Hadoop是什么
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
简单的说:
Hadoop是在分布式服务器集群上存储海量数据并运行分布式分析应用的一个开源的软件框架。具有可靠、高效、可伸缩的特点。
Hadoop1.0时期架构图
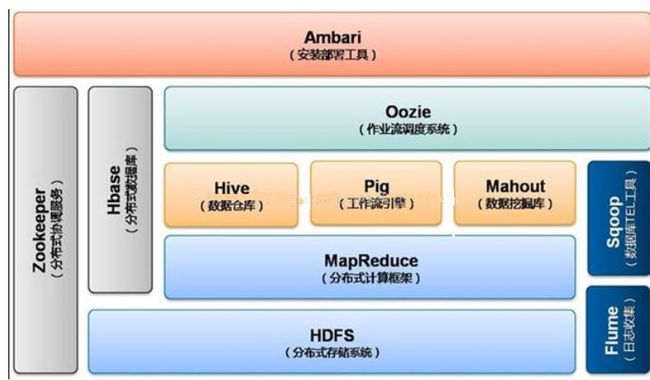
HDFS
Hadoop生态系统的基础组件是Hadoop分布式文件系统(HDFS)。HDFS的机制是将大量数据分布到计算机集群上,数据一次写入,但可以多次读取用于分析。它是其他一些工具的基础,例如HBase。
MapReduce
Hadoop的主要执行框架即MapReduce,它是一个用于分布式并行数据处理的编程模型,将作业分为mapping阶段和reduce阶段(因此而得名)。开发人员为Hadoop编写MapReduce作业,并使用HDFS中存储的数据,而HDFS可以保证快速的数据访问。鉴于MapReduce作业的特性,Hadoop以并行的方式将处理过程移向数据,从而实现快速处理。
HBase
一个构建在HDFS之上的面向列的NoSQL数据库,HBase用于对大量数据进行快速读取/写入。HBase将Zookeeper用于自身的管理,以保证其所有组件都正在运行。
Zookeeper
Zookeeper是Hadoop的分布式协调服务。Zookeeper被设计成可以在机器集群上运行,是一个具有高度可用性的服务,用于Hadoop操作的管理,而且很多Hadoop组件都依赖它。
Oozie
一个可扩展的Workflow系统,Oozie已经被集成到Hadoop软件栈中,用于协调多个MapReduce作业的执行。它能够处理大量的复杂性,基于外部事件(包括定时和所需数据是否存在)来管理执行。
Pig
对MapReduce编程复杂性的抽象,Pig平台包含用于分析Hadoop数据集的执行环境和脚本语言(Pig Latin)。它的编译器将Pig Latin翻译为MapReduce程序序列。
Hive
类似于SQL的高级语言,用于执行对存储在Hadoop中数据的查询,Hive允许不熟悉MapReduce的开发人员编写数据查询语句,它会将其翻译为Hadoop中的MapReduce作业。类似于Pig,Hive是一个抽象层,但更倾向于面向较熟悉SQL而不是Java编程的数据库分析师。
Sqoop
是一个连通性工具,用于在关系型数据库和数据仓库与Hadoop之间移动数据。Sqoop利用数据库来描述导入/导出数据的模式,并使用MapReduce实现并行操作和容错。
Flume
是一个分布式的、具有可靠性和高可用性的服务,用于从单独的机器上将大量数据高效地收集、聚合并移动到HDFS中。它基于一个简单灵活的架构,提供流式数据操作。它借助于简单可扩展的数据模型,允许将来自企业中多台机器上的数据移至Hadoop。
Mahout
一个机器学习和数据挖掘的库,提供用于聚类、回归测试和统计建模常见算法的MapReduce实现。
Ambari
该项目致力于简化Hadoop的管理,提供对Hadoop集群进行供应、管理和监控的支持。
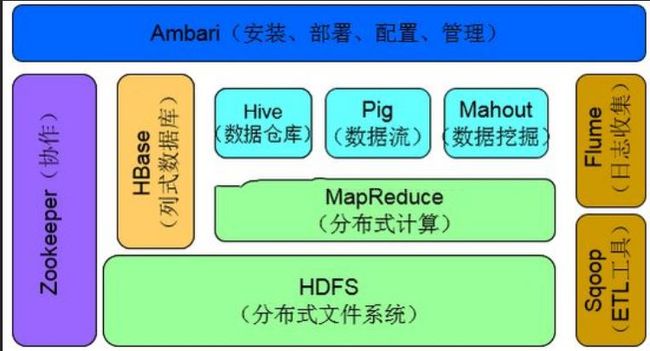
Hadoop2.0时期架构图
分析 Hadoop2.0时期架构图:
最底层是分布式文件系统HDFS。
在分布式文件系统之上是资源管理与调度系统YARN。
YARN相当于一个操作系统,基于YARN可以部署离线批处理计算框架MapReduce、交互式分布式计算框架Tez,内存计算框架Spark,流式计算框架Storm等。
上层可以运行Hive、Pig等数据库。
Hive是一种类似于sql的分布式数据库,可以构建数据仓库。
Pig是一种流数据库语言。
如果需要执行多个连续的分布式计算任务,那么Oozie是理想的选择,其可以方便的执行多种任务。
除此之外,Hbase可以作为分布式数据库来使用,例如构建海量图像数据的存储仓库,其查询速度很快,是面向列存储的数据库。
ZooKeeper是分布式协调服务。
Flume可以构建日志分析系统。Sqoop可以轻松将数据库中的数据导入HDFS.
