算法了解:RCNN、SPP-Net、Fast-RCNN、Faster-RCNN
强烈推荐视频:
非常严谨,非常美观,非常清楚(重点和细节全讲了,观看人数多,有指正)。
RCNN理论合集:https://www.bilibili.com/video/BV1af4y1m7iL?from=search&seid=4520391483531272743
(包括RCNN系列、YOLO系列、以及源码讲解,非常精良成体系)
1 RCNN(2014年)
1.1 发明背景
2012年AlexNet在ImageNet举办的ILSVRC中大放异彩,R-CNN作者受此启发,尝试将AlexNet在图像分类上的能力迁移到PASCAL VOC(1万图像,20类,标定类别和位置)的目标检测上。这就要解决两个问题:
- 如何利用卷积网络去目标定位
- 如何在小规模的数据集上训练出较好的网络模型。
1.2 解决思路
针对问题1,R-CNN利用候选区域的方法(Region Proposal),这也是该网络被称为R-CNN的原因:Regions with CNN features。
针对问题2,R-CNN使用了微调的方法,利用AlexNet在ImageNet上预训练好的模型。
训练总思路
- 生成候选区:一张图片生成1000~2000个候选区域(Region Proposal)。
- CNN特征提取:对每个候选区域,输入到预训练好的AlexNet中,提取一个固定长度(4096)的特征向量。
- 分类器(类别):对每个目标(类别)训练一SVM分类器,识别该区域是否包含目标。
- 回归器(位置):训练一个线性回归模型判断当前框是不是很完美,修正候选区域中目标的位置。
疑问:为什么用SVM分类而不使用CNN全连接之后的softmax直接把分类做了?
原因:主要是基于CNN阶段和SVM阶段对正样本的IOU阈值标准需要不一样,单独再训练SVM去分类,对正样本IOU阈值可以定的更高,从而带来分类精度提升。见知乎:https://www.zhihu.com/question/54117650
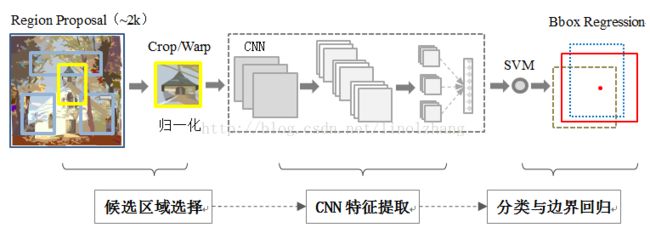
R-CNN的目标检测过程:
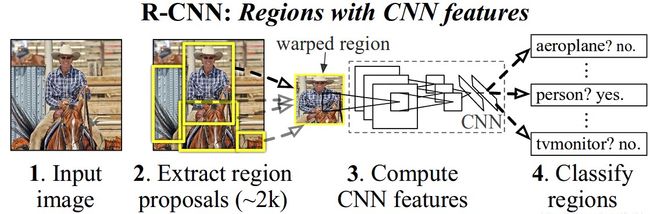
1)候选区域选择
用什么方法提取框:Region Proposal是一类传统的区域提取方法,可以看作不同宽高的滑动窗口,通过窗口滑动获得潜在的目标图像。
提取多少个框:具体是使用了Selective Search方法从一张图像生成约2000-3000个候选区域。
提取框后干什么:根据Proposal提取的目标图像进行归一化,作为CNN的标准输入。
2)CNN特征提取
对生成的2000个候选区域,使用预训练好的AlexNet网络进行特征提取。
- 输入:候选框输入尺寸227×227,归一化。
- 网络结构:改造预训练好的AlexNet网络(5个卷积层,2个全连接层),将其最后的全连接层去掉,并将类别设置为21(20个目标类别,另外一个类别代表背景).
