Semantic Segmentation---FCN论文复现全过程
经过一段时间的论文阅读开始尝试复现一些经典论文,最经典的莫过于FCN网络。一块1080ti经过27h训练,最终训练结果如下:

测试集上的表现(image,groundtruth,out)


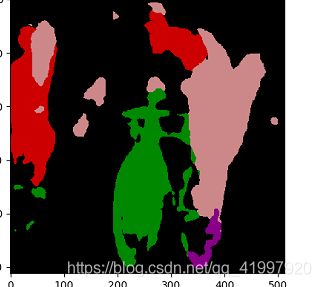
可以看出尽管各项评价指标相对与论文来说相差无几,但可视化出来并没有论文中表现的那么好,且还出现类别预测错误的现象。具体原因我还未知,尝试用这个框架训SegNet以后看可视化结果怎么样。
论文实现:
Readme
Network implemented:
- FCN8s
Requirements:
- pytorch =1.1.0
- torchvision ==0.2.2
- scipy
- tqdm
- tensorboardX
值得注意的是torch正是开始支持tensorborad,但早上尝试了以下导入SummaryWriter出现报错,可能是其他包兼容性导致。保险起见还是使用tensorboardX。
Data:
- Pascal VOC2012(可以尝试训练CamVid)
FCN的config文件,其中定义了一些全局参数。
model:
arch: fcn8s
data:
dataset: pascal
train_split: train_aug
val_split: val
img_rows: 'same'
img_cols: 'same'
path: E:/paper_recurrence/pytorch-semseg-leige/datasets/VOCdevkit/VOC2012/
sbd_path: E:/paper_recurrence/pytorch-semseg-leige/datasets/benchmark_RELEASE/
training:
train_iters: 300000
batch_size: 1
val_interval: 1000
n_workers: 16
print_interval: 50
optimizer:
name: 'sgd'
lr: 1.0e-10
weight_decay: 0.0005
momentum: 0.99
loss:
name: 'cross_entropy'
size_average: False
lr_schedule:
resume: fcn8s_pascal_best_model.pkl
以下代码来源于Github
先看看网络结构,以FCN8S为例:
# FCN 8s
class fcn8s(nn.Module):
def __init__(self, n_classes=21, learned_billinear=True):
super(fcn8s, self).__init__()
self.learned_billinear = learned_billinear
self.n_classes = n_classes
self.loss = functools.partial(cross_entropy2d, size_average=False)
self.conv_block1 = nn.Sequential(
nn.Conv2d(3, 64, 3, padding=100),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, 3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, stride=2, ceil_mode=True),
)
self.conv_block2 = nn.Sequential(
nn.Conv2d(64, 128, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(128, 128, 3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, stride=2, ceil_mode=True),
)
self.conv_block3 = nn.Sequential(
nn.Conv2d(128, 256, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, 3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, stride=2, ceil_mode=True),
)
self.conv_block4 = nn.Sequential(
nn.Conv2d(256, 512, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, 3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, stride=2, ceil_mode=True),
)
self.conv_block5 = nn.Sequential(
nn.Conv2d(512, 512, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, 3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, stride=2, ceil_mode=True),
)
self.classifier = nn.Sequential(
nn.Conv2d(512, 4096, 7),
nn.ReLU(inplace=True),
nn.Dropout2d(),
nn.Conv2d(4096, 4096, 1),
nn.ReLU(inplace=True),
nn.Dropout2d(),
nn.Conv2d(4096, self.n_classes, 1),
)
self.score_pool4 = nn.Conv2d(512, self.n_classes, 1)
self.score_pool3 = nn.Conv2d(256, self.n_classes, 1)
if self.learned_billinear:
self.upscore2 = nn.ConvTranspose2d(
self.n_classes, self.n_classes, 4, stride=2, bias=False
)
self.upscore4 = nn.ConvTranspose2d(
self.n_classes, self.n_classes, 4, stride=2, bias=False
)
self.upscore8 = nn.ConvTranspose2d(
self.n_classes, self.n_classes, 16, stride=8, bias=False
)
for m in self.modules():
if isinstance(m, nn.ConvTranspose2d):
m.weight.data.copy_(
get_upsampling_weight(m.in_channels, m.out_channels, m.kernel_size[0])
)
def forward(self, x):
conv1 = self.conv_block1(x)
conv2 = self.conv_block2(conv1)
conv3 = self.conv_block3(conv2)
conv4 = self.conv_block4(conv3)
conv5 = self.conv_block5(conv4)
score = self.classifier(conv5)
if self.learned_billinear:
upscore2 = self.upscore2(score)
score_pool4c = self.score_pool4(conv4)[
:, :, 5 : 5 + upscore2.size()[2], 5 : 5 + upscore2.size()[3]
]
upscore_pool4 = self.upscore4(upscore2 + score_pool4c)
score_pool3c = self.score_pool3(conv3)[
