SENet重点干货及Pytorch实现
文章目录
- 前言
- 一、什么是SENet
-
- Squeeze
- Excitation
- 二、完整SE block的Pytorch实现
- 总结
前言
计算机视觉研究领域的一个核心理论就是如何提高网络的表现力使其关注到图片的关键位置,从而提升网络性能。与一般网络通过空间维度优化不同,SENet(Squeeze-and-Excitation Networks)着手于优化channel维度,通过引入注意力机制,增加少量参数,使模型可以更好地获取不同channel上的特征,从而提高准确率。
与其称为SENet,不如称其为SE Block。因为它可以无脑加到常见的CNN网络中,从而提升网络的性能。
论文地址:SENet:https://arxiv.org/pdf/1709.01507.pdf
一、什么是SENet
直接上图,SE Block结构如下:
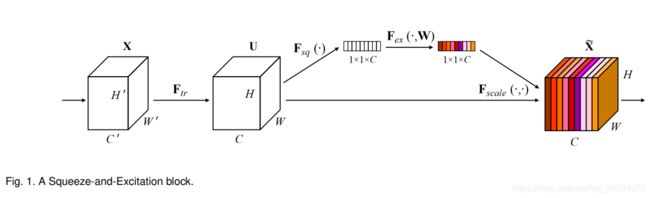
SE(Squeeze-and-Excitation),顾名思义:压缩-激活网络。如上图所示,输入X是C’×H’×W’的张量,经过卷积操作生成feature map U为C×H×W,对feature map进行压缩-激活操作。保留通道数C不变,将H×W变成1×1,接下来通过一系列激活操作,最后再将激活后的结果与U对位相乘得到最后的结果。那么S和E过程具体是如何操作的呢?
Squeeze
将C×H×W的Feature map变为C×1×1大小。保留通道数不变,改变分辨率用的是池化操作,根据文章
此处为Global pooling。Pytorch实现如下:
self.avg_pool = nn.AdaptiveAvgPool2d(1)
该步骤的目的是获取全局信息
Excitation
经过一系列激活操作,但不改变操作前后的大小和通道数。具体如何实现见下图:
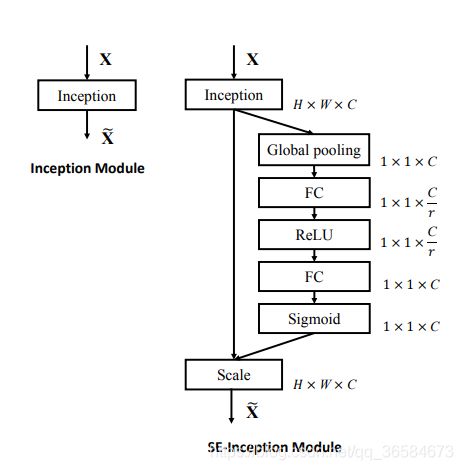
如图片右侧结构所示:Excitation为:FC→ReLU→FC→Sigmoid
具体细节如下:FC为一个全连接层Linear(C, C/r)将特征压缩到C/r通道(r为reduction是通道压缩倍率,一般取16可以平衡准确率和模型复杂性,详见论文6.1节),然后使用ReLU,接着再用一个FC层Linear(C/r, C)将特征还原至C通道,最后使用一个Simoid函数激活 Pytorch实现如下:
self.excitation = nn.Sequential(
nn.Linear(channel,channel//16,bias=False),
nn.ReLU(),
nn.Linear(channel//16,channel,bias=False),
nn.Sigmoid()
)
该步骤的目的是:Adaptive Recalibration(适合的再校准),重新校准特征,让上一步操作获得的通道信息特征相互响应。
二、完整SE block的Pytorch实现
SE模块如下:
import torch
import torch.nn as nn
class SELayer(nn.Module):
def __init__(self,channel,reduction=16):
super(SELayer,self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel,channel//16,bias=False),
nn.ReLU(),
nn.Linear(channel//16,channel,bias=False),
nn.Sigmoid()
)
def forward(self,x):
#1,16,64,64
b,c,_,_ = x.size()
y = self.avg_pool(x).view(b,c)
#1,16
#print(y.size())
y = self.fc(y).view(b,c,1,1)
#1,16,1,1
#print(y.size())
#print(y.expand_as(x))
#y.expand_as(x) 把y变成和x一样的形状
return x * y.expand_as(x)
测试代码:
x = torch.randn(1,16,64,64)
net = SELayer(16)
y = net(x)
#1,16,64,64
print(y.size())
总结
1.专注网络的channel关系,而不是空间关系
2.Squeeze建立channel间的依赖关系;Excitation重新校准特征。二者结合强调有用特征抑制无用特征。
3.能有效提升模型性能,提高准确率。几乎可以无脑添加到backbone中。根据论文,SE block应该加在Inception block之后,ResNet网络应该加在shortcut之前,将前后对应的通道数对应上即可