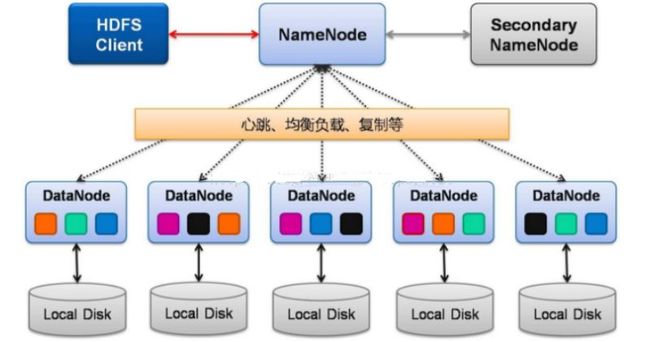
HDFS架构
MapReduce架构
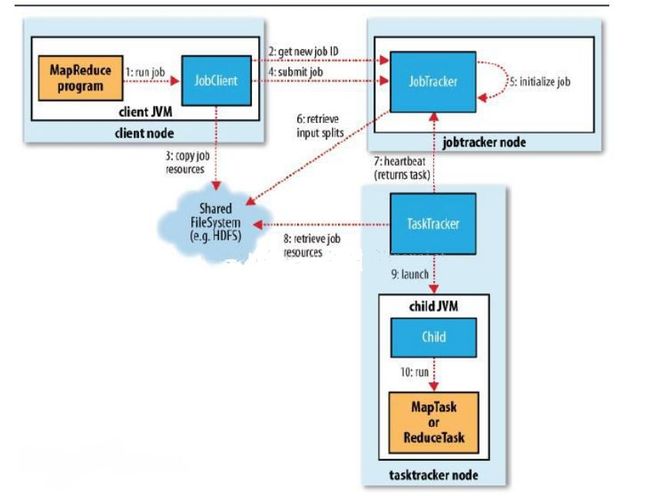
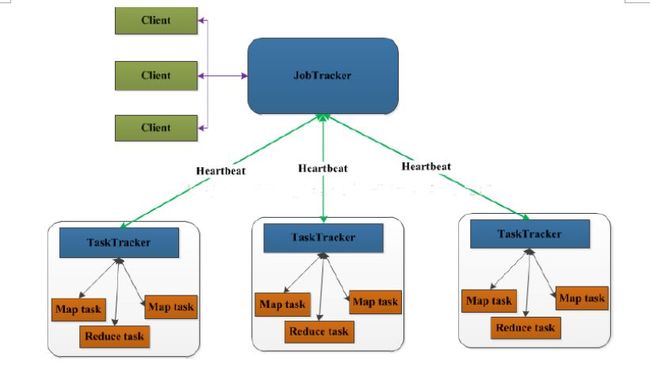
JobTracker:Master节点,只有一个,管理所有作业,作业/任务的监控、错误处理等;将任务分解成一系列任务,并分派给TaskTracker。
TaskTracker:Slave节点,运行Map Task和Reduce Task;并与JobTracker交互,汇报任务状态。
Map Task:解析每条数据记录,传递给用户编写的map(),并执行,将输出结果写入本地磁盘(如果为map-only作业,直接写入HDFS)。
Reducer Task:从Map Task的执行结果中,远程读取输入数据,对数据进行排序,将数据按照分组传递给用户编写的reduce函数执行。
yarn架构
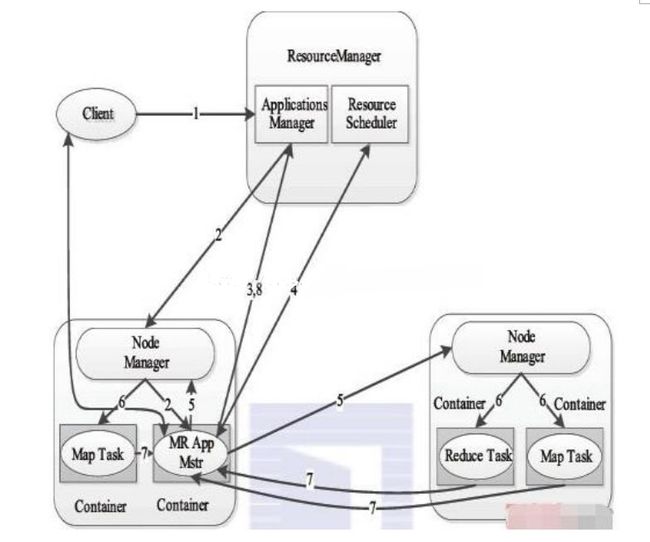
步骤1 用户向YARN中提交应用程序,其中包括ApplicationMaster程序、启动ApplicationMaster的命令、用户程序等。
步骤2ResourceManager为该应用程序分配第一个Container,并与对应的Node-Manager通信,要求它在这个Container中启动应用程序的ApplicationMaster。
步骤3ApplicationMaster首先向ResourceManager注册,这样用户可以直接通过ResourceManager查看应用程序的运行状态,然后它将为各个任务申请资源,并监控它的运行状态,直到运行结束,即重复步骤4~7。
步骤4ApplicationMaster采用轮询的方式通过RPC协议向ResourceManager申请和领取资源。
步骤5 一旦ApplicationMaster申请到资源后,便与对应的NodeManager通信,要求它启动任务。