:, :, 9 : 9 + upscore_pool4.size()[2], 9 : 9 + upscore_pool4.size()[3]
]
out = self.upscore8(score_pool3c + upscore_pool4)[
:, :, 31 : 31 + x.size()[2], 31 : 31 + x.size()[3]
]
return out.contiguous()
else:
score_pool4 = self.score_pool4(conv4)
score_pool3 = self.score_pool3(conv3)
score = F.upsample(score, score_pool4.size()[2:])
score += score_pool4
score = F.upsample(score, score_pool3.size()[2:])
score += score_pool3
out = F.upsample(score, x.size()[2:])
return out
def init_vgg16_params(self, vgg16, copy_fc8=True):
blocks = [
self.conv_block1,
self.conv_block2,
self.conv_block3,
self.conv_block4,
self.conv_block5,
]
ranges = [[0, 4], [5, 9], [10, 16], [17, 23], [24, 29]]
features = list(vgg16.features.children())
for idx, conv_block in enumerate(blocks):
for l1, l2 in zip(features[ranges[idx][0] : ranges[idx][1]], conv_block):
if isinstance(l1, nn.Conv2d) and isinstance(l2, nn.Conv2d):
assert l1.weight.size() == l2.weight.size()
assert l1.bias.size() == l2.bias.size()
l2.weight.data = l1.weight.data
l2.bias.data = l1.bias.data
for i1, i2 in zip([0, 3], [0, 3]):
l1 = vgg16.classifier[i1]
l2 = self.classifier[i2]
l2.weight.data = l1.weight.data.view(l2.weight.size())
l2.bias.data = l1.bias.data.view(l2.bias.size())
n_class = self.classifier[6].weight.size()[0]
if copy_fc8:
l1 = vgg16.classifier[6]
l2 = self.classifier[6]
l2.weight.data = l1.weight.data[:n_class, :].view(l2.weight.size())
l2.bias.data = l1.bias.data[:n_class]
网络结构主要以VGG16作为预训练网络。
下面主要对train.py进行讲解,先导入相应的包,其中ptsemseg文件GitHub下载源码即可:
import os
import yaml
import time
import shutil
import torch
import random
import argparse
import numpy as np
from torch.utils import data
from tqdm import tqdm
from ptsemseg.models import get_model
from ptsemseg.loss import get_loss_function
from ptsemseg.loader import get_loader
from ptsemseg.utils import get_logger
from ptsemseg.metrics import runningScore, averageMeter
from ptsemseg.augmentations import get_composed_augmentations
from ptsemseg.schedulers import get_scheduler
from ptsemseg.optimizers import get_optimizer
from tensorboardX import SummaryWriter训练函数
def train(cfg, writer, logger):
# 设置随机种子,使得结果固定
torch.manual_seed(cfg.get("seed", 1337))
torch.cuda.manual_seed(cfg.get("seed", 1337))
np.random.seed(cfg.get("seed", 1337))
random.seed(cfg.get("seed", 1337))
# 设置运行方案,默认GPU运行
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 设置数据增强
augmentations = cfg["training"].get("augmentations", None)
data_aug = get_composed_augmentations(augmentations)
# 加载数据集
#相应的函数在GitHub源码中直接运行
data_loader = get_loader(cfg["data"]["dataset"])
data_path = cfg["data"]["path"]
t_loader = data_loader(
data_path,
is_transform=True,
split=cfg["data"]["train_split"],
img_size=(cfg["data"]["img_rows"], cfg["data"]["img_cols"]),
augmentations=data_aug,
)
v_loader = data_loader(
data_path,
is_transform=True,
split=cfg["data"]["val_split"],
img_size=(cfg["data"]["img_rows"], cfg["data"]["img_cols"]),
)
n_classes = t_loader.n_classes #设置类别,根据加载的数据集的不同,类别数不同
trainloader = data.DataLoader(
t_loader,
batch_size=cfg["training"]["batch_size"],
num_workers=cfg["training"]["n_workers"],
shuffle=True,
)
valloader = data.DataLoader(
v_loader, batch_size=cfg["training"]["batch_size"], num_workers=cfg["training"]["n_workers"]
)
# 设置IOU框
running_metrics_val = runningScore(n_classes)
# 导出模型
model = get_model(cfg["model"], n_classes).to(device)
model = torch.nn.DataParallel(model, device_ids=range(torch.cuda.device_count()))
# S设置优化函数,学习率,损失函数(具体参考config文件)
optimizer_cls = get_optimizer(cfg)
optimizer_params = {k: v for k, v in cfg["training"]["optimizer"].items() if k != "name"}
