Python计算机视觉——局部图像描述子(作业二)
第二章 局部图像描述子
- 序言
- 一、Harris角点检测
-
- 1.1 Harris 角点检测基本原理
-
- 1.1.1 数学公式
- 1.1.2 python代码实现
- 1.2 在图像中寻找对应点
-
- 1.2.1 python代码实现
- 二、SIFT(尺度不变特征变换)
-
- 2.1 兴趣点
- 2.2 描述子
- 2.3 检测兴趣点
- 2.4 匹配描述子
- 2.5 代码实现
- 三、匹配地理标记图像
-
- 3.1 可视化连接的图像
-
- 3.1.1 代码实现
序言
图像匹配,通过对影像内容、特征、结构、关系、纹理及灰度等的对应关系,相似性和一致性的分析,寻求相似影像目标的方法。图像的同名点匹配,是图像拼接、三维重建、相机标定等应用的关键步骤。
那么我们如何进行同名点匹配呢???
这时候就需要进行图像的特征匹配:根据准则,提取图像中的特征点;然后提取特征点周围的图像块,构造特征描述符;通过特征描述符的对比,实验特征匹配。
特征点必须具有不变性,比如:
- 几何不变性:位移、旋转、尺度…
- 光度不变性:光照、曝光…
为此,我们学习 Harris 角点检测算法,用于提取图像的特征点;学习 SIFT(尺度不变特征转换),用于解决图像缩放、旋转、曝光、噪声等因素对特征匹配的影响。
运行环境:
- python3.8
- PyCharm2020.3
一、Harris角点检测
1.1 Harris 角点检测基本原理
Harris 角点检测算法(也称 Harris & Stephens 角点检测器)是一个极为简单的角点检测算法。该算法的主要思想是:如果像素周围存在多于一个方向的边——即窗口沿任意方向的移动都导致图像灰度的明显变化,我们认为该点为兴趣点。该点就是角点。
角点:
1. 局部窗口沿各方向移动,均产生明显变化的点
2. 图像局部曲率突变的点
如果是平坦区域:任意方向移动,无灰度变化;如果是边缘区域:沿边缘方向移动,无灰度变化;如果是角点:艳任意方向移动,明显灰度变化.
1.1.1 数学公式
将图像域中点x上的对称半正定矩阵MI=MI(x)定义为: M I = ∇ I ∇ I T = [ I x I y ] [ I x I y ] = [ I x 2 I x I y I x I y I y 2 ] M_I=\nabla I\nabla I^T=\begin{bmatrix}I_x \\ I_y\end{bmatrix}\begin{bmatrix}I_x & I_y\end{bmatrix}=\begin{bmatrix}I_x^2 & I_xI_y \\ I_xI_y & I_y^2\end{bmatrix} MI=∇I∇IT=[IxIy][IxIy]=[Ix2IxIyIxIyIy2] 其中∇I为包含导数Ix和Iy的图像梯度。由于该定义,MI的秩为1,特征值为λ1=|∇I|2和λ2=0。现在对于图像的每个像素,可以计算出该矩阵。
选择权重矩阵W(通常为高斯滤波器Gσ),我们可以得到卷积: M ‾ I = W ∗ M I \overline{M}_I=W*M_I MI=W∗MI 该卷积的目的是得到MI在周围像素上的局部平均。计算出的矩阵MI有称为Harris矩阵。W的宽度决定了在像素x周围的感兴趣区域。像这样在区域附近对矩阵MI取平均的原因是,特征值会依赖于局部图像特性而变化。如果图像梯度在该区域变化,那么MI的第二个特征值将不再为0.如果图像的梯度没有变换,MI的特征值也不会变化。
取决于该区域∇I的值,Harris矩阵MI的特征值有三种情况:
- 如果λ1和λ2都是很大的正数,则该x点为角点;
- 如果λ1很大,λ2≈0,则该区域内存在一个边,该区域内的平均MI的特征值不会变化太大;
- 如果λ1≈λ2≈0,则该区域为空。
