前言
今天我们会定义可递归的枚举,向大家展示,如何利用枚举来定义一些高性能且非可变的数据结构(纯函数式数据结构)
二叉树
- 二叉树的每个结点至多只有二棵子树,二叉树的子树有左右之分,通常被称为左子树和右子树,次序不能颠倒。
- 二叉树通常被用于实现二叉查找树和二叉堆。
- 二叉树是递归定义的,在逻辑上二叉树有五种基本形态。

二叉树的相关术语(只列举了后面会用到的部分)
- 树的节点:包含一个数据元素以及若干指向子树的分支
- 结点层:根结点的层定义为1,根的孩子为第二层结点,依次类推
- 结点的度:结点子树的个数
- 树的深度:树中最大的节点层
- 叶子结点:也叫终端结点,是度为0的结点
二叉树的特殊形态
- 完全二叉树:若设二叉树的高度为h,除第h层之外,其他各层的结点数都达到最大数,第h层有叶子结点,并且叶子结点都是从左到右依次排布。
-
满二叉树:除了叶子结点外每一个结点都有左右子叶且叶子结点都处在最底层的二叉树。
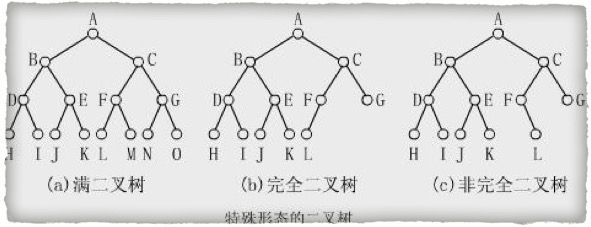 图2.png
图2.png - 二叉搜索树:他或者是一颗空树,或者是具有下列性质的二叉树:若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值,若它的右子树上所有结点的值均大于它的根结点的值;它的左右子树也分别二叉搜索树。

二叉树的遍历
先定义一个二叉树的类
class TreeNode {
var value: Int?
var left:TreeNode?
var right:TreeNode?
var flag: Bool = false//标记是否遍历了该结点的右结点
init(val:Int){
self.value = val
self.left = nil
self.right = nil
}
}
先序遍历(根左右)
/**
用栈实现前序遍历
- parameter root: 二叉树
- returns: 前序遍历的结果
*/
func preOrderTraversal(root:TreeNode?) -> [Int]{
var res = [Int]()
var stack = [TreeNode]()
var node = root
while !stack.isEmpty || node != nil {
if (node != nil) {
res.append((node?.value)!)
stack.append(node!)
node = node?.left
}else{
node = stack.removeLast().right
}
}
return res
}
中序遍历 (左根右)
/**
用栈实现中序遍历
- parameter root: 二叉树
- returns: 中序遍历的结果
*/
func inOrderTraversal(root:TreeNode?) -> [Int] {
var res = [Int]()
var stack = [TreeNode]()
var node = root
while !stack.isEmpty || node != nil{
while node != nil {
stack.append(node!)
node = node?.left
}
node = stack.removeLast()
res.append((node?.value)!)
node = node?.right
}
return res
}
后序遍历 (左右根)
/**
用栈实现后序遍历
- parameter root: 二叉树
- returns: 遍历的结果
*/
func postOrderTraversal(root: TreeNode?) -> [Int]{
var res = [Int]()
var stack = [TreeNode]()
var node = root
if !stack.isEmpty || node != nil {
while node != nil {
stack.append(node!)
stack[stack.endIndex - 1].flag = false
node = node?.left
}
while !stack.isEmpty {
node = stack[stack.endIndex - 1]
while ((node?.right != nil) && (node?.flag == false)) {
stack[stack.endIndex - 1].flag = true
node = node?.right
while (node != nil) {
stack.append(node!)
stack[stack.endIndex - 1].flag = false
node = node?.left
}
}
node = stack[stack.endIndex - 1]
res.append((node?.value)!)
