文章已授权,原文自Rady Lao《Predicting Employee Kernelover
》

有些公司尽管业绩蒸蒸日上,但却会在人力资源上屡屡碰壁。不断有员工陆续离职,却不知如何是好,某种意义来说是员工塑造了公司的文化。长期的成功、健康的工作环境和较高的员工留存率才是成功公司的标志。但是当一个公司的员工流失率很高时,公司运作就会产生问题。
正确地认识和理解员工离职的原因,将会帮助公司限制这种情况的发生,甚至可能提高员工的生产力。这种预测性的报告会给人力资源部门带来很大的帮助。
Zig Ziglar曾经说过:"你无须自己建立商业. 你只需要培养人才, 让人才来为你建立商业."
关于这次教程
如果你对人力资源的话题感兴趣,并想详细的了解如何通过数据科学的角度来处理员工保留问题,请随意阅读本教程..
本文将全面覆盖分析和方法,并且涵盖整个数据科学不同的处理过程,包括统计推断和探索性数据分析。本文主要目的是推理员工离职的原因,并提出一个对流失员工的风险模型。最后会创造一个推荐的保留计划,其中会包括不同风险磨损下保持员工留存的最佳实践。
本教程将会永远不断改进。希望大家留下评论帮助教程的进步!任何意见或建设性批评对我都是极大的赞赏!谢谢你们!
OSEMN原则
我会遵循一种经典的数据科学流水线方法,其名为“OSEMN” (发音不错)
- Obtain(获取):解决问题首先要能获取到数据
- Scrub (清洗):这包含对缺失数据或无效数据的数据填补和固定列名。
- Explore (探索):再然后就是探索数据,我们希望从数据中得到一些新的启发。我们要找出离群数据和怪异数据,并理解每一个可解释性变量和响应变量之间的关系,为此我们可以用相关系数矩阵来搞定。
- Model(建模):数据建模可以预测是否员工会离职
- INterpret (解读):最后一步是解读数据。随着数据分析,最后我们会得出什么结论呢?什么因素导致员工离职呢?我们是否发现变量之间的关系?
注:本教程数据集由Kaggle提供,数据都是伪造的,仅供参考。
第一节:获取数据
本节数据集可有Kaggle官网下载,也可以从我的百度网盘下载https://pan.baidu.com/s/1qYKC6Yw
# 导入数据处理模块和数据可视化模块
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as matplot
import seaborn as sns
%matplotlib inline
#读取csv数据并且将数据集以数据帧(dataframe)的形式存储,叫做 "df"
df = pd.DataFrame.from_csv('../input/HR_comma_sep.csv', index_col=None)
第二节:清洗数据
一般来说,数据清洗是耗时耗力的大活而且算是一种“脏活”...但是这次来自Kaggle的数据集非常的干净几乎没有缺陷值。但是,我们依然要按流程走一遍清洗过程,确保内容都是可读的,还有观察值与特征名是否能匹配。
# 检查数据中是否有缺失值
df.isnull().any()
输出:
satisfaction_level False
last_evaluation False
number_project False
average_montly_hours False
time_spend_company False
Work_accident False
left False
promotion_last_5years False
sales False
salary False
dtype: bool
快速浏览一下数据集
df.head()
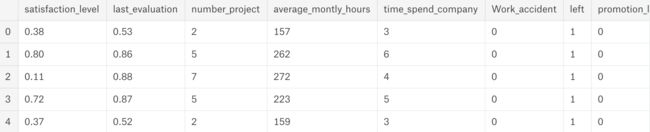
为了提升可读性,修改一下列名
df = df.rename(columns={'satisfaction_level': 'satisfaction',
'last_evaluation': 'evaluation',
'number_project': 'projectCount',
'average_montly_hours': 'averageMonthlyHours',
'time_spend_company': 'yearsAtCompany',
'Work_accident': 'workAccident',
'promotion_last_5years': 'promotion',
'sales' : 'department',
'left' : 'turnover'
})
将变量 "turnover" (人事变更率)挪到表格首列
front = df['turnover']
df.drop(labels=['turnover'], axis=1,inplace = True)
df.insert(0, 'turnover', front)
df.head()
第三节:探索数据
3a. 大致浏览
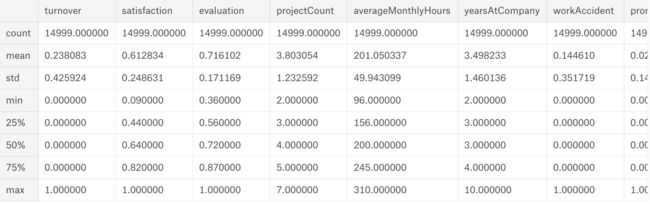
探索数据集结果如下:
- 大约 15000 个雇员观察值和10个特征值
- 公司人事变更率达到百分之24
- 员工平均满意度为0.61
下面为探索过程:
df.shape
输出:
(14999, 10)
检查特征值类型
df.dtypes
输出:
turnover int64
satisfaction float64
evaluation float64
projectCount int64
