深入浅出语言模型(二)——静态语言模型(独热编码、Tf-idf、word2vec、FastText、glove、Gussian Embedding、Pointcare Embedding )
引言
上一节讲述了我们的语言模型,什么是语言模型以及如何得到语言模型还有一些语言模型有趣的应用。对于我们一句话来说,我们需要对其进行特征表示。通俗点来说就是要将其转换成一个向量的形式。那么我们如何将一个句子或者一个词语转化成向量呢,这就是我们今天所要学习的内容——词向量,当我们得到词向量后,我们就可以对一个句子进行特征工程从而得到句子的特征表示。
深入浅出语言模型(一)——语言模型及其有趣的应用
深入浅出语言模型(二)——静态语言模型(独热编码、Tf-idf、word2vec、FastText、glove、Gussian Embedding、Pointcare Embedding )
深入浅出语言模型(三)——语境化词向量表示(CoVe、ELMo、ULMFit、GPT、BERT)
深入浅出语言模型(四)——BERT的后浪们(RoBERTa、MASS、XLNet、UniLM、ALBERT、TinyBERT、Electra)
静态词向量static embedding
独热编码
独热编码是最古老的一种词向量的编码形式,简单来说就是一种0-1表示。对于某个单词,去词库里寻找这个单词所对应的索引,得到位置索引后,将该位置标为1,其它 V − 1 V-1 V−1的位置标为0,其中 V V V是词库的大小。那么一个词就可以有这个稀疏的维度为 V V V的向量表示,如下图所示,其中“爬山”在大小为7的词库里位置为3,所以”爬山“的词向量第三个位置为1,其它的位置为0:

那么由这种独热编码如何构造句子级别的向量表示呢?其实可以用**词袋模型(bag of words)**这样简单的思想。不考虑其词法和语序的问题,即每个词语都是独立的.具体有两种,一种是boolean vecotr;另外一种是count vector,如下所示:
boolean vector:

count vector:

这里简单说一说计算句子相似度的两种方式,第一种是欧氏距离,第二种方式是余弦相似度,具体公式大家可以去搜一下,很简单这里不再赘述。
Tf-idf
如果就像刚才那么简单的用词袋模型的思想去表征,那么很显然一个单词在一个句子里出现的越多就越重要。但是刚才这么简单的表征句子向量真的合理吗?其实并不是出现的越多就越重要,也并不是出现的越少就越不重要。就像我们拿一个情感分析的任务来说,例如句子里会包含很多的不定冠词和代词,这种词语几乎在每个句子里都有,但是他们对于情感分析基本没有帮助;反过来像一些感情词,可能出现了一次,就起到了决定性的作用。为此人们想到了一种新的进行句子表征的方式 t f i d f tfidf tfidf。其数学形式表达如下:
f t i d f ( w ) = t f ( d , w ) ∗ i d f ( w ) ftidf\left( w \right) = tf\left( {d,w} \right) * idf\left( w \right) ftidf(w)=tf(d,w)∗idf(w)