- 输出:得到一个4096×21的特征。
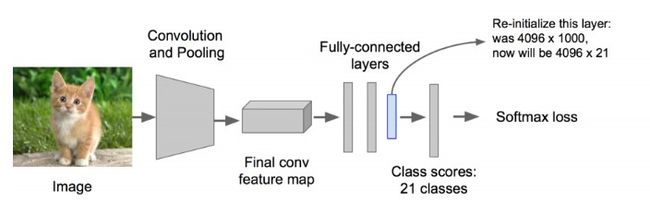
3)SVM分类器
利用上面提取到的候选区域的特征向量,通过SVM分类器来判断是哪个目标类别。而SVM是一种典型的两类分类器,即它只回答属于正类还是负类的问题。SVM多分类有两种方式,这里作者使用的是:有多少个目标类,就单独训练多少个SVM分类器。
比如,下图针对狗的SVM分类器:
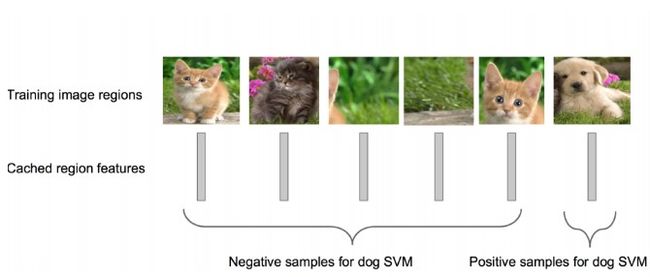
狗的SVM分类器,就要能判断出某个候选区域是不是包含狗,包含狗了那就是Positive;不包含就是Negative.
对于候选区域只是框出来了某个类的一部分图像问题,在R-CNN中,设定一个0.3的IOU阈值,如果该区域与Ground truth的IOU低于该阈值,就将给区域设置为Negative。
4)边界框回归
主要参考:https://blog.csdn.net/zijin0802034/article/details/77685438
边界框回归怎么做的?
对于窗口一般使用四维向量(x,y,w,h)来表示, 分别表示窗口的中心点坐标和宽高。 对于下图2,红色的框 P 代表原始的Proposal, 绿色的框 G 代表目标的 Ground Truth, 我们的目标是寻找一种关系使得输入原始的窗口 P 经过映射得到一个跟真实窗口 G 更接近的回归窗口G^。
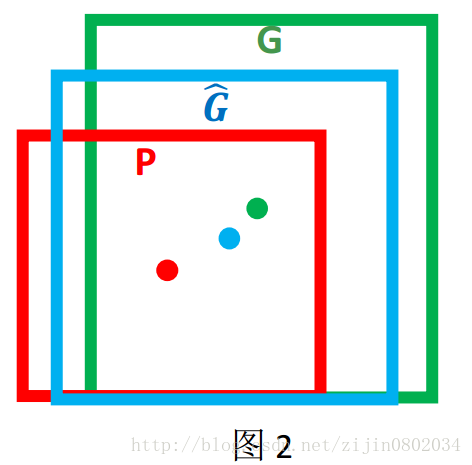
边框回归的目的既是:给定(Px,Py,Pw,Ph)寻找一种映射ff, 使得f(Px,Py,Pw,Ph) = (Gx^,Gy^,Gw^,Gh^) 并且(Gx^,Gy^,Gw^,Gh^) ≈ (Gx,Gy,Gw,Gh)。
具体算法见参考文献,大概意思如下:
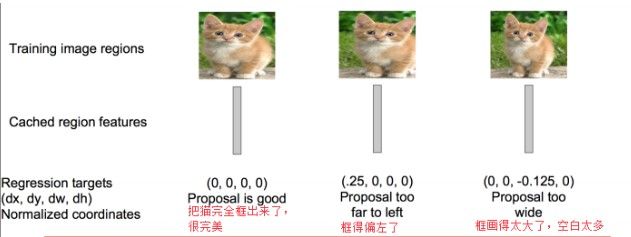
测试
从一张图片中提取2000个候选区域,将每个区域按照训练时候的方式进行处理,输入到SVM中进行正负样本的识别,并使用候选框回归器,计算出每个候选区域的分数。针对每个类,通过计算IOU,采取非最大值抑制的方法,以最高分的区域为基础,删掉重叠的区域。
1.3 意义
RCNN作为第一篇目标检测领域的深度学习文章,大幅提升了目标检测的识别精度,在PASCAL VOC2012数据集上将mAP从35.1%提升至53.7%。使得CNN在目标检测领域成为常态,也使得大家开始探索CNN在其他计算机视觉领域的巨大潜力。
1.4 不足
- 对每个新图像进行预测需要大约40-50秒。
- 训练分为多个步骤,比较繁琐:① 需要微调CNN网络提取特征,②需要训练SVM进行正负样本分类,③训练边框回归器得到正确的预测位置。
- 训练耗时,中间要保持候选区域的特征,5000张的图片会生成几百G的特征文件。
- 每一个ProposalRegion都需要进入CNN网络计算,上千个Region存在大量的范围重叠,重复的特征提取带来巨大的计算浪费。
2 SPP-Net(ECCV 2014)
何凯明等发明。
智者善于提出疑问,既然CNN的特征提取过程如此耗时(大量的卷积计算),为什么要对每一个候选区域独立计算,而不是先提取图像的整体特征,然后仅在分类之前做一次Region截取呢?立即付诸实践,于是SPP-Net诞生了。
