爬取酷狗音乐
爬取酷狗音乐
-
- 分析问题
- 解决问题
- js逆向
- 代码实现
- 总结
分析问题
1.酷狗音乐的地址保存在https://wwwapi.kugou.com/yy/index.php? 这个地址返回的数据中
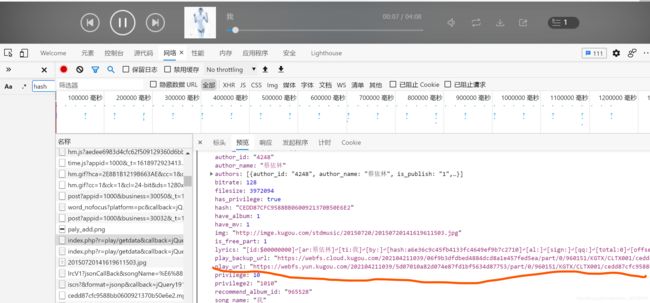
请求这个地址的参数
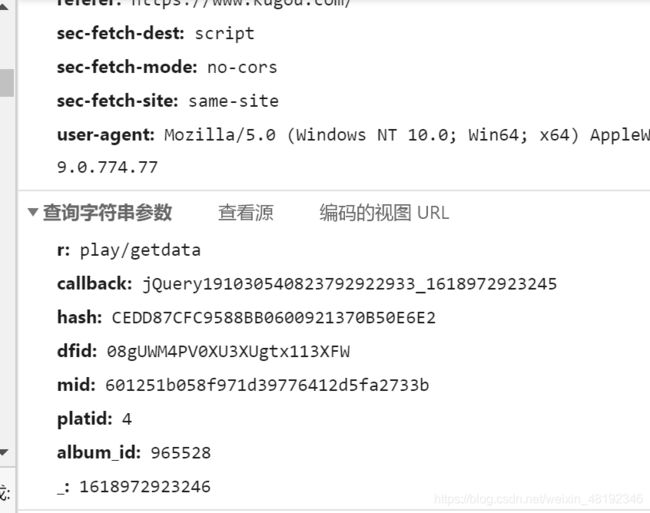
2.参数
r: play/getdata
callback: jQuery191030540823792922933_1618972923245
hash: CEDD87CFC9588BB0600921370B50E6E2
dfid: 08gUWM4PV0XU3XUgtx113XFW
mid: 601251b058f971d39776412d5fa2733b
platid: 4
album_id: 965528
_: 1618972923246
经过反复的请求,发现
r:不会改变
callback: 这个参数会改变,但需要删除,不会影响
hash: 随着每首歌而改变
dfid:固定不变,与每台电脑有关
mid: 固定不变,与每台电脑有关
platid: 不会改变
album_id: 随着每首歌而改变,对应的每首歌有关
_: 跟时间有关
因此需要获取的参数是'_','album_id','hash'
解决问题
经过不断的调试,发现hash,album_id参数来自song地址返回数据中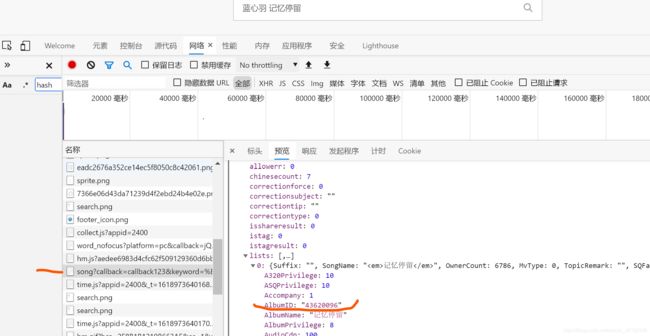

所以我们要请求这个地址

这个地址携带的参数
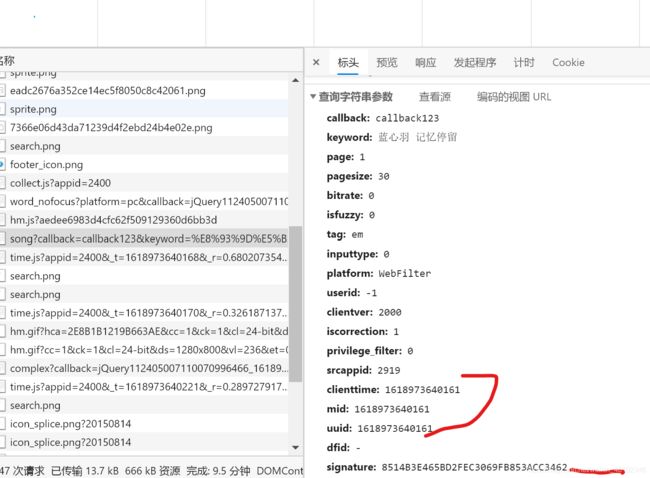
其中clienttime,mid,uuid是当前时间
signature参数是经过md5加密处理,
同时发现可以通过js逆向来分析signature生成