t f tf tf是指的在句子 d d d中 w w w的词频。 i d f ( w ) = log N N ( w ) idf\left( w \right) = \log \frac{N}{ {N\left( w \right)}} idf(w)=logN(w)N,其中 N N N是指句子的数量, N ( w ) N(w) N(w)是指包含单词 w w w的句子数量。直观上来理解的话,如果一个词得词频越高,那么 t f tf tf就越高;但是如果一个词是一个普遍词,在很多句子出现过,那么 i d f idf idf就比较低,相当于通过这种方式对一个单词得词频进行了一个balance,具体的计算细节如下图样例示:
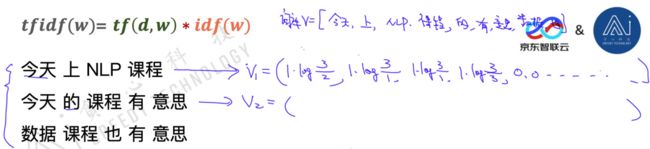
word2vec
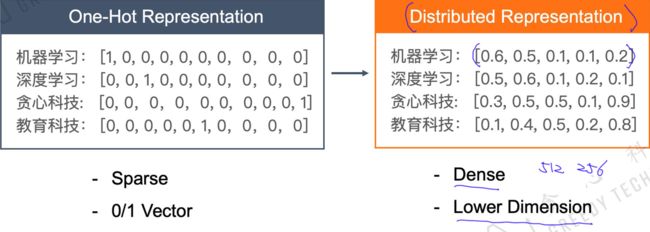
刚才使用的方法是一种独热编码的方式。但是他有很多明显的缺点。首先它是一个很稀疏的表示,并且向量维度 v v v很大;另外无法表达两个词语之间的相似度。因为任意两个词的相似度都为0,这显然是不合理的。我们现在要将稀疏的one-hot representation变成一种稠密的分布表示 distributed representation,如下图所示:
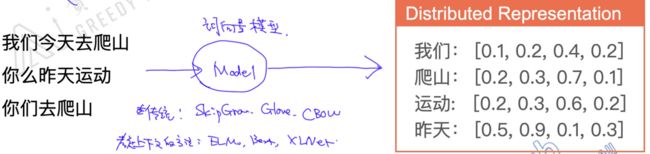
那么我们用稠密化的分布表示来表示词向量要如何训练呢,是否可以相比onehot词向量达到一个更好的表示,也可以衡量两个词的相似度?显然可以做到。那我们就开始去训练词向量了,这是NLP任务的核心,包括现在大热的BERT核心思想也是训练词向量。训练语言模型就是将语料库放入语言模型进行训练,就可以学出每个单词的词向量。
word2vec有下面两种模型,cbow和skip-gram:
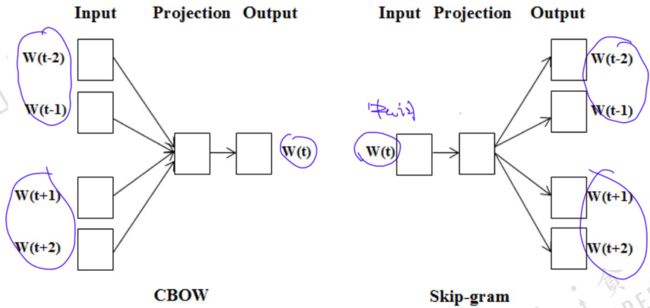
cbow
我们先简单说一下什么cbow模型,cbow模型的大体思想是根据周围的词去预测中心词 w ( t ) w(t) w(t)。cbow的计算流程如下:
- 输入层是上下文单词的one-hot向量
- 所有one-hot分别乘以共享的输入权重矩阵 W W W
- 所得到的向量加权求和平均作为隐向量,size为 1 x N 1xN 1xN
- 乘以输出权重矩阵 W ′ W' W′
- 得到的 1 x v 1xv 1xv的向量经过激活函数处理得到 V V Vdim的概率分布,概率最大的index所指示的单词为预测出来的中间词(target word)
- 与 true label 的one-hot向量作比较,误差越小越好。
- 训练好,可以将矩阵 W W W为训练好的词向量矩阵。
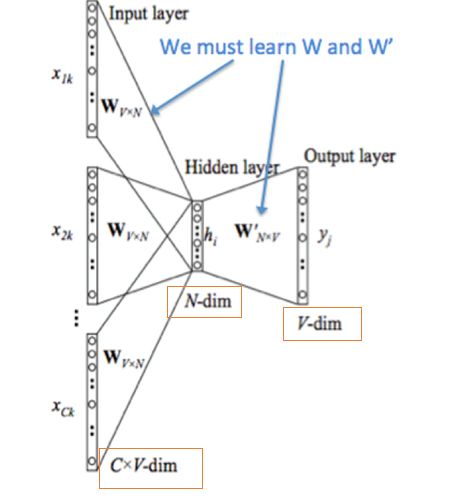
skip-gram