SPP-Net整个过程:
-
首先通过选择性搜索,对待检测的图片进行搜索出2000个候选窗口。这一步和R-CNN一样。
-
特征提取阶段。这一步就是和R-CNN最大的区别了,这一步骤的具体操作如下:把整张待检测的图片,输入CNN中,进行一次性特征提取,得到feature maps,然后在feature maps中找到各个候选框的区域,再对各个候选框采用金字塔空间池化,提取出固定长度的特征向量。而R-CNN输入的是每个候选框,然后在进入CNN,因为SPP-Net只需要一次对整张图片进行特征提取,速度会大大提升。
-
最后一步也是和R-CNN一样,采用SVM算法进行特征向量分类识别。
2.1 SPP-Net网络
RCNN过程:
SPP-Net过程:
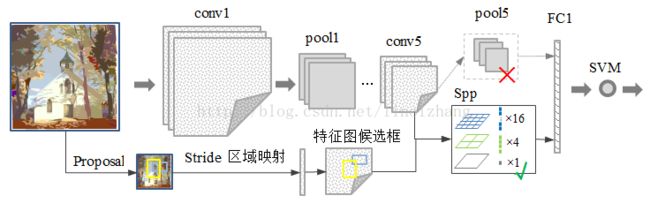
SPP-net与R-CNN的对比:RCNN输入原图像的proposal,SPP-Net输入特征的proposal.

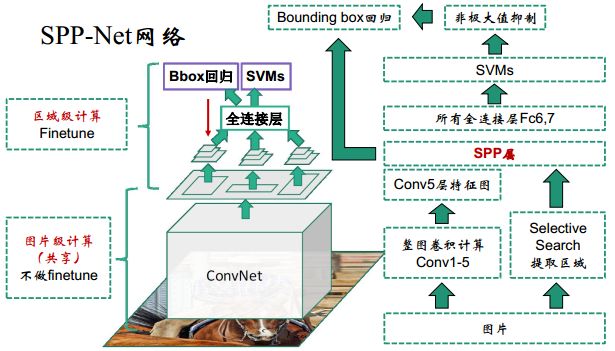
2.2 SPP-Net 主要改进点
SPP-Net在RCNN的基础上做了实质性的改进:
- 1)取消了crop/warp图像归一化过程,解决图像变形导致的信息丢失以及存储问题;
- 2)采用空间金字塔池化(SpatialPyramid Pooling )替换了 全连接层之前的最后一个池化层。
为了适应不同分辨率的特征图,定义一种可伸缩的池化层,不管输入分辨率是多大,都可以划分成m*n个部分。这是SPP-net的第一个显著特征,它的输入是conv5特征图 以及特征图候选框(原图候选框 通过stride映射得到),输出是固定尺寸(m*n)特征;
还有金字塔呢?通过多尺度增加所提取特征的鲁棒性,这并不关键,在后面的Fast-RCNN改进中该特征已经被舍弃;
最关键的是SPP的位置,它放在所有的卷积层之后,有效解决了卷积层的重复计算问题(测试速度提高了24~102倍),这是论文的核心贡献。
2.3 SPP-Net不足
- 1)和RCNN一样,训练过程仍然是隔离的,提取候选框 | 计算CNN特征| SVM分类 | Bounding Box回归独立训练,大量的中间结果需要转存,无法整体训练参数;
- 2)SPP-Net在无法同时Tuning在SPP-Layer两边的卷积层和全连接层,很大程度上限制了深度CNN的效果;
- 3)在整个过程中,Proposal Region仍然很耗时。
3 Fast-RCNN(2015)
RCNN原作者Ross Girshick2015年推出。
Fast-RCNN主要贡献在于对RCNN进行加速:训练时间从84小时减少为9.5小时,测试时间从47秒减少为0.32秒。
创新点:
- 借鉴SPP思路,提出简化版的ROI池化层(注意,没用金字塔),同时加入了候选框映射功能,使得网络能够反向传播,解决了SPP的整体网络训练问题,模型训练时可对所有层进行更新;
- 多任务Loss层
- SoftmaxLoss代替了SVM,证明了softmax比SVM更好的效果;(为什么不使用SVM了:训练使用难样本挖掘以使网络获得高判别力,从而精准定位目标)
- SmoothL1Loss取代Bouding box回归
将分类和边框回归进行合并(又一个开创性的思路),通过多任务Loss层进一步整合深度网络,统一了训练过程,从而提高了算法准确度。