optimizer = optimizer_cls(model.parameters(), **optimizer_params)
logger.info("Using optimizer {}".format(optimizer))
scheduler = get_scheduler(optimizer, cfg["training"]["lr_schedule"])
loss_fn = get_loss_function(cfg)
logger.info("Using loss {}".format(loss_fn))
start_iter = 0 #初始化
if cfg["training"]["resume"] is not None:
if os.path.isfile(cfg["training"]["resume"]):
#将训练以后的模型保存,在config文件中设置,是否保存,参数resume
logger.info(
"Loading model and optimizer from checkpoint '{}'".format(cfg["training"]["resume"])
)
checkpoint = torch.load(cfg["training"]["resume"])
model.load_state_dict(checkpoint["model_state"])
optimizer.load_state_dict(checkpoint["optimizer_state"])
scheduler.load_state_dict(checkpoint["scheduler_state"])
start_iter = checkpoint["epoch"]
logger.info(
"Loaded checkpoint '{}' (iter {})".format(
cfg["training"]["resume"], checkpoint["epoch"]
)
)
else:
logger.info("No checkpoint found at '{}'".format(cfg["training"]["resume"]))
val_loss_meter = averageMeter()
time_meter = averageMeter()
best_iou = -100.0
i = start_iter
flag = True
while i <= cfg["training"]["train_iters"] and flag:
for (images, labels) in trainloader:
i += 1
start_ts = time.time()
scheduler.step()
model.train()
images = images.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = loss_fn(input=outputs, target=labels)
loss.backward()
optimizer.step()
time_meter.update(time.time() - start_ts)
if (i + 1) % cfg["training"]["print_interval"] == 0:
fmt_str = "Iter [{:d}/{:d}] Loss: {:.4f} Time/Image: {:.4f}"
print_str = fmt_str.format(
i + 1,
cfg["training"]["train_iters"],
loss.item(),
time_meter.avg / cfg["training"]["batch_size"],
)
print(print_str)
logger.info(print_str)
writer.add_scalar("loss/train_loss", loss.item(), i + 1)
time_meter.reset()
if (i + 1) % cfg["training"]["val_interval"] == 0 or (i + 1) == cfg["training"][
"train_iters"
]:
model.eval()
with torch.no_grad():
for i_val, (images_val, labels_val) in tqdm(enumerate(valloader)):
images_val = images_val.to(device)
labels_val = labels_val.to(device)
outputs = model(images_val)
val_loss = loss_fn(input=outputs, target=labels_val)
pred = outputs.data.max(1)[1].cpu().numpy()
gt = labels_val.data.cpu().numpy()
running_metrics_val.update(gt, pred)
val_loss_meter.update(val_loss.item())
writer.add_scalar("loss/val_loss", val_loss_meter.avg, i + 1)
logger.info("Iter %d Loss: %.4f" % (i + 1, val_loss_meter.avg))
score, class_iou = running_metrics_val.get_scores()
for k, v in score.items():
print(k, v)
logger.info("{}: {}".format(k, v))
writer.add_scalar("val_metrics/{}".format(k), v, i + 1)
for k, v in class_iou.items():
logger.info("{}: {}".format(k, v))
writer.add_scalar("val_metrics/cls_{}".format(k), v, i + 1)
val_loss_meter.reset()
running_metrics_val.reset()
if score["Mean IoU : \t"] >= best_iou:
best_iou = score["Mean IoU : \t"]
state = {
"epoch": i + 1,
"model_state": model.state_dict(),
"optimizer_state": optimizer.state_dict(),
"scheduler_state": scheduler.state_dict(),
"best_iou": best_iou,
}
save_path = os.path.join(
writer.file_writer.get_logdir(),
"{}_{}_best_model.pkl".format(cfg["model"]["arch"], cfg["data"]["dataset"]),
)
torch.save(state, save_path)
if (i + 1) == cfg["training"]["train_iters"]:
flag = False
break
代码比较简洁,有不理解的函数直接调到函数定义的地方看看。
总结:
在复现代码的过程中遇到很多bug,如果一个人写整个经典网络的代码,可以看到代码量太大。对于初学者我们尝试这去下载别人的代码,然后通过debug过程中提高代码能力,理解网络结构。在调试过程中一般bug最多的地方在数据集读取还有图像增强过程中,因为涉及到输入的维度,常常是我们遇到错误。
常见的警告或者错误:
1.
out of memory at /opt/conda/conda-bld/pytorch_1524590031827/work/aten/src/THC/generic/THCStorage.cu:58首先要理解不是Bug,显卡显存不足引起
解决方法:1、换小的batch;2、图片尺寸换成小的;3、图片格式从float换成int;4、换大显存、大显卡;5、优化程序,每一步都释放掉多余的占用显存的变量;
2.