我们介绍完cbow,接下来我们介绍skip-gram,与cbow相反,skip-gram模型根据中心词 w ( t ) w(t) w(t)去预测周围的单词。skip-gram是我觉得一个数学推导非常漂亮的模型,下面写一下详细的推导过程:
对于一句话:今天 天气 十分 不错
我们对于 windows_size=1 的skip-gram模型的目标函数为: M a x p ( 天 气 ∣ 今 天 ) p ( ∣ 今 天 天 气 ) p ( 十 分 ∣ 天 气 ) p ( 天 气 ∣ 十 分 ) p ( 不 错 ∣ 十 分 ) p ( 十 分 ∣ 不 错 ) Maxp\left( {天气|今天} \right)p\left( {|今天天气} \right)p\left( {十分|天气} \right)p\left( {天气|十分} \right)p\left( {不错|十分} \right)p\left( {十分|不错} \right) Maxp(天气∣今天)p(∣今天天气)p(十分∣天气)p(天气∣十分)p(不错∣十分)p(十分∣不错)
转化成数学语言如下:

其中,我们不断优化得到的 U U U和 V V V可以选择其中的一个矩阵当作我们训练出来的词向量矩阵,可以使用SGD进行更新
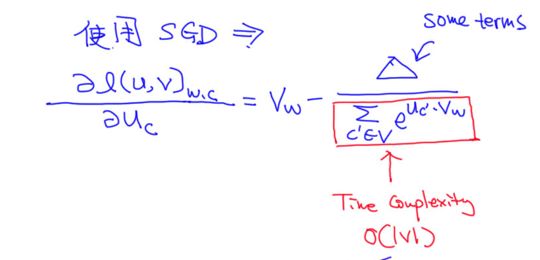
但是面对这么多的计算参数,效率很低。为此人们提出了两种优化的方法:Hierarchical Softmax以及Negative Sampling。
Hierarchical Softmax
以前网络结构每次的网络更新需要更新 w w w和 w ′ w' w′,每次更新都需要非常大的计算量。多层softmax在模型的训练过程中,通过Huffman编码,构造了一颗庞大的Huffman树,同时会给非叶子结点赋予向量。我们要计算的是目标词w的概率,这个概率的具体含义,是指从root结点开始随机走,走到目标词w的概率。因此在途中路过非叶子结点(包括root)时,需要分别知道往左走和往右走的概率。只需要计算路径上所有非叶子节点词向量的贡献即可, 计算量将为树的树的深度, l o g ( v ) log(v) log(v)
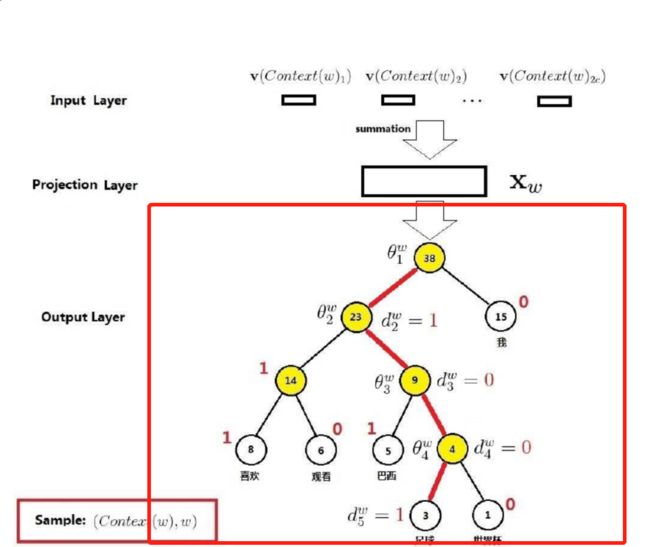
假如一句话,我/喜欢/看/(足球)/比赛,其中 (足球)是目标单词。那对于这个样本来说,我们只需要计算到达( 足球) 这个路径,并且更新这个路径参数使得去 (足球) 的路径概率最大化就可以对吧,不用管其它的路径。就是只更新到达(足球)这个叶子节点经过的这些节点的参数。
Negative Sampling
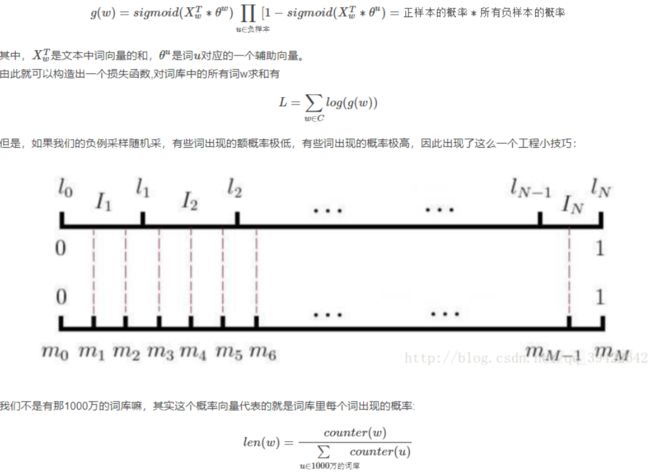
多层softmax存在一些缺点,即当中间词为生僻词时,那么计算会非常耗时。人们又想出了一个新的改进方法,叫做负采样,思想很简单:预测“我喜欢观看巴西足球世界杯“这句话中的“巴西“这个词为我们的标准答案,其他的1000万-1个就都不是标准答案.既然这样,干脆就在这1000万-1个负样本中抽取负样本来计算。