网络结构
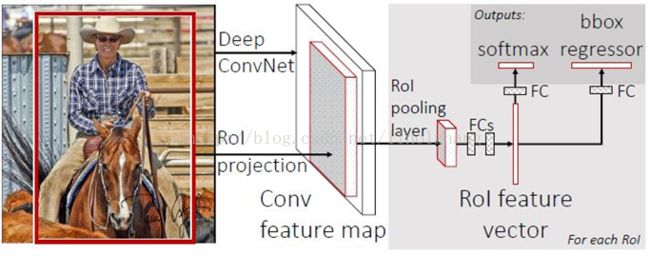
4 Faster R-CNN(2015)
作者:任少卿、何凯明、Ross Girshick, 孙剑
在Fast R-CNN中使用的目标检测识别网络,在速度和精度上都有了不错的结果。不足的是,其候选区域提取方法耗时较长,而且和目标检测网络是分离的,并不是end-to-end的。在Faster R-CNN中提出了区域检测网络(Region Proposal Network,RPN),将候选区域的提取和Fast R-CNN中的目标检测网络融合到一起,这样可以在同一个网络中实现目标检测。
Faster R-CNN的网络有4部分组成:
- Conv Layers 一组基础的CNN层,由Conv + Relu + Pooling组成,用于提取输入图像的Feature Map。通常可以选择有5个卷积层的ZF网络或者有13个卷积层的VGG16。Conv Layers提取的Feature Map用于RNP网络生成候选区域以及用于分类和边框回归的全连接层。
- RPN,区域检测网络 输入的是前面卷积层提取的Feature Map,输出为一系列的候选区域。
- RoI池化层 输入的是卷积层提取的Feature Map 和 RPN生成的候选区域RoI,其作用是将Feature Map 中每一个RoI对应的区域转为为固定大小的H×WH×W的特征图,输入到后面的分类和边框回归的全连接层。
- 分类和边框回归修正 输入的是RoI池化后RoI的H×WH×W的特征图,通过SoftMax判断每个RoI的类别,并对边框进行修正。
其整个工作流程如下:
- 将样本图像整个输入到Conv Layers中,最后得到Feature Map。
- 将该Feature Map输入到RPN网络中,提取到一系列的候选区域
- 然后由RoI池化层提取每个候选区域的特征图
- 将候选区域的特征图输入到用于分类的Softmax层以及用于边框回归全连接层。
网络结构细节
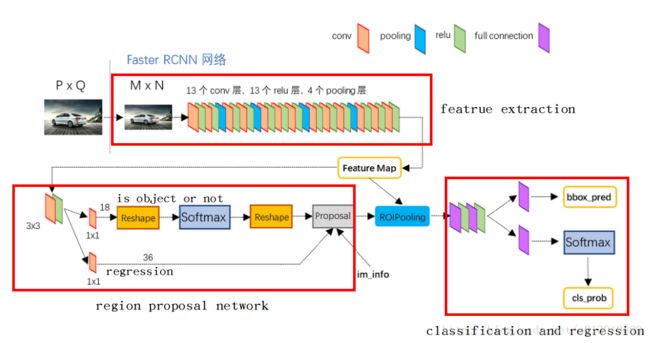
下面这张图的目的是为了显示训练是分阶段的,即像之前的方法一样,先产生建议框,然后拿建议框去分类,只不过这里建议框的生成方式换成了RPN网络。
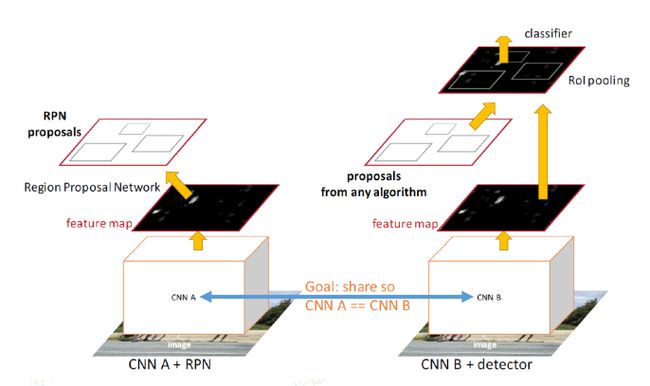
-
之前的Fast R-CNN存在的问题:存在瓶颈:选择性搜索,找出所有的候选框,这个也非常耗时。 解决方法:加入一个提取边缘的神经网络,也就说找到候选框的工作也交给神经网络来做了,即Region Proposal Network(RPN)。
-
Faster R-CNN解决的是,“为什么还要用selective search呢?”----将选择性搜索候选框的方法换成Region Proposal Network(RPN)。
RPN(里程碑式的贡献)
-
RPN的最终结果是用CNN来生成候选窗口,通过得分排序等方式挑出量少质优的框(~300)
-
让生成候选窗口的CNN和分类的CNN共享卷积层
其实RPN最终就是在原图尺度上,设置了密密麻麻的候选Anchor。然后用cnn去判断哪些Anchor是里面有目标的foreground anchor,哪些是没目标的backgroud。所以,仅仅是个二分类而已!)