print(res)
stack.removeLast()
}
}
return res
}
测试
let tree = TreeNode.init(val: 2)
tree.left = TreeNode.init(val: 3)
tree.right = TreeNode.init(val: 4)
let tree1 = TreeNode.init(val: 1)
tree1.left = tree
tree1.right = TreeNode.init(val: 5)
preOrderTraversal(tree1)//[1,2,3,4,5]
inOrderTraversal(tree1)//[3,2,4,1,5]
postOrderTraversal(tree1)//[3,4,2,5,1]
进入正题
在swift发布的时候,并木有类似于Objective-C中NSSet的库来处理无序集合(Set),今天的目标是用递归式枚举来定义高效的数据结构。
在我们的迷你库中会实现以下四种操作:
- empty:返回一个空的无序集合
- isEmpty:检查一个无序集合是否为空
- contains:检查无序集合中是否包含某个元素
- insert:向无序集合中插入一个元素
对于上面的功能我们可以用数组来实现:
//使用数组来表示无序集合
func empty() -> [Element] {
return []
}
func isEmpty(set: [Element]) -> Bool {
return set.isEmpty
}
func contains(x: Element, _ set: [Element]) -> Bool {
return set.contains(x)
}
func insert(x: Element, _ set:[Element]) -> [Element] {
return contains(x, set) ? set : [x] + set
}
优点:实现简单
缺点:大部分的操作的性能消耗与无序集合的大小是线性相关的
解决方案一:确保数组是经过排序的,然后使用二分查找来定位特定元素
解决方案二:二叉搜索树(他或者是一颗空树,或者是具有下列性质的二叉树:若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值,若它的右子树上所有结点的值均大于它的根结点的值;它的左右子树也分别二叉搜索树(递归)。)
由于今天的目标是用递归式枚举来定义高效的数据结构,所以说我们采取解决方案二来解决这个问题。首先先定义一个二叉搜索树的枚举:
//indirect:2.0新增的一个类型。允许将枚举中一个case的关联值再次定义为枚举
indirect enum BinarySearchTree {
case Leaf//空树
case Node(BinarySearchTree, Element, BinarySearchTree)//非空树,左右子树都是二叉搜索树
}
extension BinarySearchTree {
init() {
self = .Leaf
}
init(_ value: Element) {
self = .Node(.Leaf, value, .Leaf)
}
}
//过滤,是否满足某个条件
extension SequenceType {
func all(predicate: Generator.Element -> Bool) -> Bool {
for x in self where !predicate(x) {
return false
}
return true
}
}
//检查一颗树是不是二叉树
extension BinarySearchTree where Element: Comparable {
var isBST: Bool {
switch self {
case .Leaf:
return true
case let .Node(left, x, right):
return left.elements.all { y in y < x }
&& right.elements.all { y in y > x }
&& left.isBST
&& right.isBST
}
}
}
我们来尝尝递归给我们带来的便利吧,我们来计算一棵树中存在的节点个数和所有的元素组成的数组:
//节点的总数
extension BinarySearchTree {
var count: Int {
switch self {
case .Leaf:
return 0
case let .Node(left, _, right):
return 1 + left.count + right.count
}
}
}
//所有的元素组成的数组
extension BinarySearchTree {
var elements: [Element] {
switch self {
case .Leaf:
return []
case let .Node(left, x, right):
return left.elements + [x] + right.elements
}
}
}
装完*,我们回归正题
- 检查一棵树是否为空
//检查一颗树是否为空
extension BinarySearchTree {
var isEmpty: Bool {
if case .Leaf = self {
return true
}
return false
}
}
- 是否包含某个元素