在不需要实际计算特征值的情况下,为了把重要的情况和其他情况分开,Harris和Stephens在文献中引入了指示函数: d e t ( M ‾ I ) − κ t r a c e ( M ‾ I ) 2 det(\overline{M}_I)-\kappa trace(\overline{M}_I)^2 det(MI)−κtrace(MI)2 为了去除加权常数κ,我们通常使用商数: d e t ( M ‾ I ) t r a c e ( M ‾ I ) 2 \frac{det(\overline{M}_I)}{trace(\overline{M}_I)^2} trace(MI)2det(MI) d e t ( M ‾ I ) = λ 1 λ 2 det(\overline{M}_I)=λ_1λ_2 det(MI)=λ1λ2 t r a c e ( M ‾ I ) = λ 1 + λ 2 trace(\overline{M}_I)=λ_1+λ_2 trace(MI)=λ1+λ2 作为指示器。
1.1.2 python代码实现
compute_harris_response() 函数会返回像素值为Harris响应函数值的一幅图像。我们需要从这幅图像中挑选需要的信息。然后,选取像素值高于阈值的所有图像点;在加上额外的限制,即角点之间的间隔必须大于设定的最小距离。这种方法会产生很好的角点检测结果。为了实现该算法,我们获取所有候选像素点,以角点响应值递减的顺序排序,然后将距离已标记为角点位置过近的区域从候选像素点中删除,就是 get_harris_points() 函数。
# 局部图像描述子
# Harris角点检测
from pylab import *
from PIL import Image
from numpy import *
from scipy.ndimage import filters
def compute_harris_response(im, sigma=3):
"""在一幅灰度图像中,对每个像素计算Harris角点检测器响应函数"""
# 计算导数
imx = zeros(im.shape)
filters.gaussian_filter(im, (sigma, sigma), (0, 1), imx)
imy = zeros(im.shape)
filters.gaussian_filter(im, (sigma, sigma), (1, 0), imy)
# 计算Harris矩阵的分量
Wxx = filters.gaussian_filter(imx * imx, sigma)
Wxy = filters.gaussian_filter(imx * imy, sigma)
Wyy = filters.gaussian_filter(imy * imy, sigma)
# 计算特征值和迹
Wdet = Wxx * Wyy - Wxy ** 2
Wtr = Wxx + Wyy
return Wdet / Wtr
def get_harris_points(harrisim, min_dist=10, threshold=0.1):
"""从一幅Harris响应图像中返回角点。min_dist为分割角点和图像边界的最小像素数目"""
# 寻找高于阈值的候选角点
corner_threshold = harrisim.max() * threshold
harrisim_t = (harrisim > corner_threshold) * 1
# 得到候选点的坐标
coords = array(harrisim_t.nonzero()).T
# 以及它们的Harris响应值
candidate_values = [harrisim[c[0], c[1]] for c in coords]
# 对候选点按照Harris响应值进行排序
index = argsort(candidate_values)
# 将可行点的位置保存到数组中
allowed_locations = zeros(harrisim.shape)