invalid argument 0: Sizes of tensors must match except in dimension 1. Got 14 and 13 in dimension 0 at
/home/prototype/Downloads/pytorch/aten/src/THC/generic/THCTensorMath.cu:83说明的是:报错中的13,14也可以是其他大于4的数,因为一般大于4是一种情况引起,报3,4是另外一种情况引起,现在主要针对报错情况进行解决:
这种错误有两种可能:
- 你输入的图像数据的维度不完全是一样的,比如是训练的数据有100组,其中99组是256*256,但有一组是384*384,这样会导致Pytorch的检查程序报错
- 另外一个则是比较隐晦的batchsize的问题,Pytorch中检查你训练维度正确是按照每个batchsize的维度来检查的,比如你有1000组数据(假设每组数据为三通道256px*256px的图像),batchsize为4,那么每次训练则提取(4,3,256,256)维度的张量来训练,刚好250个epoch解决(250*4=1000)。但是如果你有999组数据,你继续使用batchsize为4的话,这样999和4并不能整除,你在训练前249组时的张量维度都为(4,3,256,256)但是最后一个批次的维度为(3,3,256,256),Pytorch检查到(4,3,256,256) != (3,3,256,256),维度不匹配,自然就会报错了,这可以称为一个小bug。
那么怎么解决,针对第一种,很简单,整理一下你的数据集保证每个图像的维度和通道数都一直即可。第二种来说,挑选一个可以被数据集个数整除的batchsize或者直接把batchsize设置为1即可。但我在使用Unet网络训练VOC2012数据集时报错,这两种情况都还没有解决,解决后补!
其他的错误一般都是路径,还有一些基本的语句引起,根据报错定位一点点debug,print大法好!!!
补充一下:
“代码中 score_pool4c = self.score_pool4(conv4)[ :, :, 5 : 5 + upscore2.size()[2], 5 : 5 + upscore2.size()[3]]” 为什么要做这一步呢,那些5,9,32都是什么?
有人问代码中的出现的5,9,31的解释。
使用ConvTranspose2d来实现上采样,
- 直接上一步卷积上做 2 倍上采样,
- 将Pool4的结果裁剪到A的大小并和其相加得到B
- 将B上采样两倍得到C, 将Pool3裁剪到C的大小并和C相加得到D,
- 将D上采样 8 倍然后裁剪到原图大小
VGG16有5个卷积池化阶段,我们这里取第三第四第五阶段的结果分别为Pool3,Pool4,Pool5 假设图像的高h(宽类似),因为我们Padding了100,相当于输入大小是h+198(padding=1卷积才不会改变大小),每个阶段进行一次下采样,缩小了1/2, 所以

我们上面把VGG16中的全连接层6,7变成了卷积层,其中conv6以7x7的核进行卷积,conv7只改变了通道数宽高和conv6一样。由卷积公式我们知道:
接下来是的上采样过程:
-
卷积上采样2倍得到:
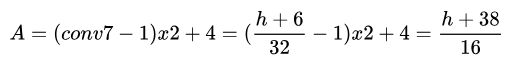

后面的设置同理!
简单的来说:池化时候,每个阶段进行一次下采样,特征图缩小了, 但是卷积进行直接在2倍两倍上采样,得到的A需要与池化后的特征图结合。 将 pool4 的结果裁剪到A的大小并和其A相加得到B,后来同理。所以pool4-A=(h+198)/10 - (h+38)/10 =10,居中裁剪所以设置为5
这里的代码好像更简单一些,上面的代码是GitHub下载的,可以参考下面这段代码好理解一些。
class FCN8(Module):
def __init__(self,n_class):
super(FCN8,self).__init__()
self.up_sample2=ConvTranspose2d(n_class,n_class,4,2)
self.up_sample8 = ConvTranspose2d(n_class,n_class,16,8)
self.score_pool4 = Conv2d(512,n_class,1)
self.score_pool3 = Conv2d(256,n_class,1)
def forward(self,X):
data = X
print(data.size())
pool3,pool4,pool5 = Vgg16()(X)
X = Conv2d(512,4096,7)(pool5)
X = ReLU()(X)
X = Conv2d(4096,4096,1)(X)
conv7 = Conv2d(4096, 21, 1)(X)
A = self.up_sample2(conv7)
print(A.size())
print(pool4.size())
pool4_score = self.score_pool4(pool4)
print(pool4_score.size())
pool4_crop = pool4_score[:,:,5:5+A.size()[2],5:5+A.size()[3]].contiguous()
print(pool4_crop.size())
sumApool4 = pool4_crop + A
B = self.up_sample2(sumApool4)
pool3_score = self.score_pool3(pool3)
pool3_crop = pool3_score[:,:,9:9+B.size()[2],9:9+B.size()[3]].contiguous()
sumBpool3 = pool3_crop + B
C = self.up_sample8(sumBpool3)
C = C[:,:,31:31+data.size()[2],31:31+data.size()[3]].contiguous()
return C