maskrcnn-benchmark框架下使用Maskrcnn训练自己的数据集
大家好,这是我的第一篇博客。作为深度学习的初学者,从实战的角度,详细介绍基于maskrcnn-benchmark框架下,使用Maskrcnn网络训练自己的数据集的过程。这其中,踩的坑不少,但也受益匪浅。不对的地方,还麻烦大家指正,一起进步。
简介
maskrcnn-benchmark框架由Facebook AI Research提出,基于Pytorch1.0,具有训练速度快,占用GPU较少等优点。详情可参考:https://github.com/facebookresearch/maskrcnn-benchmark,这里不再过多描述。
基础环境
操作系统:Ubuntu 16.04.6 4.15.0-96-generic GNU
编译环境:python 3.7.7 CUDA 10.2 opencv4.3.0等
由于设备问题,实验计算资源为网上租用,详情参考:https://www.longway-gpu.com/home;相关配置,如下图所示:

数据准备
训练数据来源于输电塔螺栓数据,标注工具为Labelme,由于标注得到的.json文件不符合所需的COCO数据集格式,故需要使用脚本文件转换。脚本文件、数据集组织如下:
脚本文件
import os
import shutil
import numpy as np
# train/val/test比例6:2:2
def data_split(img_path, json_path):
filelist = os.listdir(img_path)
filelist.remove('train')
filelist.remove('val')
filelist.remove('test')
jsonfile_path = os.path.join(json_path, 'train')
jsonfile_path = json_path
jsonlist = os.listdir(jsonfile_path)
# jsonlist.remove('train')
# jsonlist.remove('val')
# jsonlist.remove('test')
trainlist = np.random.choice(filelist, size=187, replace=False)
for filename in trainlist:
filepath = os.path.join(img_path, filename)
shutil.move(filepath, os.path.join(img_path, 'train'))
imgname = os.path.splitext(filename)[0]
for json in jsonlist:
if imgname == os.path.splitext(json)[0]:
jsonfile = os.path.join(jsonfile_path, json)
shutil.move(jsonfile, os.path.join(json_path, 'train'))
jsonlist.remove(json)
filelist.remove(filename)
# reslist = []
# for item in filelist:
# if item not in trainlist and not os.path.isdir(os.path.join(img_path, item)):
# reslist.append(item)
vallist = np.random.choice(filelist, size=63, replace=False)
for filename in vallist:
filepath = os.path.join(img_path, filename)
shutil.move(filepath, os.path.join(img_path, 'val'))
imgname = os.path.splitext(filename)[0]
for json in jsonlist:
if imgname == os.path.splitext(json)[0]:
jsonfile = os.path.join(jsonfile_path, json)
shutil.move(jsonfile, os.path.join(json_path, 'val'))
jsonlist.remove(json)
filelist.remove(filename)
# testlist = []
# for item in reslist:
# if item not in vallist:
# testlist.append(item)
for filename in filelist:
filepath = os.path.join(img_path, filename)
shutil.move(filepath, os.path.join(img_path, 'test'))
imgname = os.path.splitext(filename)[0]
for json in jsonlist:
if imgname == os.path.splitext(json)[0]:
jsonfile = os.path.join(jsonfile_path, json)
shutil.move(jsonfile, os.path.join(json_path, 'test'))
# jsonlist.remove(json)
# filelist.remove(filename)
# 只需要修改train/vallist中的size大小以及img_path和json_path的路径即可运行
# 图像的文件夹路径
img_path = 'E:\\data_luoshuan\\imgs'
# json文件的路径
json_path = 'E:\\data_luoshuan\\labels'
data_split(img_path, json_path)数据集组织
在/maskrcnn-benchmark/datasets目录下,创建文件夹,命名为coco。将上述转换得到的train/val/test文件夹放入coco目录下,并且创建annotations文件夹,将转换得到的train/val/test.json放入。如下图所示:

至此,数据集准备完毕。
安装框架
打开https://github.com/facebookresearch/maskrcnn-benchmark,查看INSTALL.md文件,如下所示。
## Installation
## 安装maskrcnn-benchmark的教程
### Requirements:
- PyTorch 1.0 from a nightly release. It **will not** work with 1.0 nor 1.0.1. Installation instructions can be found in https://pytorch.org/get-started/locally/
- torchvision from master