(这里需要利用到二叉搜索树的性质,如果是空树,直接返回false。不是空树的话,需要查找的元素和当前的节点相比较,值大于当前的节点话,就往右节点继续比较,值如果小于当前的节点的话,就往左节点继续比较。如果在比较的途中,遇到值和当前节点的值相同的话就返回true。如果走到底都没有找到的话就返回false)
//是否包含某个元素
extension BinarySearchTree {
func contains(x: Element) -> Bool {
switch self {
case .Leaf:
return false
case let .Node(_, y, _) where x == y:
return true
case let .Node(left, y, _) where x < y:
return left.contains(x)
case let .Node(_, y, right) where x > y:
return right.contains(x)
default:
fatalError("The impossible occurred")
}
}
}
- 插入操作(原理也是利用它的性质)
//插入操作
extension BinarySearchTree {
mutating func insert(x: Element) {
switch self {
case .Leaf:
self = BinarySearchTree(x)
case .Node(var left, let y, var right):
if x < y { left.insert(x) }
if x > y { right.insert(x) }
self = .Node(left, y, right)
}
}
}
来继续装一波,我们来测试一下刚刚我们写的这些方法:
首先初始化一棵树:
let myTree: BinarySearchTree = BinarySearchTree()
将myTree复制到另一个树,我们来看看mutating大法的好:
var copied = myTree
copied.insert(5)
//实际的值没有改变,被修改的只是变量
print(myTree.elements, copied.elements)//"[],[5]"
我们循环往这棵树里面插入一些值:
for i in 1...10{
copied.insert(i)
}
检查某个元素是否在这棵树里面:
print(copied.contains(5))//true
print(copied.contains(15))//false
基于字典树的自动补全
在了解了二叉树之后,下面会演示一个更加高级的纯函数式数据结构。我们就用自动补全来练手。需要达到的目标:在给定的一组搜索的历史纪录和一个待搜索字符串的前缀时,计算出一个与之相匹配的补全列表。
同样使用数组也可以实现,使用二叉搜索树也可以实现,但是数组的话依旧还是那个问题,效率不是很高,二叉搜索树前面也讲过了,这里我们换一种更加适合处理这类问题的字典树来解决。
- 字典树:又称为查找树,典型应用就是用于统计、排序和保存大量的字符串。经常被搜索引擎系统用于文本词频的统计,他的优点就是利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比较高。
字典树的性质:根节点外每一个节点都只包含一个字符;从根节点到某一个节点,路径上经过的字符连起来,为该节点对应的字符串,每个节点包含的所有子节点包含的字符串都不相同。

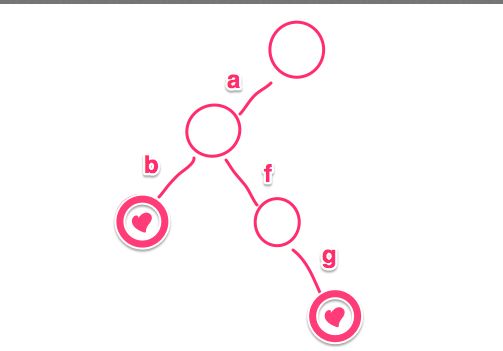
上面的这张图是由b,abc,bcd,abcd,efg,hii这6个单词构建的树。对于每一个节点,从根遍历到它的过程就是一个单词,如果这个节点被标记为红色,就代表这个单词存在,否则就不存在。对于一个单词,我们只要顺着它从根走到对应的节点,再看这个节点是不是红色就可以知道它是否出现过了。在把这个节点标记为红色,就相当于插入了这个单词。
简单的了解了字典树之后,我们应该如何在swift里面表示一棵字典树呢?结构体是个不错的选择。
struct Trie {
let isElement: Bool//当前节点的字符串是否已经存在在树中
let children: [Element: Trie]//节点处的字符与子字典树的映射关系
}
字典树的init()方法
//空的字典树
extension Trie {
init() {
isElement = false
children = [:]
}
}
计算出所有子树的所有元素,首先我们会检查当前的根结点是否被标记为一棵字典树的成员,如果是,这个字典树就包含一个空的键,反之result就被实例化为一个空的数组。然后遍历字典计算子树中的所有元素。
//计算出子树的所有元素
extension Trie {
var elements: [[Element]] {
var result: [[Element]] = isElement ? [[]] : []
for (key, value) in children {
result += value.elements.map { [key] + $0 }
}
return result
}
}
接下来 我们要开始装*之旅了。我们来定义查询和插入的函数,我们的字典树定义成了递归的结构体,但是数组却不能递归。所以说我们在放大招之前,要做点准备工作。
//遍历数组:我大元组法来辅助
extension Array {