RPN网络的特点在于通过滑动窗口的方式实现候选框的提取,每个滑动窗口位置生成9个候选窗口(不同尺度、不同宽高),提取对应9个候选窗口(anchor)的特征,用于目标分类和边框回归,与FastRCNN类似。
目标分类只需要区分候选框内特征为前景或者背景。
边框回归确定更精确的目标位置,基本网络结构如下图所示:
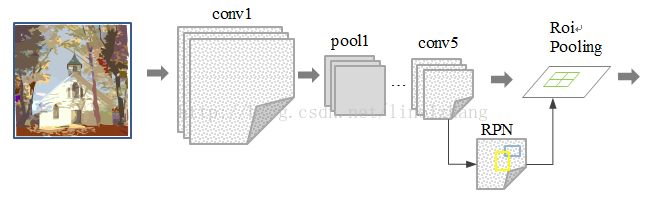
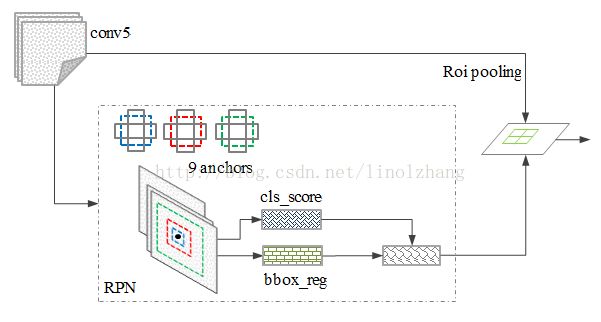
训练过程中,涉及到的候选框选取,选取依据:
- 丢弃跨越边界的anchor;
- 与样本重叠区域大于0.7的anchor标记为前景,重叠区域小于0.3的标定为背景
对于每一个位置,通过两个全连接层(目标分类+边框回归)对每个候选框(anchor)进行判断,并且结合概率值进行舍弃(仅保留约300个anchor), 没有显式地提取任何候选窗口 ,完全使用网络自身完成判断和修正。
从模型训练的角度来看,通过使用共享特征交替训练的方式,达到接近实时的性能,交替训练方式描述为:
- 根据现有网络初始化权值w,训练RPN;
- 用RPN提取训练集上的候选区域,用候选区域训练FastRCNN,更新权值w;
- 重复1、2,直到收敛。
5 总结
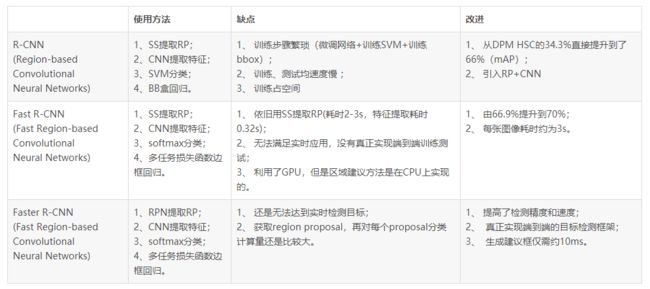
RCNN网络的演进:
RCNN网络的速度和精度:

主要参考:
RCNN到Faster R-CNN笔记 https://www.jianshu.com/p/4064de5499d5
RCNN介绍 https://blog.csdn.net/xyfengbo/article/details/70227173?utm_medium=distribute.pc_relevant.none-task-blog-title-2&spm=1001.2101.3001.4242
目标检测之R-CNN系列 https://www.cnblogs.com/wangguchangqing/p/10384058.html