averageMonthlyHours int64
yearsAtCompany int64
workAccident int64
promotion int64
department object
salary object
dtype: object
看起来大约76%的员工留下来,24%的员工离开了
注意:当交叉验证时,维持转化率非常重要
turnover_rate = df.turnover.value_counts() / len(df)
turnover_rate
输出:
0 0.761917
1 0.238083
Name: turnover, dtype: float64
大致浏览一下雇员信息
df.describe()
按人事已离职 & 未离职分组
turnover_Summary = df.groupby('turnover')
turnover_Summary.mean()

3b. 相关系数矩阵 & 热图
使用相关系数矩阵
corr = df.corr()
corr = (corr)
sns.heatmap(corr,
xticklabels=corr.columns.values,
yticklabels=corr.columns.values)
corr

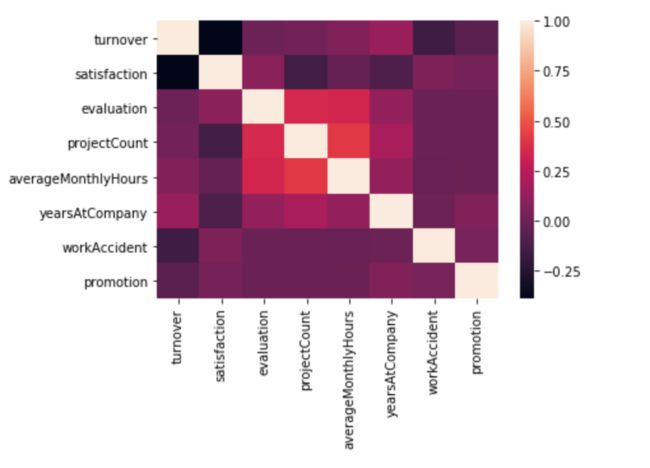
本阶段总结如下:
中度正相关特征:
- projectCount项目数 vs evaluation评估: 0.349333
- projectCount项目数 vs averageMonthlyHours每月工作小时数: 0.417211
- averageMonthlyHours每月工作小时数 vs evaluation评估: 0.339742
中度负相关特征:
- satisfaction满意度 vs turnover离职率::-0.388375
根据上述报告,不妨思考下面问题:
- 什么变量因素对离职结果影响最大?
- 哪些特征有很强的相关性?
- 我们能更深入地检查这些特征吗?
阶段总结:
从热图中可以发现,projectCount项目数和averageMonthlyHours每月工作小时数和evaluation评估是正相关的。这是否说明花的时间越多的员工和做更多项目的员工评价就越高呢?
我们也发现离职率和满意度是高度负相关的,因此可以假设想离职的员工往往对公司不太满意。
3b2: 相关统计检验
单样本t检验(测试满意度)
单样本t检验检测的是是否单样本均值和总均值不一致。由于满意度和离职率有高度相关性,我们来看一下离职员工的平均满意度是否和未离职员工的平均满意度不一致。
假设检验:
- 虚无假设:(H0: pTS = pES) 虚无假设就是说明离职员工的平均满意度和未离职员工的平均满意度没有什么区别。
- 对立假设:(HA: pTS != pES)对立假设就是离职员工的平均满意度和未离职员工的平均满意度的确有差异的情况
下面代码来比较一下满意度均值
#emp_population = df['satisfaction'].mean()
emp_population = df['satisfaction'][df['turnover'] == 0].mean()
emp_turnover_satisfaction = df[df['turnover']==1]['satisfaction'].mean()
print( '未离职员工的满意度均值' + str(emp_population))
print( '离职员工的满意度均值' + str(emp_turnover_satisfaction) )
输出:
未离职员工的满意度均值: 0.666809590479516
离职员工的满意度均值: 0.44009801176140917
进行t检验
现在以95%的置信度进行t检验,看看它是否能否定与总体员工有同样分布的样本的虚无假设。为了执行t检验,使用stats.ttest_1samp()函数
import scipy.stats as stats
stats.ttest_1samp(a= df[df['turnover']==1]['satisfaction'], # 离职员工满意度样本
popmean = emp_population) # 未离职员工满意度均值
T检验结果
测试结果表明,检验统计量T等于-51.33。这个测试的统计告诉我们多少样本均值偏离虚无假设。如果在相应的置信度和自由度,统计量不在t分布的分位数范围,我们就可以否定虚无假设,我们可以用 stats.t.ppf(): 来查看分位数
T检验分位数
如果我们计算的-51.33不在分位数范围,我们就可以否定虚无假设。
degree_freedom = len(df[df['turnover']==1])
LQ = stats.t.ppf(0.025,degree_freedom) # 左分位数
RQ = stats.t.ppf(0.975,degree_freedom) # 右分位数
print ('The t-distribution left quartile range is: ' + str(LQ))
print ('The t-distribution right quartile range is: ' + str(RQ))
单样本t检验总结
T-Test = -51.33 | P-Value = 0.000_ | Reject Null Hypothesis
这里有个问题是P的值为什么0,是如何得出的?你知道是为什么吗?
