Spark详解(十一):Spark运行架构原理分析
1. Spark 运行架构总体分析
1.1 总体介绍
Spark应用程序的运行架构基本上由三部分组成,包括SparkContext(驱动程序)、ClusterManger(集群资源管理器)和Executor(任务执行进程)组成
- SparkContext负责与Cluster Manager通信,进行资源的分配和监控等,负责作业的执行的全生命周期管理。
- ClusterManger提供了资源的分配和管理,在不同的运行模式下,担任的角色不同,在本地运行、SPakrStandalane模式下由Master提供,在Yarn运行模式下由Resource Mangaer担任。
1.2 重要类介绍
TaskShceduler是重要的Spark的重要调度器之一,它负责具体任务的调度执行,而SchuedlerBackend则负责应用程序运行期间与底层资源调度系统交互。
应用程序具体运行的过程是:
- SparkContext启动时,调用TaskScheduler.start方法启动TaskSchedule人调度器
- DAGScheduler调度阶段和任务拆分完毕时,调用TaskSchudler.submitTask方法提交任务。
- SchedulerBackend接收到执行任务时,通过receiveOffers方法分配运行资源并启动运行节点的Executor
- 由TaskScheduler接受到任务运行状态,如果任务运行完毕,则继续分配,直到应用程序运行完毕。
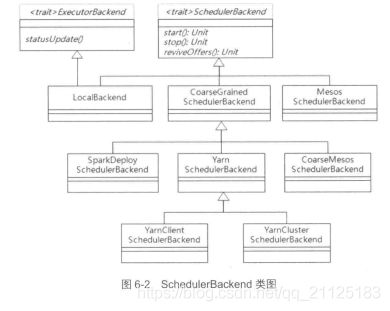
下面我们介绍Spark运行架构中十分重要的两个类:
- TaskScheduler:该类是高层调度器DAGScheduler与任务执行SchedulerBackend的桥梁。TaskScheduler是特质类,定义了任务调度相关的实现方法,TaskSchedulerImpl是其重要的子类,它实现了TaskSchedulerde所有的接口方法,而TaskScheduler的孙子类YarnScheduler和YarnClusterScheduler只是重写其中的一两个方法。
- SchedulerBackend:该类为特质类,子类根据不同的运行模式分为本地运行模式LoaclBackend,粗粒度运行模式的CoarseGraniedSchedulerBackend和细粒度MesosSchedulerBackend。粗粒度运行模式包括独立运行模式(Standalane)的SparkDelploySchedulerBackend、Yarn运行模式的YarnSchedulerBackend和粗粒度CoarssMesosSchedulerBackend。
2. 独立运行模式(Standalane)运行模式
独立运行模式是Spark自身实现的资源调度框架,由客户端、Master节点和Worker节点组成,其中SparkContext既可以运行在Master节点,也可以运行在本地客户端。
Worker节点可以通过ExecutorRunner运行在当前节点上的CoarseGrainedExecutorBackend进程,每个Worker节点存在一个或者多个CoarseGrainedExecutorBackend进程,每个进程包含一个Executor对象。该对象有一个线程池,每个线程可以执行一个任务。
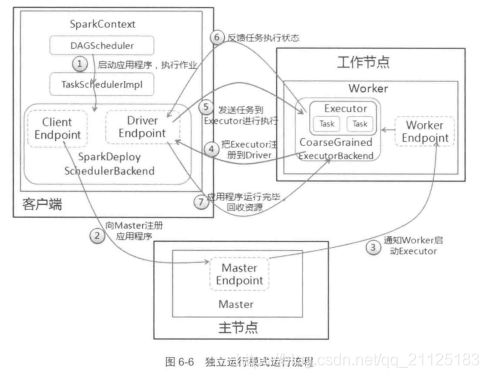
(1)启动应用程序,在SparkContext启动过程中,先初始化DAGScheduler和TaskSchedulerImpl两个调度器,同时初始化SparkDelploySchedulerBackend,并且在内部启动终端点DriverEndPoint和ClientEndPoint。
(2)终端点ClientEndPoint向Master注册应用程序,Master收到注册信息把该应用程序加入到等待应用程序队列中,等待Master分派给该应用程序Worker。
(3)当前应用程序获取Worker时,Master会通知worker中的终端点WorkerEndpoint创建CoarseGrainedExecutorBackend进程,在该进程中创建执行容器Executor。
(4) Executor创建完毕后发送消息而给Master和终端点DriverEndPoint,告知Executor以及创建完毕,在SparkContext成功注册之后,等待接收从Driver终端点执行任务的信息。
(5)SparkContext分配任务给CoarseGrainedExecutorBackend进程执行,任务执行在按照一定的调度策略进行的。
(6)CoarseGrainedExecutorBackend在任务处理的过程中,把处理任务的状态发送给SparkContext的终端点DriverEndPoint,SparkContext根据任务执行不同的结果进行处理。如果任务集处理完毕之后,则会继续发送其他任务集。
(7)应用程序运行完毕之后,SparkContext就会进行资源回收,先销毁在Worker的CoarseGrainedExecutorBackend进程,然后再销毁自身。
3. YARN运行模式
Yarn是一种资源管理机制,其上面可以运行多套计算框架。Yarn 运行模式根据Driver在集群中的位置分为两个模式,一种是Yarn-Client模式,还有一种是Yarn-Cluster模式。
3.1 Yarn 运行框架

3.2 Yarn-Client运输模式
Yarn-Client运行模式分为以下几个步骤:
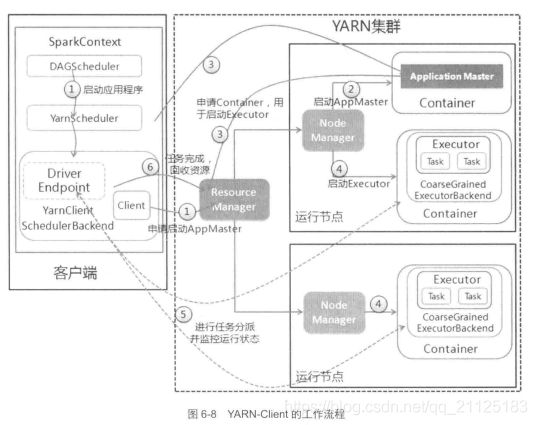
(1)启动应用程序,在SparkContext启动过程中,先初始化DAGScheduler。使用反射方法初始化YarnScheduler和YarnClientSchedulerBackend。YarnClientSchedulerBackend在内部启动DriverEndPoint和Client。
(2)ResourceManager收到请求之后,在集群中选择一个NodeManager,为该应用程序分配一个Container,为该应用程序分配一个Container,要求这个Container中启动应用程序的ApplicationMaster,与Yarn-Cluster有区别的是,在该Application Master不运行SparkContext,只与SparkContext进行联系,并且进行资源的分配
(3)客户端的SparkContext启动完毕之后,与ApplicationMaster建立通信,向ResourceManager注册,根据任务信息向ResourceManager申请资源(Container)。
(4)一旦ApplicationMaster申请到了资源(Container)后,便于对应的NodeManager建立通信,要求它在获得的Container中启动CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend会向客户端中的SparkContext进行注册并且申请任务集。
(5)客户端中的SparkContext分配任务集给CoarseGrainedExecutorBackend执行,CoarseGrainedExecutorBackend运行任务并且向终端点DriverEndpoint汇报任务运行的状态和进展,客户端随时掌握各个任务的运行状态,从而可以在任务失败的时候重新启动任务
(6)应用程序执行完毕之后,客户端的SparkContext向ResourceManger申请注销并且关闭本身。
下面我们用spark-submint脚本提交Yarn-Client应用程序
bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn-client
--num-executors 3 --driver-memory 4g \
--executor-memory 2g \
--executor-cores 1 lib\spark-examples*.jar
3.3 Yarn-Cluster运行模式介绍
在Yarn-Cluster模式中,当向用户YARN中提交一个应用程序之后,YARN将分为两个阶段运行在该应用程序中:第一个阶段是把Spark的Driver作为一个ApplicationMaster在YARN集群中启动;第二阶段是由ApplicationMaster创建应用程序,然后它向ResourceManager申请资源,并且启动Executor来运行任务集,同时监控它的整个执行过程,直到运行完成。
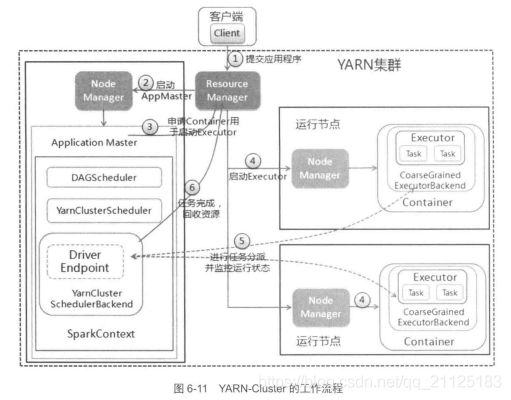
(1)客户端提交应用程序时,启动Client向YARN中提交应用程序,包括启动Application Master的命令、提交给Application Master的程序和需要在Executor中运行的程序等。
(2)esourceManager收到请求之后,在集群中选择一个NodeManager,为该应用程序分配一个Container,为该应用程序分配一个Container,要求这个Container中启动应用程序的ApplicationMaster。其中ApplicationMaster进行SparkContext等初始化工作。
(3)中ApplicationMaster向ResourceManager注册,根据任务信息向ResourceManager申请资源(Container),并且监控任务的状态直到运行结束。
(4)一旦ApplicationMaster申请到了资源(Container)后,便于对应的NodeManager建立通信,要求它在获得的Container中启动CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend会向Application Master中的SparkContext进行注册并且申请任务集。
(5)Application Master中的SparkContext分配任务集给CoarseGrainedExecutorBackend执行,CoarseGrainedExecutorBackend运行任务并且向终端点DriverEndpoint汇报任务运行的状态和进展,客户端随时掌握各个任务的运行状态,从而可以在任务失败的时候重新启动任务
(6)应用程序执行完毕之后,客户端的pplication Master向ResourceManger申请注销并且关闭本身。
下面我们用spark-submint脚本提交Yarn-Client应用程序
bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn-cluster
--num-executors 3 --driver-memory 4g \
--executor-memory 2g \
--executor-cores 1 lib\spark-examples*.jar