allowed_locations[min_dist:-min_dist, min_dist:-min_dist] = 1
# 按照min_distance原则,选择最佳Harris点
filtered_coords = []
for i in index:
if allowed_locations[coords[i, 0], coords[i, 1]] == 1:
filtered_coords.append(coords[i])
allowed_locations[(coords[i, 0] - min_dist):(coords[i, 0] + min_dist),
(coords[i, 1] - min_dist):(coords[i, 1] + min_dist)] = 0
return filtered_coords
def plot_harris_points(image,filtered_coords):
"""绘制图像中检测到的角点"""
figure()
gray()
imshow(image)
plot([p[1] for p in filtered_coords],[p[0] for p in filtered_coords],'*')
axis('off')
show()
# 调用展示
im = array(Image.open('../image/imag3.jpg').convert('L'))
harrisim = compute_harris_response(im)
filtered_coords = get_harris_points(harrisim, 6, 0.1)
plot_harris_points(im, filtered_coords)
运行结果:
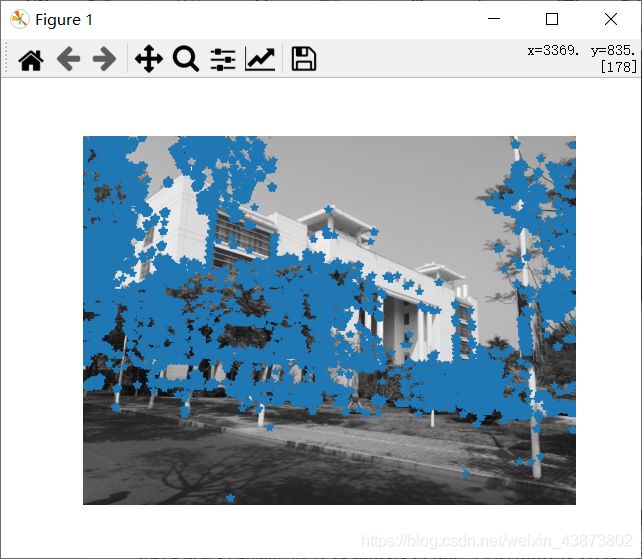 |
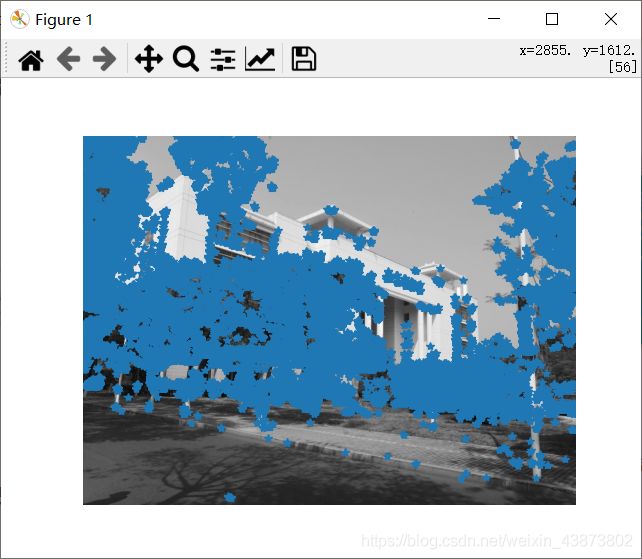 |
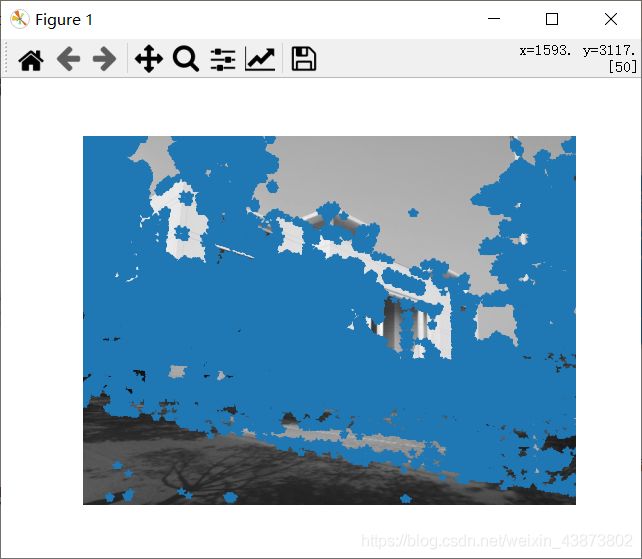 |
|---|
分析:
运行结果从左到有分别是使用阈值(threshold)为 0.1、0.05、0.01检测出的角点。可以看出,在进行角点检测时,随着阈值的降低,能被检测到的角点相应的会增加。
1.2 在图像中寻找对应点
Harris角点检测器仅仅能够检测出图像中的兴趣点,但没有给出通过比较图像间的兴趣点来寻找匹配角点的方法。我们需要在每个点上加入描述子信息,并给出一个比较这些描述子的方法。
兴趣点描述子是分配给兴趣点的一个向量,描述该点附近的图像的表现信息。描述子越好,寻找到的对应点越好。我们用对应点或者点的对应来描述相同物体和场景点在不同图像上形成的像素点。
Harris角点的描述子通常是由周围图像像素块的灰度值,以及用于比较的归一化互相关矩阵构成的。图像的像素块由以该像素点为中心的周围矩形部分图像构成。
通常,两个(相同大小)像素块I1(x)和I2(x)的相关矩阵定义为: c ( I 1 , I 2 ) = ∑ X f ( I 1 ( x ) , I 2 ( x ) ) c(I_1,I_2)=\sum_Xf(I_1(x),I_2(x)) c(I1,I2)=X∑f(I1(x),I2(x)) 其中,函数f随着相关方法的变化而变化。上式取像素块中所有像素位置x的和。对于互相关矩阵,函数f(I1,I2)=I1I2,因此,c(I1,I2)=I1·I2,其中·表示向量乘法。c(I1,I2)的值越大,像素块I1和I2的相似度越高。
归一化的互相关矩阵是互相关矩阵的一种变形,可以定义为: n c c ( I 1 , I 2 ) = 1 n − 1 ∑ x ( I 1 ( x ) − μ 1 ) σ 1 ⋅ ( I 2 ( x ) − μ 2 ) σ 2 ncc(I_1,I_2)=\frac{1}{n-1}\sum_x\frac{(I_1(x)-\mu_1)}{\sigma_1}\cdot \frac{(I_2(x)-\mu_2)}{\sigma_2} ncc(I1,I2)=n−11x∑σ1(I1(x)−μ1)⋅σ2(I2(x)−μ2) 其中,n为像素块中像素的数目,μ1和μ2表示每个像素块中平均像素值强度,σ1和σ2分别表示每个像素块中的标准差。通过减去均值和除以标准差,该方法对图像亮度变化具有稳健性。
