何为Lucene.Net?
Lucene.net是Lucene的.net移植版本,是一个开源的全文检索引擎开发包,即它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎。开发人员可以基于Lucene.net实现全文检索的功能。
Lucene.net是Apache软件基金会赞助的开源项目,基于Apache License协议。
Lucene.net并不是一个爬行搜索引擎,也不会自动地索引内容。我们得先将要索引的文档中的文本抽取出来,然后再将其加到Lucene.net索引中。标准的步骤是先初始化一个Analyzer、打开一个IndexWriter、然后再将文档一个接一个地加进去。一旦完成这些步骤,索引就可以在关闭前得到优化,同时所做的改变也会生效。这个过程可能比开发者习惯的方式更加手工化一些,但却在数据的索引上给予你更多的灵活性,而且其效率也很高。
如何在C#中实现站内搜索?
1.添加对以下dll的引用:
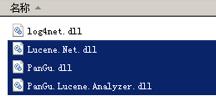
2.添加词库文件:包含Dict目录下所有文件
3.如何创建索引:
///
/// 创建索引,将数据库中的数据取出来给Lucene索引库
///
protected void CreateContent()
{
string indexPath = @”C:/lucenedir”;//注意和磁盘上文件夹的大小写一致,否则会报错。将创建的分词内容放在该目录下。
FSDirectory directory = FSDirectory.Open(new DirectoryInfo(indexPath), new NativeFSLockFactory());//指定索引文件(打开索引目录) FS指的是就是FileSystem
bool isUpdate = IndexReader.IndexExists(directory);//IndexReader:对索引进行读取的类。该语句的作用:判断索引库文件夹是否存在以及索引特征文件是否存在。
if (isUpdate)
{
//同时只能有一段代码对索引库进行写操作。当使用IndexWriter打开directory时会自动对索引库文件上锁。
//如果索引目录被锁定(比如索引过程中程序异常退出),则首先解锁(提示一下:如果我现在正在写着已经加锁了,但是还没有写完,这时候又来一个请求,那么不就解锁了吗?这个问题后面会解决)
if (IndexWriter.IsLocked(directory))
{
IndexWriter.Unlock(directory);
}
}
IndexWriter writer = new IndexWriter(directory, new PanGuAnalyzer(), !isUpdate, Lucene.Net.Index.IndexWriter.MaxFieldLength.UNLIMITED);//向索引库中写索引。这时在这里加锁。
BLL.BookManager bll = new BLL.BookManager();
List list = bll.GetModelList(“”);
foreach (Model.Book model in list)
{
writer.DeleteDocuments(new Term(“id”,model.Id.ToString()));//删除索引库中原有的项.
Document document = new Document();//表示一篇文档。
//Field.Store.YES:表示是否存储原值。只有当Field.Store.YES在后面才能用doc.Get(“number”)取出值来.Field.Index. NOT_ANALYZED:不进行分词保存
document.Add(new Field(“id”, model.Id.ToString(), Field.Store.YES, Field.Index.NOT_ANALYZED));
//Field.Index. ANALYZED:进行分词保存:也就是要进行全文的字段要设置分词 保存(因为要进行模糊查询)
//Lucene.Net.Documents.Field.TermVector.WITH_POSITIONS_OFFSETS:不仅保存分词还保存分词的距离。
document.Add(new Field(“title”, model.Title, Field.Store.YES, Field.Index.ANALYZED, Lucene.Net.Documents.Field.TermVector.WITH_POSITIONS_OFFSETS));
document.Add(new Field(“msg”, model.ContentDescription, Field.Store.YES, Field.Index.ANALYZED, Lucene.Net.Documents.Field.TermVector.WITH_POSITIONS_OFFSETS));
writer.AddDocument(document);
}
writer.Close();//会自动解锁。
directory.Close();//不要忘了Close,否则索引结果搜不到
}
4.添加分词方法:
///
/// 对用户输入的搜索的条件进行分词
///
///
///
public static string[] SplitWord(string str)
{
List list = new List();
Analyzer analyzer = new PanGuAnalyzer();//指定盘古分词
TokenStream tokenStream = analyzer.TokenStream(“”, new StringReader(str));//
Lucene.Net.Analysis.Token token = null;
while ((token = tokenStream.Next()) != null)
{
list.Add(token.TermText());
}
return list.ToArray();
}
4.搜索代码实现:
//搜索
protected void SearchContent()
{
string indexPath = @”C:/lucenedir”;//最好将该项放在配置文件中。
string kw = Request["txtContent"];
kw = kw.ToLower();
FSDirectory directory = FSDirectory.Open(new DirectoryInfo(indexPath), new NoLockFactory());
IndexReader reader = IndexReader.Open(directory, true);
IndexSearcher searcher = new IndexSearcher(reader);
//搜索条件
PhraseQuery query = new PhraseQuery();
foreach (string word in Common.WebCommon.SplitWord(kw))//将用户输入的搜索内容进行了盘古分词、
{
query.Add(new Term(“msg”, word));
}
query.SetSlop(100);//多个查询条件的词之间的最大距离.在文章中相隔太远 也就无意义.(例如 “大学生”这个查询条件和”简历”这个查询条件之间如果间隔的词太多也就没有意义了。)
//TopScoreDocCollector是盛放查询结果的容器
TopScoreDocCollector collector = TopScoreDocCollector.create(1000, true);
searcher.Search(query, null, collector);//根据query查询条件进行查询,查询结果放入collector容器
ScoreDoc[] docs = collector.TopDocs(0, collector.GetTotalHits()).scoreDocs;//得到所有查询结果中的文档,GetTotalHits():表示总条数 TopDocs(300, 20);//表示得到300(从300开始),到320(结束)的文档内容. //可以用来实现分页功能
List list = new List();
for (int i = 0; i < docs.Length; i++)
{
//
//搜索ScoreDoc[]只能获得文档的id,这样不会把查询结果的Document一次性加载到内存中。降低了内存压力,需要获得文档的详细内容的时候通过searcher.Doc来根据文档id来获得文档的详细内容对象Document.
int docId = docs[i].doc;//得到查询结果文档的id(Lucene内部分配的id)
Document doc = searcher.Doc(docId);//找到文档id对应的文档详细信息
SearchResult result = new SearchResult();
result.Msg =Common.WebCommon.Highlight(kw,doc.Get(“msg”));
result.Title = doc.Get(“title”);
result.Url = “/BookDeatail.apsx?id=” + doc.Get(“id”);
list.Add(result);
}
this.SearchRepeater.DataSource = list;
this.SearchRepeater.DataBind();
}
5.高亮显示关键词:
///
/// 对搜索的关键词高亮显示
///
///
///
///
public static string Highlight(string keyword, string content)
{
//创建HTMLFormatter,参数为高亮单词的前后缀
PanGu.HighLight.SimpleHTMLFormatter simpleHTMLFormatter =
new PanGu.HighLight.SimpleHTMLFormatter(“”,
“”);
//创建 Highlighter ,输入HTMLFormatter 和 盘古分词对象Semgent
PanGu.HighLight.Highlighter highlighter =
new PanGu.HighLight.Highlighter(simpleHTMLFormatter,
new Segment());
//设置每个摘要段的字符数
highlighter.FragmentSize =100;
//获取最匹配的摘要段
return highlighter.GetBestFragment(keyword, content);
}