小白必学的爬虫基础
网络爬虫基础
- 前言
- 初识网络爬虫
-
- 什么是网络爬虫?
- 能从网络上爬取什么数据?
- 应不应该学爬虫?
- 网络爬虫是否合法?
- 爬虫的基本流程
- HTTP 协议
-
- HTTP 请求过程
- HTTP 状态码
- HTTP 头部信息
- HTTP 请求方式
- 请求
- 响应
-
- Response 的编码
- 第一个简单的爬虫
-
- Response 设置编码
前言
- 在数据量爆发式增长的互联网时代,网站与用户的沟通本质上是数据的交换:搜索引擎从数据库中提取搜索结果,将其展现在用户面前;
- 电商将产品的描述、价格展现在网站上, 以供买家选择心仪的产品;
- 社交媒体在用户生态圈的自我交互下产生大量文本、图片和视频数据等。
- 这些数据如果得以分析利用,不仅能够帮助第一方企业(拥有这些数据的企业)做出更好的决策,对于第三方企业也是有益的。而网络爬虫技术,则是大数据分析领域的第一个环节。
初识网络爬虫
什么是网络爬虫?
- 如果我们把互联网比作一张大的蜘蛛网,那一台计算机上的数据便是蜘蛛网上的一个猎物,而爬虫程序就是一只小蜘蛛,沿着蜘蛛网抓取自己想要的猎物/数据。
- 通俗理解:爬虫是一个模拟人类请求网站行为的程序。可以自动请求网页、并把数据抓取下来,然后使用一定的规则提取有价值的数据。
- 比如百度搜索引擎的爬虫叫做百度蜘蛛(Baiduspider)。百度蜘蛛每天会在海量的互联网信息中爬取,爬取优质信息并搜寻,当用户在百度搜索引擎上检索对应关键词时,百度将对关键词进行分析处理,从收录的网页中找出相关网页,按照一定的排名规则进行排序并将结果展现给用户。 除了百度搜索引擎离不开爬虫以外,其他搜索引擎也离不开爬虫,它们也拥有自己的爬虫。
- 比如 360 的爬虫叫 360Spider,搜狗的爬虫叫 Sogouspider,必应的爬虫叫 Bingbot。
- 大数据时代也离不开爬虫,比如在进行大数据分析或数据挖掘时,可以去一些比较大型的官方站点下载数据源。但这些数据源比较有限,那么如何才能获取更多更高质量的数据源呢?此时,我们可以编写自己的爬虫程序,从互联网中进行数据信息的获取。
能从网络上爬取什么数据?
简单来说,平时在浏览网站时,所有能见到的数据都可以通过爬虫程序保存下来。从社交媒体的每一条发帖到团购网站的价格及点评,再到招聘网站的招聘信息,这些数据都可以存储下来。
应不应该学爬虫?
- 应不应该学爬虫?这也是我之前问自己的一个问题,我认为对于任何一个与互联网有关的从业人员,无论是非技术的产品、运营或营销人员,还是前端、后端的程序员,都应该学习网络爬虫技术。
- 一方面,网络爬虫简单易学、门槛很低。没有任何编程基础的人在认真看完本章的爬虫 基础内容后,都能够自己完成简单的网络爬虫任务,从网站上自动获取需要的数据。
- 另一方面,网络爬虫不仅仅能使你学会一项新的技术,还能让你在工作的时候节省大量的时间。如果你对网络爬虫的世界有兴趣,就算你不懂编程也不要担心,本章将深入浅出讲解网络爬虫。一起加油!
网络爬虫是否合法?
- 网络爬虫领域目前还属于早期的拓荒阶段,虽然互联网世界已经通过自身的协议建立起 一定的道德规范(Robots 协议),但法律部分还在建立和完善中。
- 从目前情况来看,如果抓取的数据属于个人使用或科研范畴,基本不存在问题;而如果数据属于商业盈利范畴,就要就事论事,有可能属于违法行为,也有可能不违法。
- 除了上述 Robots 协议之外,我们使用网络爬虫的时候还要对自己进行约束:过于快速或者频密的网络爬虫都会对服务器产生巨大的压力,网站可能封锁你的 IP,甚至采取进一 步的法律行动。因此,需要约束自己的网络爬虫行为,
将请求的速度限定在一个合理的范围之内。
爬虫的基本流程
网络爬虫的基本工作流程如下:
- 浏览器通过 DNS 服务器查找域名对应的 IP 地址。
- 向 IP 地址对应的 Web 服务器发送请求 。
- Web 服务器响应请求,发回 HTML 页面 。
- 浏览器解析 HTML 内容,并显示出来。

科普:DNS(Domain Name Server,域名服务器)是进行域名(domain name)和与之相对应的IP地址 (IP address)转换的服务器。
- DNS中保存了一张域名(domain name)和与之相对应的IP地址 (IP address)的表,以解析消息的域名。
- 域名是Internet上某一台计算机或计算机组的名称,用于在数据传输时标识计算机的电子方位(有时也指地理位置)。
- 域名是由一串用点分隔的名字组成的,通常包含组织名,而且始终包括两到三个字母的后缀,以指明组织的类型或该域所在的国家或地区。
- 当一个浏览者在浏览器地址框中打入某一个域名,或者从其他网站点击了链接来到了这个域名,浏览器向这个用户的上网接入商发出域名请求,接入商的DNS服务器要查询域名数据库,看这个域名的DNS服务器是什么。然后到DNS服务器中抓取DNS记录,也就是获取这个域名指向哪一个IP地址。在获得这个IP信息后,接入商的服务器就去这个IP地址所对应的服务器上抓取网页内容,然后传输给发出请求的浏览器。
这个过程描述起来蛮复杂,但实际上不到一两秒钟就完成了。
HTTP 协议