1.2.1 python代码实现
get_descriptors 函数的参数为奇数大小长度的方形灰度图像块,该图像块的中心为处理的像素点。该函数将图像块像素值压平成一个向量,然后添加到描述子列表中。
def get_descriptors(image, filtered_coords, wid=5):
"""对于每个返回的点,返回点周围2*wid+1个像素的值(假设选取点的min_distance > wid)"""
desc = []
for coords in filtered_coords:
patch = image[coords[0] - wid:coords[0] + wid + 1,
coords[1] - wid:coords[1] + wid + 1].flatten()
desc.append(patch)
return desc
match 函数使用归一化的互相关矩阵,将每个描述子匹配到另一个图像中的最优候选点。由于数值较高的距离代表两个点能够更好的匹配,所以在排序之前,我们对距离取相反数。
def match(desc1, desc2, threshold=0.5):
"""对于第一幅图像中的每个角点描述子,使用归一化互相关,选取它在第二幅图像中的匹配角点"""
n = len(desc1[0])
# 点对的距离
d = -ones((len(desc1), len(desc2)))
for i in range(len(desc1)):
for j in range(len(desc2)):
d1 = (desc1[i] - mean(desc1[i])) / std(desc1[i])
d2 = (desc2[j] - mean(desc2[j])) / std(desc2[j])
ncc_value = sum(d1 * d2) / (n - 1)
if ncc_value > threshold:
d[i, j] = ncc_value
ndx = argsort(-d)
matchscores = ndx[:, 0]
return matchscores
match_twosided 函数是为了获得更稳定的匹配,我们从第二幅图像向第一幅图像匹配,然后过滤掉在两种方法中都不是最好的匹配。
def match_twosided(desc1, desc2, threshold=0.5):
"""两边对称版本的match()"""
matches_12 = match(desc1, desc2, threshold)
matches_21 = match(desc2, desc1, threshold)
ndx_12 = where(matches_12 >= 0)[0]
# 去除非对称的匹配
for n in ndx_12:
if matches_21[matches_12[n]] != n:
matches_12[n] = -1
return matches_12
些匹配可以通过在两边分别绘制出图像,使用线段连接匹配的像素点来直观的可视化。下面代码可以实现匹配点的可视化。
def appendimages(im1, im2):
"""返回将两幅图像并排拼接成的一幅新图像"""
# 选取具有最少行数的图像,然后填充足够的空行
row1 = im1.shape[0]
row2 = im2.shape[0]
if row1 < row2:
im1 = concatenate((im1, zeros((row2 - row1, im1.shape[1]))), axis=0)
elif row1 > row2:
im2 = concatenate((im2, zeros((row1 - row2, im2.shape[1]))), axis=0)
# 如果这些情况都没有,那么他们的行数相同,不需要进行填充
return concatenate((im1, im2), axis=1)
def plot_matches(im1, im2, locs1, locs2, matchscores, show_below=True):
"""显示一幅带有连接匹配之间连线的图片
输入:im1,im2(数组图像),locs1,locs2(特征位置),matchscores(match的输出),
show_below(如果图像应该显示再匹配下方)"""
im3 = appendimages(im1, im2)
if show_below:
im3 = vstack((im3, im3))
imshow(im3)
cols1 = im1.shape[1]
for i, m in enumerate(matchscores):
if m > 0:
plot([locs1[i][1], locs2[m][1] + cols1], [locs1[i][0], locs2[m][0]], 'c')
axis('off')
调用函数进行匹配:
im1 = array(Image.open('../image/imag3.jpg').convert('L'))
im2 = array(Image.open('../image/imag3.jpg').convert('L'))
wid = 5
harrisim = compute_harris_response(im1, 5)
filtered_coords1 = get_harris_points(harrisim, wid+1)
d1 = get_descriptors(im1, filtered_coords1, wid)
harrisim = compute_harris_response(im2, 5)
filtered_coords2 = get_harris_points(harrisim, wid + 1)
d2 = get_descriptors(im1, filtered_coords2, wid)
print('starting matching')
matches = match_twosided(d1,d2)
figure()
gray()
plot_matches(im1, im2, filtered_coords1, filtered_coords2, matches)
show()
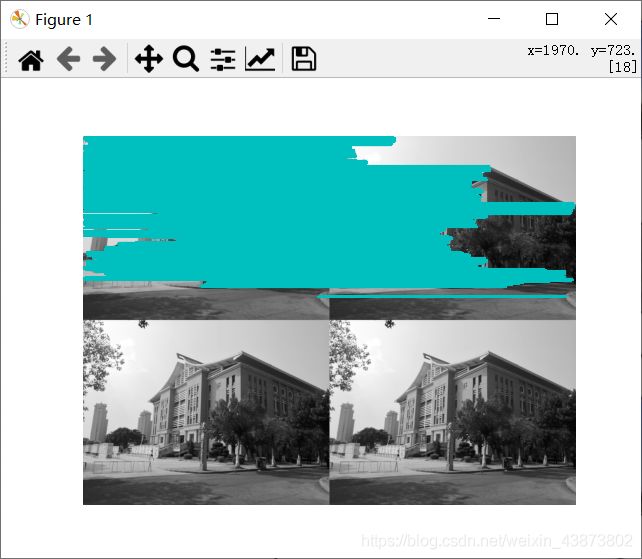
运行结果:
二、SIFT(尺度不变特征变换)
Harris 角点检测算法的结果存在一些不正确的匹配。是因为图像像素块的互相关矩阵具有较弱的描述性。这些描述符还有一个问题,
David Lowe提出的SIFT(Scale-Invariant Feature Transform,尺度不变特征变化)是过去十年中最成功的图像局部描述子之一。SIFT特征包括兴趣点检测器和描述子。SIFT描述子具有非常强的稳定性,这也是SIFT特征能够成功和流行的主要原因。SIFT特征对于尺度、旋转和亮度都具有不变性,因此,它可以用于三维视角和噪声的可靠匹配。
SIFT算法可以解决的问题:
- 目标的旋转、缩放、平移(RST)
- 图像仿射/投影变换(视点viewpoint)
- 光照影响(illumination)
- 目标遮挡(occlusion)
- 杂物场景(clutter)
- 噪声
SIFT算法实现步骤简述:
实质上可以归为在不同尺度空间上查找特征点(关键点)的问题。
SIFT算法实现特征匹配主要有三个流程:
- 提取关键点;
- 对关键点附加详细信息(局部特征),既描述符;
- 通过特征点(附带上特征向量的关键点)的两两比较找出互相匹配的若干对特征点,建立景物之间的对应关系。
哪些点是SIFT要查找的关键点(特征点)?