否定虚无假设是因为:
- t检验的分数超出范围
- P值小于5%的置信水平
在单样本t检验的统计分析基础上,离职员工的满意度与总体满意度之间存在显著性差异。在5%置信水平下为0的超低P值是一个否定虚无假设的很好的指标。
但这并不一定意味着有很重要的现实意义。我们必须进行更多的实验,或者收集更多有关员工的数据,以便找到更准确的结果。
3bc.分布图(满意度-评价-每月工作小时数)
# 建立matplotlib轮廓
f, axes = plt.subplots(ncols=3, figsize=(15, 6))
# 雇员满意度图
sns.distplot(df.satisfaction, kde=False, color="g", ax=axes[0]).set_title('Employee Satisfaction Distribution')
axes[0].set_ylabel('Employee Count')
# 雇员评价图
sns.distplot(df.evaluation, kde=False, color="r", ax=axes[1]).set_title('Employee Evaluation Distribution')
axes[1].set_ylabel('Employee Count')
# 雇员每月小时图
sns.distplot(df.averageMonthlyHours, kde=False, color="b", ax=axes[2]).set_title('Employee Average Monthly Hours Distribution')
axes[2].set_ylabel('Employee Count')

阶段总结:下面来测试一下员工的特征分布。这里是我发现的特点:
- 满意度:低满意度和高满意度的员工都有巨大幅度点
- 评估:低评价员工(即小于0.6)和高评价员工(即大于0.8)呈现双峰分布
- 每月工作数:干活少的员工(小于150小时)和干活多的员工(大于250小时)也呈现双峰分布
- 评价图和每月工作图都呈现相似的分布
- 工作时间少的员工评价普遍低,长的员工则评价高
- 如果你回过头看看相关系数矩阵,你也可以发现评价与工作时长的规律
根据上述结论,你可以思考一下:
- 为什么低评价员工会有一个巨大幅度点?
- 雇员是否可以按照这些特征分组?
- 评价和每月工作数是否有相关性?
3d、薪水和离职率
f, ax = plt.subplots(figsize=(15, 4))
sns.countplot(y="salary", hue='turnover', data=df).set_title('Employee Salary Turnover Distribution');

阶段总结:下面一些情况很常见,如下:
- 离职的大多数都是低薪和中等薪水
- 很少有高薪员工会离职
- 低薪至平均薪水的员工都会有趋势离职
根据上述结论,你可以思考一下:
- 低薪、中等薪水、高薪的工作环境是什么?
- 什么原因会使得高薪员工离职?
3e. 部门和离职率
# 员工分布
# 颜色类型
color_types = ['#78C850','#F08030','#6890F0','#A8B820','#A8A878','#A040A0','#F8D030',
'#E0C068','#EE99AC','#C03028','#F85888','#B8A038','#705898','#98D8D8','#7038F8']
# 数量图
sns.countplot(x='department', data=df, palette=color_types).set_title('Employee Department Distribution');
# 旋转x标签
plt.xticks(rotation=-45)

f, ax = plt.subplots(figsize=(15, 5))
sns.countplot(y="department", hue='turnover', data=df).set_title('Employee Department Turnover Distribution');
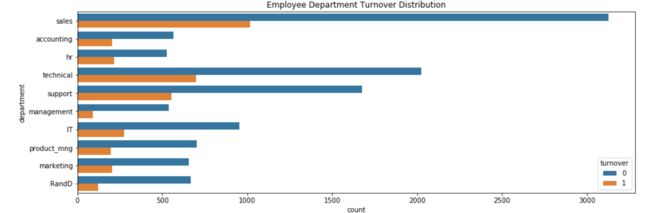
阶段总结:让我们看看关于部门的信息,下面是我发现的特点:
- 销售部门、技术部门、服务部门是员工离职率最高的三个部门
- 管理部门的离职率很小
根据上述结论,你可以思考一下:
- 如果我们拥有关于部门的更多信息,是否我们就可以直接找到员工离职的直接原因呢?
3f.离职率和项目数
ax = sns.barplot(x="projectCount", y="projectCount", hue="turnover", data=df, estimator=lambda x: len(x) / len(df) * 100)
ax.set(ylabel="Percent")
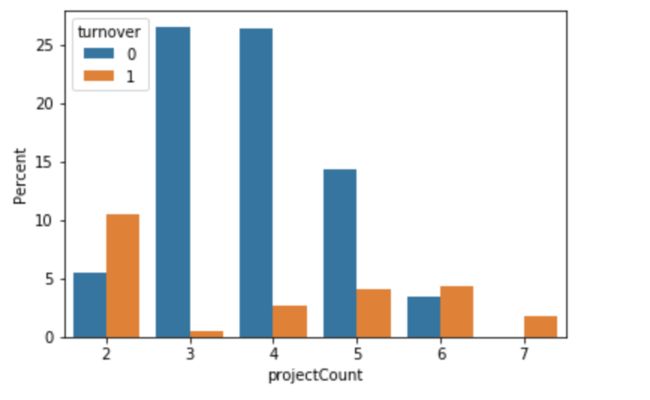
阶段总结:这个图十分有意思,我们可以发现以下几点:
- 超过1半拥有2个、6个、7个数量的项目的员工离职了
- 大多数没有离职的员工的项目数是3个、4个、5个
- 拥有7个项目的雇员都离职了
- 项目越多,离职率也会增长
根据上述结论,你可以思考一下:
- 为什么低项目数/高项目数的员工会离职?
