序列化新创建的user信息
serializer = UserSerializer(instance=user_new)
# 7.响应序列化后的user信息
return JsonResponse(serializer.data, status=201)
-
传入错误的email地址,结果:
 传入错误的email地址
传入错误的email地址 -
传入所有正确信息,结果:
 添加成功
添加成功 -
必填字段为空,结果:
 必填字段为空
必填字段为空 -
传入错误的时间字段,结果:
 传入错误的时间字段
传入错误的时间字段 上面这个错误不合理,我想要c_time为非必填,并且为只读。
这种情况,就可以设置这个字段为只读,不参与反序列化的校验,就使用read_only=True(只对字段进行序列化输出的校验,而不进行反序列化的校验)
然后serializer.py中修改为
c_time = serializers.DateTimeField(label='创建时间', help_text='创建时间', read_only=True)
在此传递空的时间字段,结果:
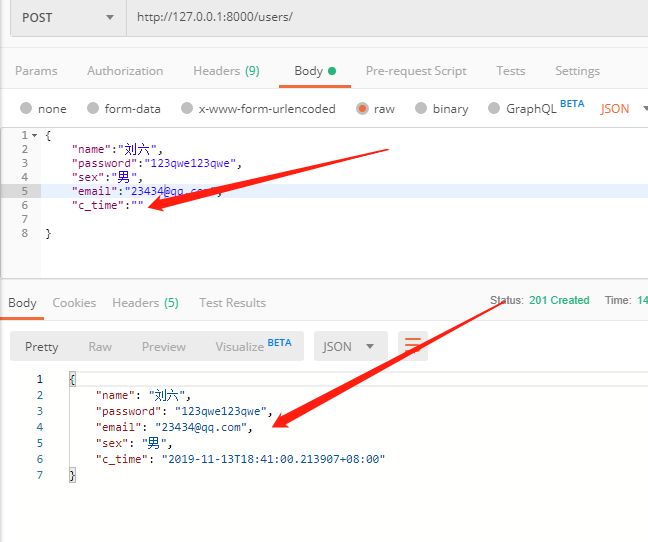
不进行序列化,创建成功
- 自主控制反序列化输入校验、序列化输出校验
默认情况下,如果使用了序列化器和反序列化器,那么两者都会对对应的序列化类中的字段进行反序列化输入、序列化输出的校验(规则和对应序列化类中的字段属性一样)
1.只支持反序列化输入校验,不支持序列化输出校验:write_only=True
2.只支持序列化输出校验,不支持反序列化输入校验:read_only=True
四、常用的选项参数和通用参数
- 选项参数
1.max_length:最大长度
2.min_length:最小长度
3.allow_blank:是否允许为空
4.trim_whitespace:是否截断空白字符
5.max_value:最小值
6.min_value:最大值 - 通用参数
1.read_only:该字段仅用于序列化输出,默认False
2.write_only:该字段仅用于反序列化输入,默认False
3.required:该字段在反序列化时必须输入,默认False
4.default:该字段在反序列化时的默认值
5.allow_null:该字段是否允许传入None,默认Flase
6.validators:该字段所使用的校验器
7.error_messages:包含错误字段和对应错误信息的字段
8.label:用于html展示api页面中,显示的字段名称
9.help_text:用于html展示api页面中,显示的帮助字段内容
五、不在view中进行model的操作,把它拆分在序列化类中
- 新建
1.初始化序列化对象时,传递值给data:serializer = UserSerializer(data=user_dict)
2.那么当在views中调用save方法时,实际上调用的是对应序列化类里的create方法。
例如:
log/serializer.py
from rest_framework import serializers
class UserSerializer(serializers.Serializer):
"""
创建项目序列化器类:需继承Serializer类或其子类
"""
# 和model类的字段进行对比;注意:max_length的位置需注意,并且有些类型是没有这个字段的
# label:相当于verbose_name
# hole_text:相当于帮助信息
# max_length:最大长度
# !!下面两个是配对的
# allow_null:相当于null(指定字段非必填,否则是必填)
# allow_blank:相当于blank(指定字段非必填,否则是必填)
name = serializers.CharField(label='用户名', max_length=128, help_text='用户名', )
password = serializers.CharField(label='账号密码', max_length=256, help_text='账号密码', )
email = serializers.EmailField(label='账号密码', max_length=128, help_text='账号密码',
allow_null=True, allow_blank=True, default='')
sex = serializers.CharField(label='账号密码', max_length=128, help_text='账号密码',)
c_time = serializers.DateTimeField(label='创建时间', help_text='创建时间',)
def create(self, validated_data):
# 如果传递的key不存在于上面的字段中,则报错
return Users.objects.create(**validated_data)
def update(self, instance, validated_data):
instance.name = validated_data['name']
instance.password = validated_data['password ']
instance.email = validated_data['email ']
instance.sex = validated_data['sex ']
instance.save() # 别忘了保存
returen instance # 返回修改后的模型对象
class Users(View):
def post(self, request):
""" 新创建User """
# 1.获取请求中body的值,并解码
user = request.body.decode('utf8')
# 2.反序列化成dict
user_dict = json.loads(user, encoding='utf8')
# 3.序列化前端传来的参数,为了得到序列化对象。注意这里的传参
serializer = UserSerializer(data=user_dict)
# 4.校验传递的参数是否符合规则
try:
serializer.is_valid(raise_exception=True) # 不符合规则则抛出错误
except Exception as e:
return JsonResponse(serializer.errors) # 返回序列化器原有的dict类型的错误信息
# 5.创建数据,这里实际上调用的是对应序列化类中的create方法
serializer.save()
# 6.响应序列化后的user信息
return JsonResponse(serializer.data, status=201)
- 更新
1.初始化序列化对象时,传递值给instance(需要修改的模型类对象)和data(需要修改成的值/dict):serializer = UserSerializer(instacen=user, data=user_dict)
2.那么当在views中调用save方法时,实际上调用的是对应序列化类里的update方法。
class Users(View):
def put(self, request, pk):
""" 更新User """
# 0.获取想要修改的模型类对象
user= User.objects.get(id=pk)
# 1.获取请求中body的值,并解码
user_json = request.body.decode('utf8')
# 2.反序列化成dict
user_dict = json.loads(user, encoding='utf8')
# 3.序列化前端传来的参数,为了得到序列化对象。注意这里的传参
serializer = UserSerializer(instance=user , data=user_dict)
# 4.校验传递的参数是否符合规则
try:
serializer.is_valid(raise_exception=True) # 不符合规则则抛出错误
except Exception as e:
return JsonResponse(serializer.errors) # 返回序列化器原有的dict类型的错误信息
# 5.创建数据,这里实际上调用的是对应序列化类中的update方法
serializer.save()
# 6.响应序列化后的user信息
return JsonResponse(serializer.data, status=201)