- cocoapi
- yacs
- matplotlib
- GCC >= 4.9
- OpenCV
### 选择一步步的安装模式,中间会有一些坑
### Option 1: Step-by-step installation
# 需要提前安装好anaconda,确保conda环境正确
```bash
# first, make sure that your conda is setup properly with the right environment
# for that, check that `which conda`, `which pip` and `which python` points to the
# right path. From a clean conda env, this is what you need to do
# 创建一个名为maskrcnn_benchmark的虚拟环境
conda create --name maskrcnn_benchmark
conda activate maskrcnn_benchmark
# 第一步,安装ipython
# this installs the right pip and dependencies for the fresh python
conda install ipython
# 第二步,安装一些依赖项
# maskrcnn_benchmark and coco api dependencies
pip install ninja yacs cython matplotlib tqdm opencv-python
# follow PyTorch installation in https://pytorch.org/get-started/locally/
# we give the instructions for CUDA 9.0
# 第三步,根据不同的cuda版本,安装pytorch
conda install -c pytorch pytorch-nightly torchvision cudatoolkit=9.0
export INSTALL_DIR=$PWD
# install pycocotools
# 第四步,没有坑
cd $INSTALL_DIR
git clone https://github.com/cocodataset/cocoapi.git
cd cocoapi/PythonAPI
python setup.py build_ext install
# install apex
# 第五步,可能会出现问题
cd $INSTALL_DIR
git clone https://github.com/NVIDIA/apex.git
cd apex
python setup.py install --cuda_ext --cpp_ext
# install PyTorch Detection
# 第六步,下载maskrcnn-benchmark代码
cd $INSTALL_DIR
git clone https://github.com/facebookresearch/maskrcnn-benchmark.git
cd maskrcnn-benchmark
# the following will install the lib with
# symbolic links, so that you can modify
# the files if you want and won't need to
# re-build it
# 最后一步
python setup.py build develop
unset INSTALL_DIR可能遇到的问题
问题:出现在上述第5步,如下图所示。
错误:No such file or directory: ':/usr/local/cuda:/usr/local/cuda-10.1/bin/nvcc':
解决方案:执行命令 export CUDA_HOME=/usr/local/cuda

训练指南
训练之前, 需要修改3个配置文件,下面逐个叙述。
首先,我们选用e2e_mask_rcnn_R_50_FPN_1x.yaml作为模型配置文件,并对其进行修改。
MODEL:
META_ARCHITECTURE: "GeneralizedRCNN"
# 预测的话,修改WEIGHT为训练得到的权重文件
WEIGHT: "catalog://ImageNetPretrained/MSRA/R-101"
BACKBONE:
CONV_BODY: "R-50-FPN"
RESNETS:
BACKBONE_OUT_CHANNELS: 256
RPN:
USE_FPN: True
ANCHOR_STRIDE: (4, 8, 16, 32, 64)
PRE_NMS_TOP_N_TRAIN: 2000
PRE_NMS_TOP_N_TEST: 1000
POST_NMS_TOP_N_TEST: 1000
FPN_POST_NMS_TOP_N_TEST: 1000
ROI_HEADS:
USE_FPN: True
ROI_BOX_HEAD:
NUM_CLASSES: 2
POOLER_RESOLUTION: 7
POOLER_SCALES: (0.25, 0.125, 0.0625, 0.03125)
POOLER_SAMPLING_RATIO: 2
FEATURE_EXTRACTOR: "FPN2MLPFeatureExtractor"
PREDICTOR: "FPNPredictor"
ROI_MASK_HEAD:
POOLER_SCALES: (0.25, 0.125, 0.0625, 0.03125)
FEATURE_EXTRACTOR: "MaskRCNNFPNFeatureExtractor"
PREDICTOR: "MaskRCNNC4Predictor"
POOLER_RESOLUTION: 14
POOLER_SAMPLING_RATIO: 2
RESOLUTION: 28
SHARE_BOX_FEATURE_EXTRACTOR: False
MASK_ON: True
# 修改数据集名称为自己的数据集名称
DATASETS:
TRAIN: ("coco_train","coco_val")
TEST: ("coco_test",)
DATALOADER:
SIZE_DIVISIBILITY: 32
SOLVER:
BASE_LR: 0.001
WEIGHT_DECAY: 0.0001
STEPS: (60000, 80000)
MAX_ITER: 100000
CHECKPOINT_PERIOD: 25000
TEST_PERIOD: 0
# 设置结果保存的路径
OUTPUT_DIR: root/maskrcnn-benchmark/results其次,修改数据集路径文件(/maskrcnn_benchmark/config/paths_catalog.py),只需按照格式增添自己的数据集。
# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
"""Centralized catalog of paths."""