步骤6NodeManager为任务设置好运行环境(包括环境变量、JAR包、二进制程序等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务。
步骤7 各个任务通过某个RPC协议向ApplicationMaster汇报自己的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。
在应用程序运行过程中,用户可随时通过RPC向ApplicationMaster查询应用程序的当前运行状态。
步骤8 应用程序运行完成后,ApplicationMaster向ResourceManager注销并关闭自己。
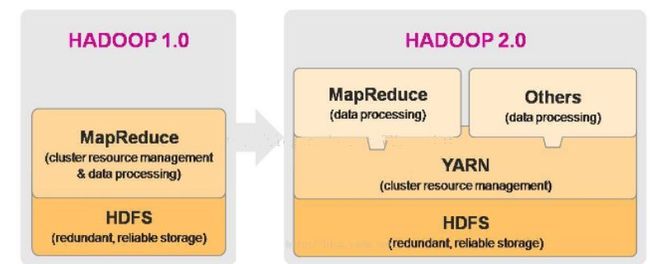
hadoop1.0与hadoop2.0比较
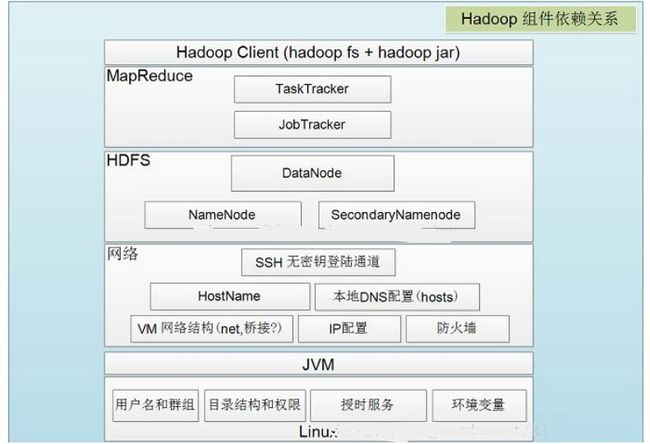
Hadoop组件依赖关系
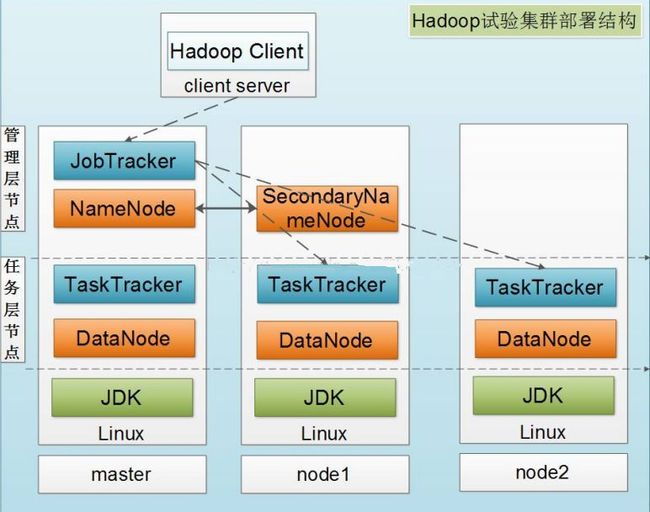
Hadoop实验集群部署结构
负责协调工作流程的ZooKeeper和Oozie

随着越来越多的项目加入Hadoop大家庭并成为集群系统运作的一部分,大数据处理系统需要负责协调工作的的成员。随着计算节点的增多,集群成员需要彼此同步并了解去哪里访问服务和如何配置,ZooKeeper正是为此而生的。
而在Hadoop执行的任务有时候需要将多个Map/Reduce作业连接到一起,它们之间或许批次依赖。Oozie组件提供管理工作流程和依赖的功能,并无需开发人员编写定制的解决方案。
Ambari是最新加入Hadoop的项目,Ambari项目旨在将监控和管理等核心功能加入Hadoop项目。Ambari可帮助系统管理员部署和配置Hadoop,升级集群以及监控服务。还可通过API集成与其他的系统管理工具。
Apache Whirr是一套运行于云服务的类库(包括Hadoop),可提供高度的互补性。Whirr现今相对中立,当前支持Amazon EC2和Rackspace服务。
欢迎关注我们的公众号,每天都有精彩内容分享哦 ~~