SIFT所查找到的关键点(特征点)是一些十分突出,不会因光照,仿射变换和噪音等因素而变化的点,如角点、边缘点、暗区的亮点及亮区的暗点等。
根据归纳,SIFT特征点希望选择出具有下述不变性的点:
尺度 方向 位移 光照
2.1 兴趣点
SIFT特征使用高斯差分函数来定位兴趣点: D ( x , σ ) = [ G κ σ ( x ) − G σ ( x ) ] ∗ I ( x ) = I κ σ − I σ D(x,\sigma)=[G_{\kappa \sigma}(x)-G_\sigma(x)]*I(x)=I_{\kappa \sigma}-I_\sigma D(x,σ)=[Gκσ(x)−Gσ(x)]∗I(x)=Iκσ−Iσ 其中,Gσ是二维高斯核,Iσ是使用Gσ模糊的灰度图像,κ是决定相差尺度的常熟。兴趣点是在图像位置和尺度变换下D(x,σ)的最大值和最小值点。这些候选位置通过滤波去除不稳定点。基于一些准则,比如认为低对比度和位于边上的点不是兴趣点,我们可以去除一些候选兴趣点。
2.2 描述子
兴趣点(关键点)位置描述子给出了兴趣点的位置和尺度信息。为了实现旋转不变性,基于每个点周围图像梯度的方向和大小,SIFT描述子又引入了参考方向。SIFT描述子使用主方向描述参考方向。主方向使用方向直方图(以大小为权重)来度量。
为了对图像具有稳健性,SIFT描述子使用图像梯度,SIFT描述子在每个像素点附近选取子区域网格,在每个子区域内计算图像梯度方向直方图。每个子区域的直方图拼接起来组成描述子向量。SIFT描述子的标准设置使用4×4的子区域,每个子区域使用8个小区间的方向直方图,会产生128个小区间的直方图(4×4×8=128)。
2.3 检测兴趣点
使用开源工具包 VLFEAT 提供的二进制文件来计算图像的SIFT特征。
在此之前要先下载配置好PCV库,PCV库下载地址,下载解压后,使用 cmd 命令进入解压后的PCV目录下,使用 python setup.py install 命令,回车即可;

然后下载vlfeat-0.9.20-bin版本解压,vlfeat 下载地址,选择bin目录下的文件对应系统的文件
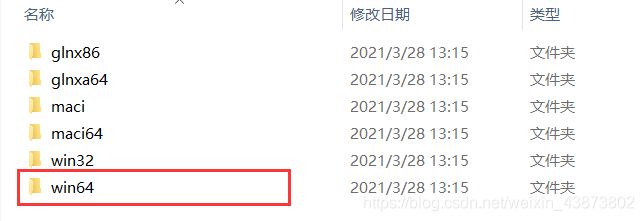
像我是选择了win64,将其复制到python环境目录下的Lib\site-packages文件目录下

可以将它改名为自己方便记住的。之后进入PCV库

打开sift.py文件
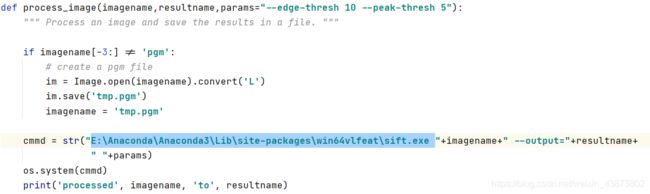
将原本的 sift 改为刚刚安装的VLFEAT目录下的 sift.exe 路径,记得后面有一个空格符号。
2.4 匹配描述子
对于将一幅图像中的特征匹配到另一幅图像的特征,一种稳健的准则(同样是由Lowe提出的)是使用者两个特征距离和两个最匹配特征距离的比率。相比于图像中的其他特征,该准则保证能够找到足够相似的唯一特征。使用该方法可以使错误的匹配数降低。下面的代码实现了匹配函数。
2.5 代码实现
通过下面的命令绘制出SIFT特征位置的图像:
from PCV.localdescriptors import sift
from pylab import *
from PIL import Image
from numpy import *
imname = 'image1.jpg'
im1 = array(Image.open('image1.jpg').convert('L'))
sift.process_image(imname, 'image1.sift')
l1, d1 = sift.read_features_from_file('image1.sift')
figure()
gray()
sift.plot_features(im1, l1, circle=True)
show()
运行结果:
分析:
从运行结果可以看出,使用SIFT算法检测出的特征点和Harris角点检测算法检测出的特征点是不同的。IFT选取的对象会使用DoG检测关键点,并且对每个关键点周围的区域计算特征向量,它主要包括两个操作:检测和计算,操作的返回值是关键点信息和描述符,最后在图像上绘制关键点,并用imshow函数显示这幅图像。