- 这是否意味着有2个或更少项目的员工不够努力,或者没有被高度重视,从而离开了公司?
- 有6以上的项目的员工是否因为过度劳累,从而离开公司吗?
3g. 离职率和评价
fig = plt.figure(figsize=(15,4),)
ax=sns.kdeplot(df.loc[(df['turnover'] == 0),'evaluation'] , color='b',shade=True,label='no turnover')
ax=sns.kdeplot(df.loc[(df['turnover'] == 1),'evaluation'] , color='r',shade=True, label='turnover')
ax.set(xlabel='Employee Evaluation', ylabel='Frequency')
plt.title('Employee Evaluation Distribution - Turnover V.S. No Turnover')

阶段总结:
- 离职员工的图谱呈现了双峰分布
- 评价低的员工更有趋势离职
- 高评价的员工更有趋势离职
- 未离职员工的甜蜜点是在0.6-0.8这个范围内
3h.离职率和每月工作小时数
fig = plt.figure(figsize=(15,4))
ax=sns.kdeplot(df.loc[(df['turnover'] == 0),'averageMonthlyHours'] , color='b',shade=True, label='no turnover')
ax=sns.kdeplot(df.loc[(df['turnover'] == 1),'averageMonthlyHours'] , color='r',shade=True, label='turnover')
ax.set(xlabel='Employee Average Monthly Hours', ylabel='Frequency')
plt.title('Employee AverageMonthly Hours Distribution - Turnover V.S. No Turnover')
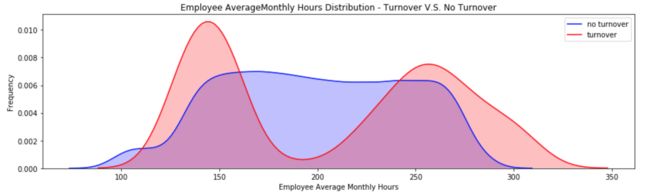
阶段总结:
- 离职员工的每月小时数也呈现双峰分布
- 工作时间短(少于150小时)的员工更容易离职
- 工作时间长(大于250小时)的员工更容易离职
- 离职员工一般都是工作过少或是重度工作的
3i. 离职率和满意度
fig = plt.figure(figsize=(15,4))
ax=sns.kdeplot(df.loc[(df['turnover'] == 0),'satisfaction'] , color='b',shade=True, label='no turnover')
ax=sns.kdeplot(df.loc[(df['turnover'] == 1),'satisfaction'] , color='r',shade=True, label='turnover')
plt.title('Employee Satisfaction Distribution - Turnover V.S. No Turnover')
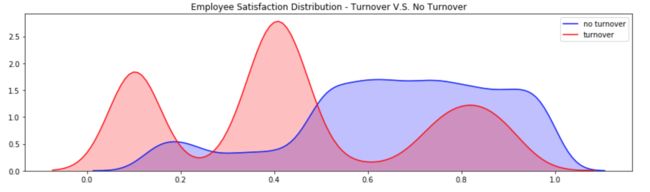
阶段总结:
- 离职员工呈现三模态分布
- 非常低满意度(小于0.2)的员工更容易离职
- 低满意度(0.3~0.5)更容易离职
- 非常高满意度(大于0.7)更容易离职
3j.项目数和每月工作小时数
import seaborn as sns
sns.boxplot(x="projectCount", y="averageMonthlyHours", hue="turnover", data=df)

阶段总结:
- 随着项目数量增加,工作时间也会增加
- 关于离职员工和非离职员工的工作时间差异,这点很让人奇怪
- 尽管项目数量的增加,非离职员工的工作时间也呈现了一致性
- 相比之下,离职员工随着项目增加,每月工作时间也会增加
根据上述结论,你可以思考一下:
- 这个现象意味什么?
- 为什么即使在同一项目中,离职员工的工作时间比非离职员工的工作时间长?
3k. 项目数和评价
总结:这个图看上去和上面那图差不多。但是离职组的图看上去有些奇怪,在离职组中,项目做得越多的人评价越高。但是非离职组的人,尽管项目数量增加,他们的评分却保持一致性。
需要思考的问题是:
- 即使在项目增加的情况下,离职员工的普遍得分要高于非离职员工?