预测“我喜欢观看巴西足球世界杯“这句话中的“巴西“这个词为我们的标准答案,其他的1000万-1个就都不是标准答案.既然这样,干脆就在这1000万-1个负样本中抽取负样本来计算。
skip-gram vs cbow
目前来说,skip-gram应用比cbow更普遍,也就是说在人们潜意识认知中,skip-gram的词向量模型要比cbow词向量模型更为合理,为什么呢?我分析理由有三:
1. 对于一句话的样本来说,skip-gram的训练对要比cbow多,如一个句子有5个词,那么skip-gram的训练对为8个而cbow只有3个。
2. skip-gram是有中间词预测周围词,类似生成任务;而cbow是周围此生成中心词,类似于填空任务;明显前者更难,前者训练有难度,才会训练更好。
3. skip-gram相比cbow处理生僻词更好。cbow由多个词生成1个词,当包含生僻词时,也会被多个此中的常见词给覆盖掉,所以特征不好建模。换一种说法是出现次数较少的单词在语料库中较多的时候,SkipGram效果比较好。 因为CBOW的映射层起到Smoothing的作用,模型会预测更经常出现的单词。
FastText
刚才我们介绍的word2vec,无论是cbow还是skip-gram,都存在一个缺点,就是OOV问题,就是存在未登录词的问题。在Word2Vec中,需要为每个单词创建嵌入。因此,它不能处理任何在训练中没有遇到过的单词。例如,单词 “tensor”和“flow”出现在Word2Vec的词汇表中。但是如果你试图嵌入复合单词“tensorflow”,你将会得到一个词汇表错误。此外,还不符合语言形态学的认知,例如于词根相同的单词,如“eat”和“eaten”,Word2Vec没有任何的参数共享。每个单词都是根据上下文来学习的。因此,可以利用单词的内部结构来提高这个过程的效率。
为了解决上述挑战,Bojanowski等提出了一种新的嵌入方法FastText。他们的关键见解是利用单词的内部结构来改进从skip-gram法获得的向量表示。对skip-gram法进行如下修正:
- Sub-word生成:对于一个单词,我们生成长度为3到6的n-grams表示。例如,对于单词“eating”,从尖括号开始到尖括号结束滑动3个字符的窗口,可以生成长度为3个字符的n-grams。在这里,我们每次将窗口移动一步。

- 使用负采样的Skip-gram。在训练时skip-gram中心词的嵌入是通过取字符n-grams的向量和整个词本身来计算的。对于实际的上下文单词,我们直接从嵌入表示中获取它们的单词向量,不需要加上n-grams。

由于存在大量的唯一的n-grams,我们应用哈希来限制内存需求。我们不是学习每个唯一的n-grams的嵌入。而是学习一个总的B嵌入,其中B表示存储桶的大小。文章中用的桶的大小为200万。每个字符n-gram被散列到1到b之间的整数,尽管这可能会导致冲突,但它有助于控制词汇表的大小。fasttext的subword机制是通过n-gram实现,通过hash到一个bucket构建,不过原论文没有提供直接持久化这个n-gram后的词表的方法,实现层面也不会保存这些subword到词表中.
此外,fastText是一个快速文本分类算法。fastText模型架构和word2vec中的CBOW很相似, 不同之处是fastText预测标签而CBOW预测的是中间词。fastText模型架构:其中 x 1 , x 2 , … , x N − 1 , x N x_1,x_2,…,x_{N−1},x_N x1,x2,…,xN−1,xN表示一个文本中的n-gram向量,每个特征是词向量的平均值。这和前文中提到的cbow相似,cbow用上下文去预测中心词,而此处用全部的n-gram去预测指定类别。
此外计算特征时,还引入了n-grams的信息。基本思想是将文本内容按照子节顺序进行大小为N的窗口滑动操作,最终形成窗口为N的字节片段序列。而且需要额外注意一点是n-gram可以根据粒度不同有不同的含义,有字粒度的n-gram和词粒度的n-gram。
Word Embedding by Matrix Factorization
这篇工作来自于2014年的nips上,首先他的思想是利用语料库中所有的句子来构建一个大的矩阵 X X X。假如有下面语料库三个句子,可以构建一个co-ocurrance matrix,里面记录着单词两两出现在一个句子的次数, 例如 ‘i’ 和 ‘like’ 同时出现了两次,那么就把那里置为 ‘2’。所以这是一个很大的稀疏矩阵,维度为 V V Vx V V V。
我们希望把大的矩阵 X X X进行一个SVD的操作,即矩阵分解。因为作者认为这么大的矩阵是比较稀疏的,作者想学到一个更低秩(low-rec)的信息,即一个低纬度的表示。最后得到的矩阵 U U U的每一行就代表着每个词的向量信息。SVD即矩阵的奇异值分解(Singular Value Decomposition)
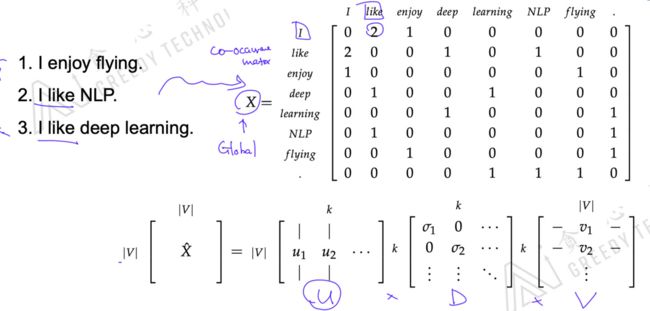
这种方式其实是一种global方式,因为他这个矩阵的形成是根据所有语料信息来进行构建的。刚才讨论的skip-gramd等等是一种local方法论,因为他们每次考虑是仅考虑中心词和周围的词。
无论是global方式还有local方式都有各自的优势。例如global方式能从全局的角度更好的审视语料库的特点。
Glove
既然局部信息有局部信息的好处,全局信息也有全局信息的好处。那么我们为何不同时利用全局信息呢和局部信息呢。尽管word2vector在学习词与词间的关系上有了大进步,但是它有很明显的缺点:只能利用一定窗长的上下文环境,即利用局部信息,没法利用整个语料库的全局信息。鉴于此,斯坦福的GloVe诞生了,它的全称是global vector,很明显它是要改进word2vector,成功利用语料库的全局信息。
首先他还是要充分利用全局的词组对(co-occurance counts),类似于刚才提到的矩阵分解的方法。不过他不是在整个句子中寻找单词对了,他这里的共现指:单词 i i i出现在单词 j j j的环境中(论文给的环境是以 j j j为中心的左右10个单词区间)叫共现,所以他这里也用了一种滑动窗口的概念,类似skip-gram,不断滑动窗口进行统计即可得到共现矩阵。
下面简单说一下Glove的词向量函数是如何设计的。首先他这里利用了共现概率比这个概念。因为作者发现用共现概率比也可以很好的体现3个单词间的关联(因为共现概率比符合常理),所以glove作者就大胆猜想,如果能将3个单词的词向量经过某种计算可以表达共现概率比就好了(glove思想)。如果可以的话,那么这样的词向量就与共现矩阵有着一致性,可以体现词间的关系。
这里涉及到三个词 i i i, j j j, k k k,它们对应的词向量用 v i v_i vi, v j v_j vj, v k v_k vk来表示,那么我们需要找到一个映射 f f f满足: f ( v i , v j , v k ) = p i k / p j k f(v_i,v_j,v_k)=p_{ik}/p_{jk} f(vi,vj,vk)=pik/pjk
于是,glove模型的学习策略就是通过将词对儿的词向量经过内积操作和平移变换去趋于词对儿共现次数的对数值,这是一个回归问题。于是作者这样设计损失函数:
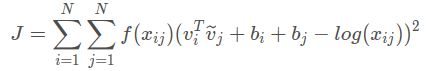
这里用的是误差平方和(最小二乘法)作为损失值,它这里在误差它这里在误差平方前给了一个权重函数 f ( x i j ) f(x_{ij}) f(xij),这个权重是用来控制不同大小的共现次数对结果的影响的,基本思想是:词对儿共现次数越多的它有更大的权重将被惩罚得更厉害些,次数少的有更小的权重,这样就可以使得不常共现的词对儿对结果的贡献不会太小,而不会过分偏向于常共现的词对儿。
Gussian Embedding
诸如skip-gram,CBOW等embedding,用于刻画相似性的都是向量点积,cosine,或者欧式距离,都是对称的。其次,embedding的学习没有注意到不确定性,对于高频词学习较好,但是低频词学习较差。因为一个句子中可能一个词出现的很多,一个词出现很少,那么意味着我们模型训练完我们会更相信那些高频词,低频词的可信度很低。
因为我们还是**基于统计学分析一下,出现次数越多,得到的是越有可信度的。**一个词如果在整个语料里出现很少,那基本是没有可信度的。 所以我们想把可信度融入模型当中,这就是Gussian Embedding的基本思想。
那么我们学出来的词向量是一个分布的形式,增加了参数(方差)。但是我们这里需要更改一下求两个词向量相似度的形式,对于分布的相似度,我们可以采用KL散度。
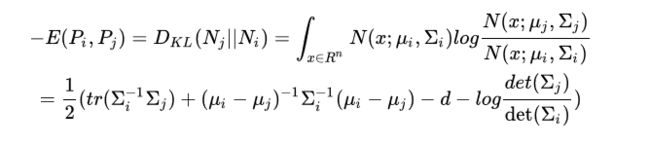
高斯embedding关注在非对称的关系上,个人认为在在某些特定的下游任务,数据不多的情况上可能更有用,比如蕴含关系。当数据足够多时,估计作用也不会太大,毕竟还有神经网络层来提取与任务相关的特征表示。
Pointcare Embedding
前面所讲的词向量都是在欧氏空间计算的,其实还是有非欧的空间存在的,例如你想计算地球仪上的两个点,不能简单计算两个点之间的直线距离,还要考虑这个地球的弧度信息等等。尤其是在物理学和天文学中,有很多非欧式空间的场景,这也叫做hierachical structure,比如一些非欧式空间的数据有层级结构或树型结构。常见的是一个双曲空间, Pointcare Embedding 就是基于双曲空间实现的。
为什么要基于双曲空间做呢,因为很多时候我们的数据化本身也是包含结构信息的或者一定的层次结构。例如单词“水果”下面可能有一些“苹果”、“香蕉”等等,所以是有一定结构关系的。作者就是想得到单词词向量时,再来做可视化可以看到这些结构关系,如下图所示:
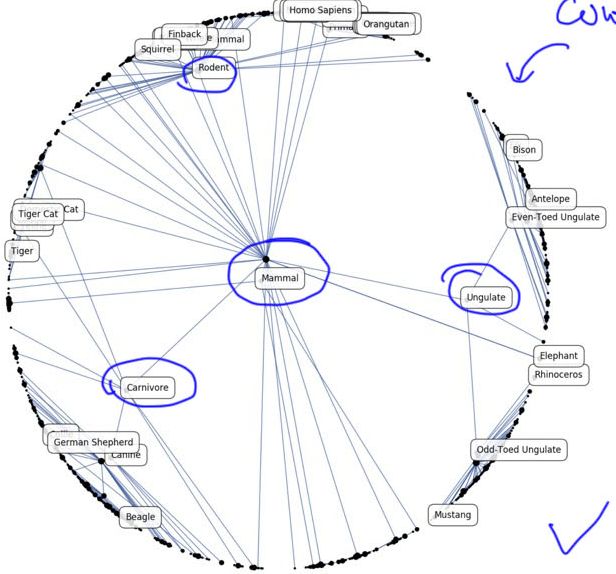
单词“mammal”下面包括“carnivore”、"ungulate"以及“rodent”等等,然后这几个单词也有各自的分支,我们发现这种结构很像树结构(tree structures)。
相关的公式也发生了一定的变化,两个单词之间的距离衡量:
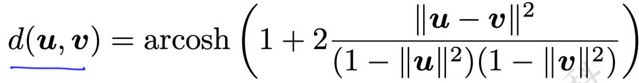
梯度更新所采用的方法(Riemannian SGD):
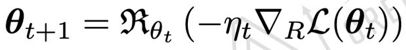
欧式空间和非欧式空间简单来说就是:在欧几里得几何中,平行线任何位置的间距相等在非欧几何中,平行的直线只在局部平行,就象地球的经线只在赤道上平行。我们当作决策树时是离散的,但是当我们在非欧空间时就变成连续的了,就可以进行梯度下降了,这是这个词向量方法给我们的启发。