通过下面的命令检测出图像的SITF特征点,并通过 match_twosided() 函数返回特征点匹配情况。
# import sift
from PCV.localdescriptors import sift
from pylab import *
from PIL import Image
from numpy import *
im1f = r'E:\pycharm\PycharmProjects\pythonWork\image\image1.jpg'
im2f = r'E:\pycharm\PycharmProjects\pythonWork\image\image1.jpg'
im1 = array(Image.open(im1f))
im2 = array(Image.open(im2f))
sift.process_image(im1f, 'out_sift_1.txt')
l1, d1 = sift.read_features_from_file('out_sift_1.txt')
figure()
gray()
subplot(121)
sift.plot_features(im1, l1, circle=False)
sift.process_image(im2f, 'out_sift_2.txt')
l2, d2 = sift.read_features_from_file('out_sift_2.txt')
subplot(122)
sift.plot_features(im2, l2, circle=False)
matches = sift.match_twosided(d1, d2)
print('{} matches'.format(len(matches.nonzero()[0])))
figure()
gray()
sift.plot_matches(im1, im2, l1, l2, matches, show_below=True)
show()
运行结果:
匹配两张一样的图片:


匹配两张不一样的图片:
分析:
通过运行结果,可以看出两张一样的图片进行匹配,匹配出的对应特征点有很多。但是对于两张不同角度(不同拍摄地点)拍摄的照片,也可以匹配出对应特征点,只是匹配的特征点的效果不好。
因此,虽然SIFT算法相比较Harris角点检测算法能够更好的匹配,但是也存在不足之处,对于不同角度拍摄的图片,并不能够很好的进行特征点的匹配。
三、匹配地理标记图像
在这个例子中,我们将使用局部描述子来匹配带有地理标记的图像。
3.1 可视化连接的图像
我们首先通过图像间是否具有匹配的局部描述子来定义图像之间的连接,然后可视化这些连接情况。为了完成可视化,我们可以在图中显示这些图像,图的边代表连接。我们将会使用 pydot 工具包,该工具包是功能强大的 GraphViz 图形库的 python 接口。
3.1.1 代码实现
# -*- coding: utf-8 -*-
import json
import os
import urllib
from pylab import *
from PIL import Image
from PCV.localdescriptors import sift
from PCV.tools import imtools
import pydot
if __name__ == '__main__':
download_path = "E:\pycharm\PycharmProjects\pythonWork\work2\image"
path = "E:\pycharm\PycharmProjects\pythonWork\work2\image"
imlist = imtools.get_imlist(download_path)
nbr_images = len(imlist)
featlist = [imname[:-3] + 'sift' for imname in imlist]
for i, imname in enumerate(imlist):
