逻辑回归是拟合回归曲线的方法,当y是分类变量时,y = f(x)。典型的使用这种模式被预测Ÿ给定一组预测的X。预测因子可以是连续的,分类的或两者的混合。
R中的逻辑回归实现
R可以很容易地拟合逻辑回归模型。要调用的函数是glm(),拟合过程与线性回归中使用的过程没有太大差别。在这篇文章中,我将拟合一个二元逻辑回归模型并解释每一步。
数据集
我们将研究泰坦尼克号数据集。这个数据集有不同版本可以在线免费获得,但我建议使用Kaggle提供的数据集。
目标是预测生存(如果乘客幸存,则为1,否则为0)基于某些诸如服务等级,性别,年龄等特征。
我们将使用分类变量和连续变量。
数据清理过程
在处理真实数据集时,我们需要考虑到一些数据可能丢失的情况,因此我们需要为我们的分析准备数据集。
作为第一步,我们使用该函数加载csv数据read.csv()。
使每个缺失值编码为NA。
training.data.raw < - read.csv('train.csv',header = T,na.strings = c(“”))
现在我们需要检查缺失的值,查看每个变量的唯一值,使用sapply()函数将函数作为参数传递给数据框的每一列。
PassengerId Survived Pclass Name Sex
0 0 0 0 0
Age SibSp Parch Ticket Fare
177 0 0 0 0
Cabin Embarked
687 2
length(unique(x)))
PassengerId Survived Pclass Name Sex
891 2 3 891 2
Age SibSp Parch Ticket Fare
89 7 7 681 248
Cabin Embarked
148 4
对缺失值进行可视化处理可能会有所帮助:可以绘制数据集并显示缺失值:
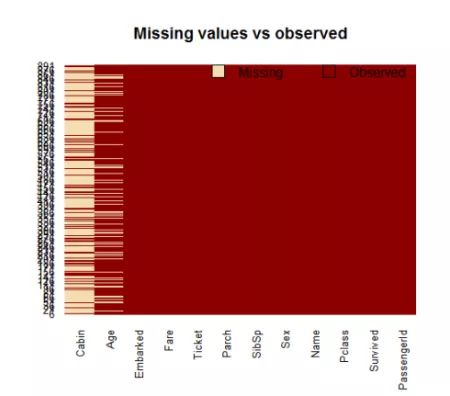
机舱有太多的缺失值,我们不使用它。
使用subset()函数我们对原始数据集进行子集化,只选择相关列。
data < - subset(training.data.raw,select = c(2,3,5,6,7,8,10,12))
现在我们需要解释其他缺失的值。通过在拟合函数内设置参数来拟合广义线性模型时,R可以很容易地处理它们。
有不同的方法可以做到这一点,一种典型的方法是用现有的平均值,中位数或模式代替缺失值。我将使用平均值。
data$ Age [is.na(data $ Age)] < - mean(data$ Age,na.rm = T)
就分类变量而言,使用read.table()或read.csv()默认会将分类变量编码为因子。
为了更好地理解R如何处理分类变量,我们可以使用contrasts()函数。
在进行拟合过程之前,先清洁和格式化数据。这个预处理步骤对于获得模型的良好拟合和更好的预测能力通常是至关重要的。
模型拟合
我们将数据分成两部分:训练和测试集。训练集将用于拟合我们的模型。
model <- glm(Survived ~.,family=binomial(link='logit'),data=train)
通过使用函数,summary()我们获得了我们模型的结果:
Deviance Residuals:
Min 1Q Median 3Q Max
-2.6064 -0.5954 -0.4254 0.6220 2.4165
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 5.137627 0.594998 8.635 < 2e-16 ***
Pclass -1.087156 0.151168 -7.192 6.40e-13 ***
Sexmale -2.756819 0.212026 -13.002 < 2e-16 ***
Age -0.037267 0.008195 -4.547 5.43e-06 ***
SibSp -0.292920 0.114642 -2.555 0.0106 *
Parch -0.116576 0.128127 -0.910 0.3629
Fare 0.001528 0.002353 0.649 0.5160
EmbarkedQ -0.002656 0.400882 -0.007 0.9947
EmbarkedS -0.318786 0.252960 -1.260 0.2076
---
Signif. codes: 0 ‘***' 0.001 ‘**' 0.01 ‘*' 0.05 ‘.' 0.1 ‘ ' 1
解释我们的逻辑回归模型的结果
现在我们可以分析拟合并解释模型告诉我们什么。
首先,我们可以看到SibSp,Fare和Embarked没有统计意义。至于统计上显着的变量,性别具有最低的p值,这表明乘客的性别与存活的可能性有很强的关联。
预测因子的负系数表明所有其他变量相同,男性乘客不太可能存活下来。
由于男性是虚拟变量,因此男性将对数概率降低2.75,而单位年龄增加则将对数概率降低0.037。
现在我们可以运行anova()模型上的函数来分析偏差表
Analysis of Deviance Table
Model: binomial, link: logit
Response: Survived
Terms added sequentially (first to last)
Df Deviance Resid. Df Resid. Dev Pr(>Chi)
NULL 799 1065.39
Pclass 1 83.607 798 981.79 < 2.2e-16 ***
Sex 1 240.014 797 741.77 < 2.2e-16 ***
Age 1 17.495 796 724.28 2.881e-05 ***
SibSp 1 10.842 795 713.43 0.000992 ***
Parch 1 0.863 794 712.57 0.352873
Fare 1 0.994 793 711.58 0.318717
Embarked 2 2.187 791 709.39 0.334990
零偏差和剩余偏差之间的差异越大越好。通过分析表格,我们可以看到每次添加一个变量时出现偏差的情况。
同样,增加Pclass,Sex and Age可以显着减少残余偏差。
这里的大p值表示没有变量的模型或多或少地解释了相同的变化量。最终你想看到的是一个显着的下降和偏差AIC。
评估模型的预测能力
在上面的步骤,我们简要评价模型的拟合。通过设置参数type='response',R将以P(y = 1 | X)的形式输出概率。我们的决策边界将是0.5。如果P(y = 1 | X)> 0.5,则y = 1,否则y = 0。请注意,对于某些应用场景,不同的阈值可能是更好的选择。
fitting.results < - ifelse(fitted.results> 0.5,1,0) misClasificError < - mean(fitted.results!= test $ Survived
测试集上的0.84精度是相当不错的结果。但是,如果您希望得到更精确的分数,最好运行交叉验证,如k折交叉验证验证。
作为最后一步,我们将绘制ROC曲线并计算二元分类器典型性能测量的AUC(曲线下面积)。
ROC是通过在各种阈值设置下将真阳性率(TPR)与假阳性率(FPR)作图而产生的曲线,而AUC是ROC曲线下的面积。作为一个经验法则,具有良好预测能力的模型应该接近于1。

以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。如有错误或未考虑完全的地方,望不吝赐教。