js逆向
signature = faultylabs.MD5(o.join("")),
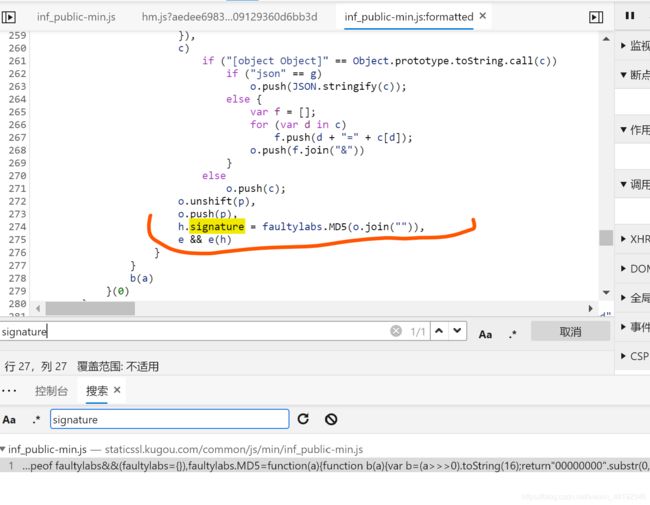
打断点
发现signature是由faultylabs.MD5函数生成

进入函数中,这是md5加密的函数
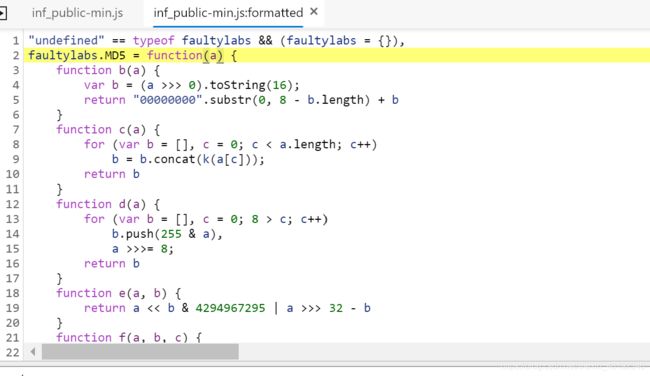
同时传入函数的参数是json字符串

代码实现
import time
import execjs
import requests
import re
# 将js函数从网页中保存下来,并通过调用execjs模块生成signature
def fun(word): #word参数是json格式
with open("test.js", "r", encoding='utf-8') as f:
js_str = f.read()
# 通过js文件中逻辑数据,对文件进行加密
if js_str:
js_obj = execjs.compile(js_str)
return js_obj.call('faultylabs.MD5', word)
def get_id():
url = 'https://complexsearch.kugou.com/v2/search/song?'
keyword = input('请输入需要下载的歌')
# 这是传入js函数参数的一部分
key_code = "NVPh5oo715z5DIWAeQlhMDsWXXQV4hwtbitrate=0callback=callback123clienttime={time}clientver=2000dfid=-inputtype=0iscorrection=1isfuzzy=0keyword={keyword}mid={time}page=1pagesize=30platform=WebFilterprivilege_filter=0srcappid=2919tag=emuserid=-1uuid={time}NVPh5oo715z5DIWAeQlhMDsWXXQV4hwt"
p = key_code.format(time=millis, keyword=keyword) # js函数中的参数
ws = fun(p)
data = {
'callback': 'callback123',
'keyword': keyword,
'page': 1,
'pagesize': 30,
'bitrate': 0,
'isfuzzy': 0,
'tag': 'em',
'inputtype': 0,
'platform': 'WebFilter',
'userid': -1,
'clientver': 2000,
'iscorrection': 1,
'privilege_filter': 0,
'srcappid': 2919,
'clienttime': millis,
'mid': millis,
'uuid': millis,
'dfid': '-',
'signature': ws
}
wood=requests.get(url=url,headers=headers,params=data)
a=r'"AlbumID":"(.*?)"'
c=r'"FileHash":"(.*?)"'
t=r'"FileName":"(.*?)"'
wa=re.findall(a,wood.text) #歌手与歌名
wt=re.findall(t,wood.text) #id
hash_=re.findall(c,wood.text)#hash
print(hash_)
# print(wood.text)
# print(len(hash_))
item={
}
for li in range(len(wa)):
print(wt[li].replace('<\\/em>','').replace('',''),wa[li],hash_[li])
# 获得13位时间戳
millis = str(round(time.time() * 1000))
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.128 Safari/537.36'
}
get_id()
结果
发现有些歌的id没有,对这些歌请求,发现请求参数中没有id
总结
爬取酷狗音乐分为两步
第一步在搜索页面中获取hash,id等参数
第二步在播放页面中,请求获取歌的url地址
感谢沐沐沐沐朝阳