- 低评价员工的离职倾向为什么反而不是更高的?
import seaborn as sns
sns.boxplot(x="projectCount", y="evaluation", hue="turnover", data=df)
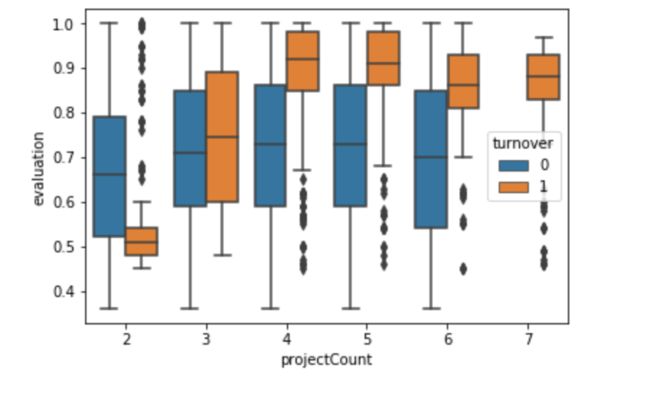
3l. 满意度和评价
sns.lmplot(x='satisfaction', y='evaluation', data=df,
fit_reg=False, # No regression line
hue='turnover') # Color by evolution stage
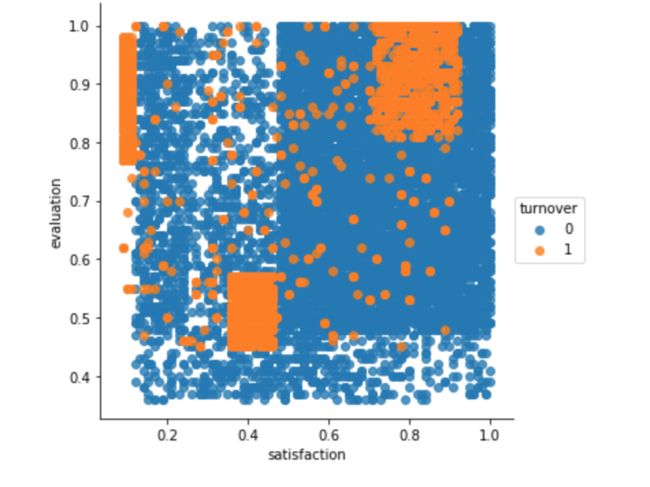
阶段总结: 这是目前为止最有意思的图表,我发现离职员工有三种截然不同的集群
- 集群一(努力工作但是不开心的员工):满意度低于0.2但是评价却高于0.75,这可能就暗示了尽管员工卖力工作,但他对自己的工作并不感到开心。
- 思考点:当你受到高度评价的时候,什么原因会让你感觉如此糟糕?工作太辛苦了吗?这个集群是否意味着“过度劳累”的员工?
- 集群二(表现糟糕也不开心的员工):满意度在0.35-0.45,评价低于0.58,这可以被推测为由于员工被评价低,感觉对公司不满意
- 思考点:这个集群是否理解为”执行力不足“的员工?
- 集群三(努力工作感到幸福的员工):满意度在0.7-1.0,评价大于0.8。这可以为理解为是”理想“员工,他们热爱工作并且表现良好。
- 思考点:这是否理解为这个集群的离职员工是因为找到新的工作机会?
3m. 离职率和待在公司的年数
ax = sns.barplot(x="yearsAtCompany", y="yearsAtCompany", hue="turnover", data=df, estimator=lambda x: len(x) / len(df) * 100)
ax.set(ylabel="Percent")
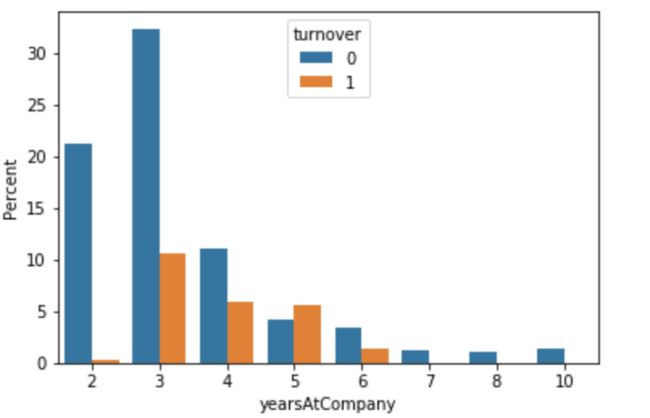
阶段总结:
- 待在公司4-5年的员工有超过一半离职了
- 5年的雇员应该被高度重视
根据上述结论,你可以思考一下:
- 为什么离职员工会在3-5年这个范围
- 这些离职员工是谁
- 这些员工是兼职的还是承包人?
3n. 员工离职的k均值分布
# 导入k均值模型
from sklearn.cluster import KMeans
# 图和创造3个离职员工集群
kmeans = KMeans(n_clusters=3,random_state=2)
kmeans.fit(df[df.turnover==1][["satisfaction","evaluation"]])
kmeans_colors = ['green' if c == 0 else 'blue' if c == 2 else 'red' for c in kmeans.labels_]
fig = plt.figure(figsize=(10, 6))
plt.scatter(x="satisfaction",y="evaluation", data=df[df.turnover==1],
alpha=0.25,color = kmeans_colors)
plt.xlabel("Satisfaction")
plt.ylabel("Evaluation")
plt.scatter(x=kmeans.cluster_centers_[:,0],y=kmeans.cluster_centers_[:,1],color="black",marker="X",s=100)
plt.title("Clusters of Employee Turnover")
plt.show()

集群一(蓝色):努力工作但不开心的员工
集群二(红色):表现糟糕且不开心的员工
集群三(绿色):努力工作且开心的员工
关于集群问题:
- 我们如何得出是3个集群?