sift.process_image(imname, featlist[i])
matchscores = zeros((nbr_images, nbr_images))
for i in range(nbr_images):
for j in range(i, nbr_images): # only compute upper triangle
print('comparing ', imlist[i], imlist[j])
l1, d1 = sift.read_features_from_file(featlist[i])
l2, d2 = sift.read_features_from_file(featlist[j])
matches = sift.match_twosided(d1, d2)
nbr_matches = sum(matches > 0)
print('number of matches = ', nbr_matches)
matchscores[i, j] = nbr_matches
# copy values
for i in range(nbr_images):
for j in range(i + 1, nbr_images): # no need to copy diagonal
matchscores[j, i] = matchscores[i, j]
# 可视化
threshold = 2 # min number of matches needed to create link
g = pydot.Dot(graph_type='graph') # don't want the default directed graph
for i in range(nbr_images):
for j in range(i + 1, nbr_images):
if matchscores[i, j] > threshold:
# first image in pair
im = Image.open(imlist[i])
im.thumbnail((100, 100))
filename = path + str(i) + '.jpg'
im.save(filename) # need temporary files of the right size
g.add_node(pydot.Node(str(i), fontcolor='transparent', shape='rectangle', image=filename))
# second image in pair
im = Image.open(imlist[j])
im.thumbnail((100, 100))
filename = path + str(j) + '.jpg'
im.save(filename) # need temporary files of the right size
g.add_node(pydot.Node(str(j), fontcolor='transparent', shape='rectangle', image=filename))
g.add_edge(pydot.Edge(str(i), str(j)))
g.write_jpg('out-jimei.jpg')
运行结果:
 |
 |
|---|
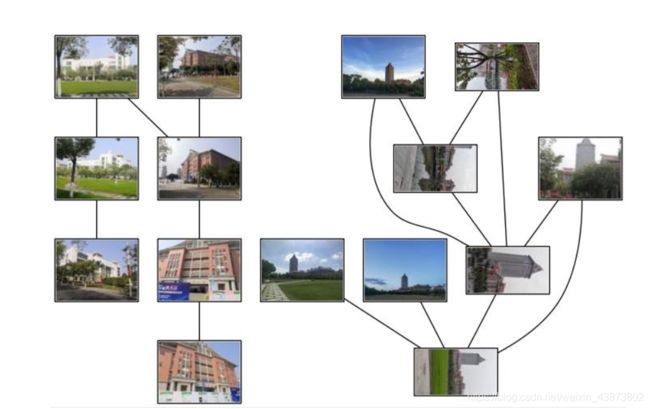

分析:
运行结果可以看出,使用局部描述子将在同一地理位置点拍摄图像进行分类。前两张图片因为图片数量相对较少,对于远近、方向不同的图片比较好的进行了匹配。但是将图片数量增加后,就出现了一些问题,虽然大部分的图片的匹配正确的,但是也出现了匹配错误的情况,如红色方框内的两张图片,我们一看就知道不是同一张建筑的图片,但是算法却将它们匹配到了一起;而蓝色圈起来的几张照片,是同一张建筑不同角度拍摄的结果,但是算法并没有完全匹配正确。这也体现了SIFT算法的不足之处。对于不用角度拍摄的照片,SIFT算法匹配的效果差,并不能完成正确的匹配成功,甚至可能出现两张不同的照片匹配到一起的情况或者是不同角度拍摄的照片无法匹配成功的情况。