import os
class DatasetCatalog(object):
DATA_DIR = "datasets"
DATASETS = {
# 修改此处的train val test
"train": {
"img_dir": "coco/train",
"ann_file": "coco/annotations/train.json"
},
"val": {
"img_dir": "coco/val",
"ann_file": "coco/annotations/val.json"
},
"test": {
"img_dir": "coco/test",
"ann_file": "coco/annotations/test.json"
},
"coco_2017_train": {
"img_dir": "coco/train2017",
"ann_file": "coco/annotations/instances_train2017.json"
},
"coco_2017_val": {
"img_dir": "coco/val2017",
"ann_file": "coco/annotations/instances_val2017.json"
},
"coco_2014_train": {
"img_dir": "coco/train2014",
"ann_file": "coco/annotations/instances_train2014.json"
},
"coco_2014_val": {
"img_dir": "coco/val2014",
"ann_file": "coco/annotations/instances_val2014.json"
},
"coco_2014_minival": {
"img_dir": "coco/val2014",
"ann_file": "coco/annotations/instances_minival2014.json"
},
"coco_2014_valminusminival": {
"img_dir": "coco/val2014",
"ann_file": "coco/annotations/instances_valminusminival2014.json"
},
"keypoints_coco_2014_train": {
"img_dir": "coco/train2014",
"ann_file": "coco/annotations/person_keypoints_train2014.json",
},
"keypoints_coco_2014_val": {
"img_dir": "coco/val2014",
"ann_file": "coco/annotations/person_keypoints_val2014.json"
},
"keypoints_coco_2014_minival": {
"img_dir": "coco/val2014",
"ann_file": "coco/annotations/person_keypoints_minival2014.json",
},
"keypoints_coco_2014_valminusminival": {
"img_dir": "coco/val2014",
"ann_file": "coco/annotations/person_keypoints_valminusminival2014.json",
},
"voc_2007_train": {
"data_dir": "voc/VOC2007",
"split": "train"
},
"voc_2007_train_cocostyle": {
"img_dir": "voc/VOC2007/JPEGImages",
"ann_file": "voc/VOC2007/Annotations/pascal_train2007.json"
},
"voc_2007_val": {
"data_dir": "voc/VOC2007",
"split": "val"
},
"voc_2007_val_cocostyle": {
"img_dir": "voc/VOC2007/JPEGImages",
"ann_file": "voc/VOC2007/Annotations/pascal_val2007.json"
},
"voc_2007_test": {
"data_dir": "voc/VOC2007",
"split": "test"
},
"voc_2007_test_cocostyle": {
"img_dir": "voc/VOC2007/JPEGImages",
"ann_file": "voc/VOC2007/Annotations/pascal_test2007.json"
},
"voc_2012_train": {
"data_dir": "voc/VOC2012",
"split": "train"
},
"voc_2012_train_cocostyle": {
"img_dir": "voc/VOC2012/JPEGImages",
"ann_file": "voc/VOC2012/Annotations/pascal_train2012.json"
},
"voc_2012_val": {
"data_dir": "voc/VOC2012",
"split": "val"
},
"voc_2012_val_cocostyle": {
"img_dir": "voc/VOC2012/JPEGImages",
"ann_file": "voc/VOC2012/Annotations/pascal_val2012.json"
},
"voc_2012_test": {
"data_dir": "voc/VOC2012",
"split": "test"
# PASCAL VOC2012 doesn't made the test annotations available, so there's no json annotation
},
"cityscapes_fine_instanceonly_seg_train_cocostyle": {
"img_dir": "cityscapes/images",
"ann_file": "cityscapes/annotations/instancesonly_filtered_gtFine_train.json"
},
"cityscapes_fine_instanceonly_seg_val_cocostyle": {
"img_dir": "cityscapes/images",
"ann_file": "cityscapes/annotations/instancesonly_filtered_gtFine_val.json"
},
"cityscapes_fine_instanceonly_seg_test_cocostyle": {
"img_dir": "cityscapes/images",
"ann_file": "cityscapes/annotations/instancesonly_filtered_gtFine_test.json"
}
}
@staticmethod
def get(name):
if "coco" in name:
data_dir = DatasetCatalog.DATA_DIR
attrs = DatasetCatalog.DATASETS[name]
args = dict(
root=os.path.join(data_dir, attrs["img_dir"]),
ann_file=os.path.join(data_dir, attrs["ann_file"]),
)
return dict(
factory="COCODataset",
args=args,
)
elif "voc" in name:
data_dir = DatasetCatalog.DATA_DIR
attrs = DatasetCatalog.DATASETS[name]
args = dict(
data_dir=os.path.join(data_dir, attrs["data_dir"]),
split=attrs["split"],
)
return dict(
factory="PascalVOCDataset",
args=args,
)
raise RuntimeError("Dataset not available: {}".format(name))
class ModelCatalog(object):
S3_C2_DETECTRON_URL = "https://dl.fbaipublicfiles.com/detectron"
C2_IMAGENET_MODELS = {
"MSRA/R-50": "ImageNetPretrained/MSRA/R-50.pkl",
"MSRA/R-50-GN": "ImageNetPretrained/47261647/R-50-GN.pkl",
"MSRA/R-101": "ImageNetPretrained/MSRA/R-101.pkl",
"MSRA/R-101-GN": "ImageNetPretrained/47592356/R-101-GN.pkl",
"FAIR/20171220/X-101-32x8d": "ImageNetPretrained/20171220/X-101-32x8d.pkl",
}
C2_DETECTRON_SUFFIX = "output/train/{}coco_2014_train%3A{}coco_2014_valminusminival/generalized_rcnn/model_final.pkl"
C2_DETECTRON_MODELS = {
"35857197/e2e_faster_rcnn_R-50-C4_1x": "01_33_49.iAX0mXvW",
"35857345/e2e_faster_rcnn_R-50-FPN_1x": "01_36_30.cUF7QR7I",
"35857890/e2e_faster_rcnn_R-101-FPN_1x": "01_38_50.sNxI7sX7",
"36761737/e2e_faster_rcnn_X-101-32x8d-FPN_1x": "06_31_39.5MIHi1fZ",
"35858791/e2e_mask_rcnn_R-50-C4_1x": "01_45_57.ZgkA7hPB",
"35858933/e2e_mask_rcnn_R-50-FPN_1x": "01_48_14.DzEQe4wC",
"35861795/e2e_mask_rcnn_R-101-FPN_1x": "02_31_37.KqyEK4tT",
"36761843/e2e_mask_rcnn_X-101-32x8d-FPN_1x": "06_35_59.RZotkLKI",
"37129812/e2e_mask_rcnn_X-152-32x8d-FPN-IN5k_1.44x": "09_35_36.8pzTQKYK",
# keypoints
"37697547/e2e_keypoint_rcnn_R-50-FPN_1x": "08_42_54.kdzV35ao"
}
@staticmethod
def get(name):
if name.startswith("Caffe2Detectron/COCO"):
return ModelCatalog.get_c2_detectron_12_2017_baselines(name)
if name.startswith("ImageNetPretrained"):
return ModelCatalog.get_c2_imagenet_pretrained(name)
raise RuntimeError("model not present in the catalog {}".format(name))
@staticmethod
def get_c2_imagenet_pretrained(name):
prefix = ModelCatalog.S3_C2_DETECTRON_URL
name = name[len("ImageNetPretrained/"):]
name = ModelCatalog.C2_IMAGENET_MODELS[name]
url = "/".join([prefix, name])
return url
@staticmethod
def get_c2_detectron_12_2017_baselines(name):
# Detectron C2 models are stored following the structure
# prefix//2012_2017_baselines/.yaml./suffix
# we use as identifiers in the catalog Caffe2Detectron/COCO//
prefix = ModelCatalog.S3_C2_DETECTRON_URL
dataset_tag = "keypoints_" if "keypoint" in name else ""
suffix = ModelCatalog.C2_DETECTRON_SUFFIX.format(dataset_tag, dataset_tag)
# remove identification prefix
name = name[len("Caffe2Detectron/COCO/"):]
# split in and
model_id, model_name = name.split("/")
# parsing to make it match the url address from the Caffe2 models
model_name = "{}.yaml".format(model_name)
signature = ModelCatalog.C2_DETECTRON_MODELS[name]
unique_name = ".".join([model_name, signature])
url = "/".join([prefix, model_id, "12_2017_baselines", unique_name, suffix])
return url
最后,修改框架默认的配置文件(/maskrcnn_benchmark/config/defaults.py)。只需要修改NUM_CLASSES为自己的类别数+1(背景)、_C.TEST.IMS_PER_BATCH根据自己的GPU数修改为合适的值即可。
# 训练
python tools/train_net.py --config-file configs/e2e_mask_rcnn_R_50_FPN_1x.yaml
# 测试
python tools/test_net.py --config-file configs/e2e_mask_rcnn_R_50_FPN_1x.yaml
可能遇到的问题
问题1:执行训练命令
错误:Dataset not available:train
解决方案:检查paths_catalog.py中数据集名称是否正确

问题2:执行训练命令
错误:AttributeError:HORIZONTAL_FLIP_TRAIN
解决方案:在defaults.py中添加“HORIZONTAL_FLIP_TRAIN=0”即可
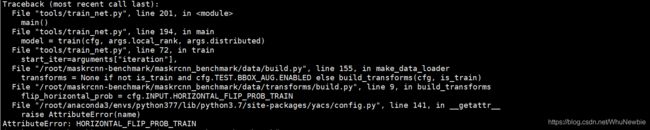
问题3:执行训练命令
错误:No module named 'cityscapesscripts'
解决方案:如下所示
git clone https://github.com/mcordts/cityscapesScripts.git
cd cityscapesScripts/
python setup.py build_ext install预测
训练完成后,得到权重文件.pth。修改e2e_mask_rcnn_R_50_FPN_1x.yaml文件:WEIGHT: "../model_0100000.pth"。编写预测脚本,如下所示:
import matplotlib.pyplot as plt
import matplotlib.pylab as pylab
import requests
from io import BytesIO
from PIL import Image
import numpy as np
import cv2
from glob import glob
import os
pylab.rcParams['figure.figsize'] = 20, 12
from maskrcnn_benchmark.config import cfg
from predictor import COCODemo
# 参数配置文件
config_file = "/root/maskrcnn-benchmark/configs/e2e_mask_rcnn_R_50_FPN_1x.yaml"
# update the config options with the config file
cfg.merge_from_file(config_file)
# manual override some options
cfg.merge_from_list(["MODEL.DEVICE", "cuda"])
# cfg.MODEL.WEIGHT = '../pretrained/e2e_mask_rcnn_R_101_FPN_1x.pth'
coco_demo = COCODemo(cfg, min_image_size=800, confidence_threshold=0.7, )
# if False:
# pass
# else:
#imgurl = "http://farm3.staticflickr.com/2469/3915380994_2e611b1779_z.jpg"
# response = requests.get(imgurl)
# pil_image = Image.open(BytesIO(response.content)).convert("RGB")
# imgfile = '/root/maskrcnn-benchmark/datasets/coco/coco_test/G2A65_ls_066.jpg'
def img_load(imgfile):
pil_image = Image.open(imgfile).convert("RGB")
image = np.array(pil_image)[:, :, [2, 1, 0]]
return image
# pil_image = Image.open(imgfile).convert("RGB")
# # pil_image.show()
# # image:uint8
# image = np.array(pil_image)[:, :, [2, 1, 0]]
# 7.16 新增
# image = image.astype(np.float32)
# image.save('/root/maskrcnn-benchmark/results/G2A67.jpg')
# print(image)
# 7.15 新增
# image = cv2.imread(imgfile)
# 影像路径
img_path = '/root/maskrcnn-benchmark/datasets/coco/coco_test/'
files_jpg = glob(img_path + "*.jpg")
files_jpg = [i.replace('\\', '/').split("/")[-1] for i in files_jpg]
for file in files_jpg:
image = img_load(img_path+file)
file_name = os.path.splitext(file)[0]
file_type = os.path.splitext(file)[1]
predictions = coco_demo.run_on_opencv_image(image)
# predictions = np.array(predictions)
cv2.imwrite('/root/maskrcnn-benchmark/results/'+file_name+'-test'+file_type,predictions)
# cv2.imwrite('/root/maskrcnn-benchmark/results/G2A67.jpg',predictions)
结语
内容如果有不清楚或者错误的,请联系QQ:602367687,希望和大家一起多交流学习。