- 我们需要专业的领域知识来确定集群的分类
- 我们可以发现隐藏的未知结构集群
特征重要性
from sklearn import tree
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
plt.style.use('fivethirtyeight')
plt.rcParams['figure.figsize'] = (12,6)
# 为了可读性,修改列名
df = df.rename(columns={'satisfaction_level': 'satisfaction',
'last_evaluation': 'evaluation',
'number_project': 'projectCount',
'average_montly_hours': 'averageMonthlyHours',
'time_spend_company': 'yearsAtCompany',
'Work_accident': 'workAccident',
'promotion_last_5years': 'promotion',
'sales' : 'department',
'left' : 'turnover'
})
# 将这些变量转换为分类变量
df["department"] = df["department"].astype('category').cat.codes
df["salary"] = df["salary"].astype('category').cat.codes
# 创造训练集和测试集
target_name = 'turnover'
X = df.drop('turnover', axis=1)
y=df[target_name]
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.15, random_state=123, stratify=y)
dtree = tree.DecisionTreeClassifier(
#max_depth=3,
class_weight="balanced",
min_weight_fraction_leaf=0.01
)
dtree = dtree.fit(X_train,y_train)
## 重要性图表 ##
importances = dtree.feature_importances_
feat_names = df.drop(['turnover'],axis=1).columns
indices = np.argsort(importances)[::-1]
plt.figure(figsize=(12,6))
plt.title("Feature importances by DecisionTreeClassifier")
plt.bar(range(len(indices)), importances[indices], color='lightblue', align="center")
plt.step(range(len(indices)), np.cumsum(importances[indices]), where='mid', label='Cumulative')
plt.xticks(range(len(indices)), feat_names[indices], rotation='vertical',fontsize=14)
plt.xlim([-1, len(indices)])
plt.show()

阶段总结:
通过使用决策树分类器,它可以为预测任务将特征排名。前三个特征分别是员工满意度、在职时间和评价。这有助于帮助我们建立回归模型,当我们使用较少特性时,会更容易理解我们的模型。
前三个特征:
- 满意度
- 在职时间
- 评价
4a.数据建模:逻辑回归分析
注意:接下来要用逻辑回归分类器做一个深度分析。我会在其他章节讨论其他模型。
逻辑回归被用于预测事情发生的可能率。与线性回归相反,逻辑回归的输出是用logit函数变换得到的。所以最后结果输出0或1。运用这个模型我们可以预测用户是否会留下来。值0表示员工留下来的概率,值1表示员工离职的概率。
我们选择逻辑回归是因为它的可解释性。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as matplot
import seaborn as sns
%matplotlib inline
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report, precision_score, recall_score, confusion_matrix, precision_recall_curve
from sklearn.preprocessing import RobustScaler
df = pd.DataFrame.from_csv('../input/HR_comma_sep.csv', index_col=None)
df = df.rename(columns={'satisfaction_level': 'satisfaction',
'last_evaluation': 'evaluation',
'number_project': 'projectCount',
'average_montly_hours': 'averageMonthlyHours',
'time_spend_company': 'yearsAtCompany',
'Work_accident': 'workAccident',
'promotion_last_5years': 'promotion',
'sales' : 'department',
'left' : 'turnover'
})
df["department"] = df["department"].astype('category').cat.codes
df["salary"] = df["salary"].astype('category').cat.codes
front = df['turnover']
df.drop(labels=['turnover'], axis=1,inplace = True)
df.insert(0, 'turnover', front)
# 创建logistic回归方程的截距项
df['int'] = 1
indep_var = ['satisfaction', 'evaluation', 'yearsAtCompany', 'int', 'turnover']
df = df[indep_var]
# 创建训练集和测试集
target_name = 'turnover'
X = df.drop('turnover', axis=1)
y=df[target_name]
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.15, random_state=123, stratify=y)
X_train.head()
#

使用逻辑回归系数
将其他变量排除后,使用最重要的三个变量创建模型:满意度、评估、在职时间
员工离职分数=满意度(-3.769022) + 评价(0.207596)+在职时间*(0.170145)+0.181896
import statsmodels.api as sm
iv = ['satisfaction','evaluation','yearsAtCompany', 'int']
logReg = sm.Logit(y_train, X_train[iv])
answer = logReg.fit()
answer.summary()
answer.params
输出:
Optimization terminated successfully.
Current function value: 0.467233
Iterations 6
Out[31]:
satisfaction -3.769022
evaluation 0.207596
yearsAtCompany 0.170145
int 0.181896
dtype: float64
系数解释
员工离职分数=满意度(-3.769022) + 评价(0.207596)+在职时间*(0.170145)+0.181896
上面的值是分配给每个独立变量的系数。常数0.181896表示所有不可控变量的影响。
# 创造函数计算系数
coef = answer.params
def y (coef, Satisfaction, Evaluation, YearsAtCompany) :
return coef[3] + coef[0]*Satisfaction + coef[1]*Evaluation + coef[2]*YearsAtCompany
import numpy as np
# 0.7满意度、0.8评价、工作三年的员工有14%的几率离职
y1 = y(coef, 0.7, 0.8, 3)
p = np.exp(y1) / (1+np.exp(y1))
p
输出:
0.14431462559738251
关于分数的解释
如果你将员工的特征值带入到等式中:
- 满意度:0.7
- 评价:0.8
- 在职时间:3
你会得到:
员工离职分数=满意度(-3.769022) + 评价(0.207596)+在职时间*(0.170145)+0.181896
结果:这个雇员有14%的机会离开公司。这些信息可以用来作为参考值。
使用逻辑回归的保留计划
通过logistic回归模型,我们现在可以使用这些评分,并通过不同的评分指标对员工进行评估。每个区域都在这里进行了解释:
- 安全区(绿色):这个区域的员工相当安全
- 低离职率区域(黄色):这个区域的员工应该要考虑他们的离职趋势,需要长期观察。
- 中离职率区域(橘色):这个区域的员工有离职风险,应该采取行动和控制。
- 高离职区域(红色):最有可能离职的区域,应该立即采取行动。
按照上述例子,有14%的员工处于安全区
4b.使用其他模型
注意:我会在这一节使用4个其他模型来测试准确度。
这4个模型中(决策树、AdaBoost、逻辑回归、随机森林树),性能最出色的随机森林树。
只要未来与过去看上去没什么不同,机器就能预测未来。
开始评估模型
评估模型有下面几个不同方式:
- 预测准确率: 有多少是正确的?
- 速度: 模型部署的速度有多快?
- 可伸缩性:模型能处理大型数据集吗?
- 健壮性:模型处理离群值/缺失值有多好?
- 可解释性:模型是否易于理解?
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report, precision_score, recall_score, confusion_matrix, precision_recall_curve
from sklearn.preprocessing import RobustScaler
# 创建基准率模型
def base_rate_model(X) :
y = np.zeros(X.shape[0])
return y
创建训练集和测试集
target_name = 'turnover'
X = df.drop('turnover', axis=1)
#robust_scaler = RobustScaler()
#X = robust_scaler.fit_transform(X)
y=df[target_name]
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.15, random_state=123, stratify=y)
检查基准率模型的准确度
y_base_rate = base_rate_model(X_test)
from sklearn.metrics import accuracy_score
print ("Base rate accuracy is %2.2f" % accuracy_score(y_test, y_base_rate))
输出:
Base rate accuracy is 0.76
检查逻辑回归模型的准确率
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(penalty='l2', C=1)
model.fit(X_train, y_train)
print ("Logistic accuracy is %2.2f" % accuracy_score(y_test, model.predict(X_test)))
使用10倍的交叉验证来训练逻辑回归模型
from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
kfold = model_selection.KFold(n_splits=10, random_state=7)
modelCV = LogisticRegression(class_weight = "balanced")
scoring = 'roc_auc'
results = model_selection.cross_val_score(modelCV, X_train, y_train, cv=kfold, scoring=scoring)
print("AUC: %.3f (%.3f)" % (results.mean(), results.std()))
输出:
AUC: 0.793 (0.014)
逻辑回归和随机森林和决策树和AdaBoost
# 比较4个模型
from sklearn.metrics import roc_auc_score
from sklearn.metrics import classification_report
from sklearn.ensemble import RandomForestClassifier
from sklearn import tree
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.ensemble import BaggingClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.ensemble import VotingClassifier
print ("---Base Model---")
base_roc_auc = roc_auc_score(y_test, base_rate_model(X_test))
print ("Base Rate AUC = %2.2f" % base_roc_auc)
print(classification_report(y_test, base_rate_model(X_test)))
# NOTE: By adding in "class_weight = balanced", the Logistic Auc increased by about 10%! This adjusts the threshold value
logis = LogisticRegression(class_weight = "balanced")
logis.fit(X_train, y_train)
print ("\n\n ---Logistic Model---")
logit_roc_auc = roc_auc_score(y_test, logis.predict(X_test))
print ("Logistic AUC = %2.2f" % logit_roc_auc)