var decompose: (Element, [Element])? {
return isEmpty ? nil : (self[startIndex], Array(self.dropFirst()))
}
}
准备工作做完之后就可以定义查询函数了,啦啦啦……
//辅助已放好大招
//查询
extension Trie {
func lookup(key: [Element]) -> Bool {
guard let (head, tail) = key.decompose else { return isElement }
guard let subtrie = children[head] else { return false }
return subtrie.lookup(tail)
}
}
比如说买东西去搜索的时候都是打一个“包包”。。然后搜索结果的列表就会出现“包包斜挎小包”“包包新款手提”“包包新款”“包包双肩”……所以说我们来小小的修改一哈,使其返回一个含有所有匹配元素的子树。
extension Trie {
func withPrefix(prefix: [Element]) -> Trie? {
guard let (head, tail) = prefix.decompose else { return self }
guard let remainder = children[head] else { return nil }
return remainder.withPrefix(tail)
}
}
一切工作准备就绪,我们就可以团战了,我们的目标不是推塔而是:在给定的一组搜索的历史纪录和一个待搜索字符串的前缀时,计算出一个与之相匹配的补全列表。
extension Trie {
func autocomplete(key: [Element]) -> [[Element]] {
return withPrefix(key)?.elements ?? []
}
}
现在我们就要验证一下我们的目标是否达到了,首先创建字典树:
( 如果传入的键组不为空,并且能够分解成 (head, tail) ,我们就用tail递归去创建一颗字典树。然后创建一个新的字典children。因为key非空所以意味着当前的键组尚未被全部存入
如果传入的键组为空,我们可以创建一颗木有子节点的空字典树,用于存储一个空的字符串)
extension Trie {
init(_ key: [Element]) {
if let (head, tail) = key.decompose {
let children = [head: Trie(tail)]
self = Trie(isElement: false, children: children)
} else {
self = Trie(isElement: true, children: [:])
}
}
}
写个方法往里面插入数据
(思路:如果传入的键组不为空,且能够被分解为head和tail,我们就用tail递归地创建一棵字典树,然后创建一个新的字典children,以head为键存储这个刚才递归创建的字典树,最后,我们用这个字典树创建一棵新的字典树。因为输入的key非空,这意味着当前的键组尚未被全部存入,所以说isElement应该是false。如果传入的键组为空,我们可以创建一棵木有子节点的空字典树,用于存储一个空字符串,并将isElement赋值为true)
extension Trie {
func insert(key: [Element]) -> Trie {
guard let (head, tail) = key.decompose else {
return Trie(isElement: true, children: children)
}
var newChildren = children
if let nextTrie = children[head] {
newChildren[head] = nextTrie.insert(tail)
} else {
newChildren[head] = Trie(tail)
}
return Trie(isElement: isElement, children: newChildren)
}
}
测试测试测试……
var trie = Trie(["a","b"])
trie = trie.insert(["a","f","g"])
print(trie)//Trie(isElement: false, children: ["a": Trie(isElement: false, children: ["b": Trie(isElement: true, children: [:]), "f": Trie(isElement: false, children: ["g": Trie(isElement: true, children: [:])])])])
print(trie.elements)//[["a", "b"], ["a", "f", "g"]]
print(trie.lookup(["a","b"]))//true
print(trie.lookup(["a","f","g"]))//true
print(trie.lookup(["a","f"]))//false
print(trie.autocomplete(["a"]))//[["b"], ["f", "g"]]
如果看上面的运行结果不好看,我给大家画了一个抽象派的字典树: