FAST RCNN ---笔记
fast rcnn
- 摘要
- 模型
-
- 1、总结构
-
- 解读
- 2、区域建议:
-
- 2.1 region proposal的作用:
- 2.2 region proposal 得到过程:
- 3、RoI的工作原理:
-
- 3.1 具体步骤
- 4、fc1和fc2
- 5、其他创新点
这个只是浅读fast rcnn的一点笔记,结构按阅读和思考过程来,可能有些混乱。
摘要
This paper proposes a Fast Region-based Convolutional Network method (Fast R-CNN) for object detection.
本文提出了一种快速基于区域的卷积网络(Fast R-CNN)目标检测方法。
Fast R-CNN builds on previous work to efficiently classify object proposals using deep convolutional networks.
Fast R-CNN基于之前的工作,使用深度卷积网络有效地分类对象候选框。
Compared to previous work, Fast R-CNN employs several innovations to improve training and testing speed while also increasing detection accuracy.
对比之前的工作,fast rcnn 快速的R-CNN采用了几个创新,以提高训练和测试速度,同时也增加了检测精度。
Fast R-CNN trains the very deep VGG16 network 9× faster than R-CNN, is 213× faster at test-time, and achieves a higher mAP on PASCAL VOC 2012. Compared to SPPnet, Fast R-CNN trains VGG16 3×faster, tests 10× faster, and is more accurate.
这里讲述的是速度对比,精确度对比。
Fast R-CNN is implemented in Python and C++ (using Caffe) and is available under the open-source MIT License at https:
//github.com/rbgirshick/fast-rcnn.
总结:
从摘要可以看出fast rcnn的性能对比于rcnn,表现在速度和准确率
模型
1、总结构
 Figure 1. Fast R-CNN architecture. An input image and multiple regions of interest (RoIs) are input into a fully convolutional network.
Figure 1. Fast R-CNN architecture. An input image and multiple regions of interest (RoIs) are input into a fully convolutional network.
输入图像和多个感兴趣区域(roi)输入到全卷积网络中。
Each RoI is pooled into a fixed-size feature map and then mapped to a feature vector by fully connected layers (FCs).
每个RoI被汇集到一个固定大小的特征映射中,然后由完全连接层(FCs)映射到一个特征向量。
The network has two output vectors per RoI: softmax probabilities and per-class bounding-box regression offsets.
这个网络每个RoI有两个输出向量:softmax概率和每类限定框回归偏移量。
The architecture is trained end-to-end with a multi-task loss.
这个结构是端到端的训练,使用的是多任务损失
解读
fast rcnn 模型的结构(输入应该是full image):
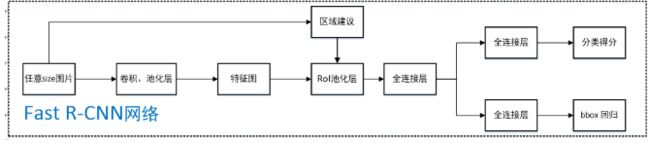
(来自 https://www.jianshu.com/p/fbbb21e1e390)
问题:
1、区域建议怎么来的?
2、RoI 的工作原理?
3、经过fc1得到分类得分,fc2得到ibbox回归,fc1与fc2的区别?
4、所采用的卷积模型是什么?
使用的是VGG模型,第五层的卷积池化层改为RoI
2、区域建议:
2.1 region proposal的作用:
给定一张输入image找出object可能位置的bounding box。这些通常称之为region proposals或者 regions of interest(ROI)。(https://blog.csdn.net/qq_22637925/article/details/79474863)
2.2 region proposal 得到过程:
将图片用选择搜索算法(selective search)得到2000个候选区域(region proposals)的坐标信息。(来自 https://www.jianshu.com/p/fbbb21e1e390)
selective search算法流程
论文selective search(参考https://blog.csdn.net/qq_29695701/article/details/100669687)
在原始图片上进行不同尺度不同大小的滑窗,获取每个可能的位置。尺度从小尺度开始,然后一次次按照相似度合并得到大尺度。每次合并都是计算相邻块之间的相似度。
在相似度计算前,先将图片投射到不同的色彩空间,作者提供了很多色彩空间,可以选一个色彩空间进行。

如何计算?
分为颜色相似度Scolour,纹理相似度Stexture、尺寸相似度Ssize、空间交叠相似度Sfill,得到后计算总相似度:
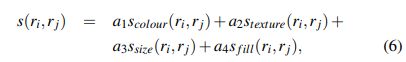
a i a_i ai属于{0,1} ,自己设定,看需要用哪一种相似度计算。(As we aim to diversify our strategies, we do not consider any weighted similarities.)表示什么意思?
1 )颜色相似度
将色彩空间转为某个色彩空间,分割为m个区域。假设通道数为3,每个通道分为25个bin,那么 C i = c i 1 , c i 2 , c i 3 , . . . , c i n C_i = {c^1_i , c^2_i , c^3_i , ... , c^n_i} Ci=ci1,ci2,ci3,...,cin n=25*3。一个 C i C_i Ci就是一个区域 r i r_i ri的直方图向量。并且 C i C_i Ci 是用区域的 L 1 L_1 L1 范数归一化后的向量
计算相似度,得到两个区域 c i n c^n_i cin值,取小的那一个,从n=1加到n=75。公式如下:
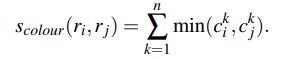
两个直方图合并的公式如下:
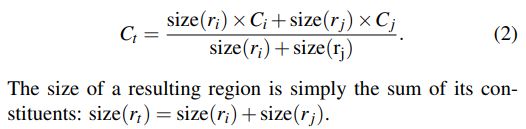
2 )纹理相似度
对每一个颜色通道,在8个方向上提取高斯导数(σ = 1)。(是一维还是二维? )得到结果,分为10个bin, T i = t i 1 , t i 2 , t i 3 , . . . , t i n T_i = {t^1_i , t^2_i , t^3_i , ... , t^n_i} Ti=ti1,ti2,ti3,...,tin n=8103。 T i T_i Ti 是用区域的 L 1 L_1 L1 范数归一化后的向量。相似度计算方式与上面相似:

两个直方图合并方法与颜色相似度一样。
3 )尺度相似度
优先合并小的区域。
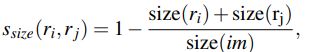
其中size(im)是整张图片的像素级的尺寸。
4 )空间交叠相似度
用于优先合并被包含进其他区域的区域。
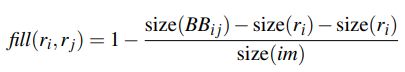
其中 B B i j BB_ij BBij是能够框住 r i r_i ri和 r j r_j rj的最小矩形框。
3、RoI的工作原理:
3.1 具体步骤
(参考 https://blog.csdn.net/u011436429/article/details/80279536):
根据输入image,将region proposal 映射到feature map对应位置;
将映射后的区域划分为相同大小的sections(sections数量与输出的维度相同);
对每个sections进行max pooling操作;
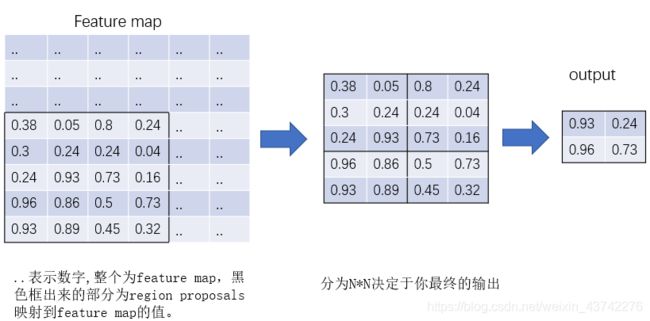
问题:如何映射?
设 feature map大小为:[batch, fx, fy, fc] ,region proposals的box为:[x1,y1,x2,y2] , stride=32 —> 映射的区域:[x1/32,y1/32,x2/32,y2/32] 。 (x1/32,y1/32)为左上角坐标,(x2/32,y2/32)为右下角坐标。如果x1/32有小数,直接取整。
4、fc1和fc2
可以看出主要的区别就在于loss的计算,以及对于分类来说,要计算softmax

(参考链接:https://www.jianshu.com/p/fbbb21e1e390)
问题:
1、进入cls_score和bbox_predict两个子层的数据是一样的吗?
进入cls_score和bbox_predict的数据就是feature,是一样的
2、loss的计算

(来自:https://www.jianshu.com/p/fbbb21e1e390)
5、其他创新点
1、将SVD用于全连接层