print(classification_report(y_test, logis.predict(X_test)))
# Decision Tree Model
dtree = tree.DecisionTreeClassifier(
#max_depth=3,
class_weight="balanced",
min_weight_fraction_leaf=0.01
)
dtree = dtree.fit(X_train,y_train)
print ("\n\n ---Decision Tree Model---")
dt_roc_auc = roc_auc_score(y_test, dtree.predict(X_test))
print ("Decision Tree AUC = %2.2f" % dt_roc_auc)
print(classification_report(y_test, dtree.predict(X_test)))
# Random Forest Model
rf = RandomForestClassifier(
n_estimators=1000,
max_depth=None,
min_samples_split=10,
class_weight="balanced"
#min_weight_fraction_leaf=0.02
)
rf.fit(X_train, y_train)
print ("\n\n ---Random Forest Model---")
rf_roc_auc = roc_auc_score(y_test, rf.predict(X_test))
print ("Random Forest AUC = %2.2f" % rf_roc_auc)
print(classification_report(y_test, rf.predict(X_test)))
# Ada Boost
ada = AdaBoostClassifier(n_estimators=400, learning_rate=0.1)
ada.fit(X_train,y_train)
print ("\n\n ---AdaBoost Model---")
ada_roc_auc = roc_auc_score(y_test, ada.predict(X_test))
print ("AdaBoost AUC = %2.2f" % ada_roc_auc)
print(classification_report(y_test, ada.predict(X_test)))
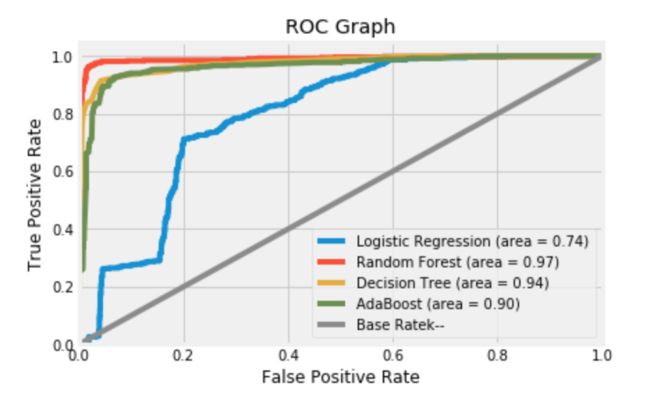
输出:
---Base Model---
Base Rate AUC = 0.50
precision recall f1-score support
0 0.76 1.00 0.86 1714
1 0.00 0.00 0.00 536
avg / total 0.58 0.76 0.66 2250
---Logistic Model---
Logistic AUC = 0.74
precision recall f1-score support
0 0.90 0.76 0.82 1714
1 0.48 0.73 0.58 536
avg / total 0.80 0.75 0.76 2250
---Decision Tree Model---
Decision Tree AUC = 0.94
precision recall f1-score support
0 0.97 0.96 0.97 1714
1 0.87 0.91 0.89 536
avg / total 0.95 0.95 0.95 2250
/opt/conda/lib/python3.6/site-packages/sklearn/metrics/classification.py:1135: UndefinedMetricWarning: Precision and F-score are ill-defined and being set to 0.0 in labels with no predicted samples.
'precision', 'predicted', average, warn_for)
---Random Forest Model---
Random Forest AUC = 0.97
precision recall f1-score support
0 0.99 0.98 0.99 1714
1 0.95 0.96 0.95 536
avg / total 0.98 0.98 0.98 2250
---AdaBoost Model---
AdaBoost AUC = 0.90
precision recall f1-score support
0 0.95 0.97 0.96 1714
1 0.90 0.82 0.86 536
avg / total 0.93 0.94 0.93 2250
ROC图
# Create ROC Graph
from sklearn.metrics import roc_curve
fpr, tpr, thresholds = roc_curve(y_test, logis.predict_proba(X_test)[:,1])
rf_fpr, rf_tpr, rf_thresholds = roc_curve(y_test, rf.predict_proba(X_test)[:,1])
dt_fpr, dt_tpr, dt_thresholds = roc_curve(y_test, dtree.predict_proba(X_test)[:,1])
ada_fpr, ada_tpr, ada_thresholds = roc_curve(y_test, ada.predict_proba(X_test)[:,1])
plt.figure()
# Plot Logistic Regression ROC
plt.plot(fpr, tpr, label='Logistic Regression (area = %0.2f)' % logit_roc_auc)
# Plot Random Forest ROC
plt.plot(rf_fpr, rf_tpr, label='Random Forest (area = %0.2f)' % rf_roc_auc)
# Plot Decision Tree ROC
plt.plot(dt_fpr, dt_tpr, label='Decision Tree (area = %0.2f)' % dt_roc_auc)
# Plot AdaBoost ROC
plt.plot(ada_fpr, ada_tpr, label='AdaBoost (area = %0.2f)' % ada_roc_auc)
# Plot Base Rate ROC
plt.plot([0,1], [0,1],label='Base Rate' 'k--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Graph')
plt.legend(loc="lower right")
plt.show()
5.解释数据
总结:通过上述信息,我们可以得出公司员工可能离职的原因:
- 当他们工作负荷不够时,员工一般会离职(小于150hr/month 或 6hr/day)
- 当过度工作时,员工一般会离职(超过250hr/month 或 10hr/day)
- 高评价或低评价的员工会有高离职意向
- 低薪或中薪的员工占离职员工大多数
- 有2,6 或 7 个项目数的员工有高风险离开公司
- 员工满意度是最能暗示员工离职的因素
- 4-5年工龄的员工应该要考虑其高离职率
- 满意度、工龄、评价是决定离职最重要的三个因素