HTTP 协议(HyperText Transfer Protocol,超文本传输协议)是用于 WWW 服务器传输 超文本到本地浏览器的传送协议。它可以使浏览器更加高效,减少网络传输。它不仅保证计算机正确快速传输超文本文档,还确定传输文档中的哪一部分,以及哪部分内容首先显示(如 文本先于图形)等。之后的 Python 爬虫开发,主要就是和 HTTP 协议打交道。
HTTP 请求过程
HTTP 协议采取的是请求响应模型,HTTP 协议永远都是客户端发起请求,服务器回送响应。

HTTP 协议是一个无状态的协议,同一个客户端的这次请求和上次请求没有对应关系。 一次 HTTP 操作称为一个事物,其执行过程可分为四步:
- 首先客户端与服务器建立连接,例如单击某个超链接。
- 建立连接后,客户端发送一个请求给服务器,请求方式的格式为:统一资源标识符(URL)、协议版本号,后边是 MIME 信息,包括请求修饰符、客户机信息和可能的内容。
- 服务器接到请求后,给予相应的响应信息,其格式为一个状态行,包括信息的协议 版本号、一个成功或错误的代码,后边是 MIME 信息,包括服务器信息、实体信息和可能的内容。
- 客户端接收服务器所返回的信息,通过浏览器将信息显示在用户的显示屏上,然后客户端与服务器端口断开连接。
HTTP 状态码
- 当浏览者访问一个网页时,浏览者的浏览器会向网页所在的服务器发出请求。
- 在浏览器接收并显示网页前,此网页所在的服务器会返回一个包含 HTTP 状态码的信息头(server header)用以响应浏览器的请求。HTTP 状态码主要是为了标识此次 HTTP 请求的运行状态。
- 下面是常见的 HTTP 状态码:
- 200——请求成功。
- 301——资源被永久转移到其他 URL。
- 404——请求的资源不存在。
- 500——内部服务器错误。
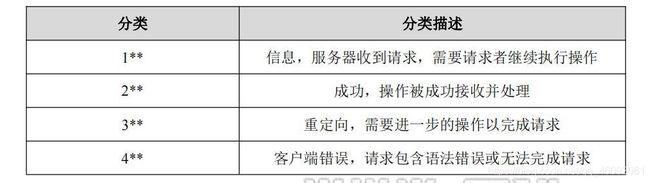
HTTP 状态码由三个十进制数字组成,第一个十进制数字定义了状态码的类型。HTTP 状态码分为 5 种类型,如表所示。
HTTP 头部信息
HTTP 头部信息由众多的头域组成,每个头域由一个域名、冒号(:)和域值三部分组成。域名是大小写无关的,域值前可以添加任何数量的空格符,头域可以被扩展为多行,在每行开始处,使用至少一个空格或制表符。
- 通过浏览器访问百度首页时,使用 F12 打开开发者工具,里面可以监控整个 HTTP 访问的过程。下面就以访问百度的 HTTP 请求进行分析,首先是浏览器发出请求,请求头的数据如下:
GET / HTTP/1.1
Host: www.baidu.com
Connection: keep-alive
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.113 Mobile Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/ *;q=0.8,applica tion/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
在请求头中包含以下内容:
- GET 代表的是请求方式,HTTP/1.1 表示使用 HTTP1.1 协议标准。
- Host 头域,用于指定请求资源的 Intenet 主机和端口号,必须表示请求 URL 的原始服务器或网关的位置。HTTP/1.1 请求必须包含主机头域,否则系统会以 400 状态 码返回。
- User-Agent 头域,里面包含发出请求的用户信息,其中有使用的浏览器型号、版本和操作系统的信息。
这个头域经常用来作为反爬虫的措施。 - Accept 请求报头域,用于指定客户端接受哪些类型的信息。例如:Accept:image/gif, 表明客户端希望接受 GIF 图像格式的资源;Accept:text/html,表明客户端希望接受 html 文本。
- Accept-Language 请求报头域,类似于 Accept,但是它用于指定一种自然语言。例 如:Accept-Language:zh-ch。如果请求消息中没有设置这个报头域,服务器假定客户端对各种语言都可以接受。
- Accept-Encoding 请求报头域,类似于 Accept,但是它用于指定可接受的内容编码。
- Connection 报头域允许发送用于指定连接的选项。例如指定连接的状态是连续,或者指定“close”选项,通知服务器,在响应完成后,关闭连接。
请求发送成功后,服务器进行响应,响应的信息,数据如下:
HTTP/1.1 200 OK
Cache-Control: no-cache
Connection: keep-alive
Content-Encoding: gzip
Content-Type: text/html;
charset=utf-8
Coremonitorno: 0
Date: Mon, 18 May 2020 09:00:11 GMT
Vary: Accept-Encoding
Transfer-Encoding: chunked
- HTTP/1.1 表示使用 HTTP1.1 协议标准,200 OK 说明请求成功。
- Date 表示消息产生的日期和时间。
- Content-Type 实体报头域用于指明发送给接收者的实体正文的媒体类型。 text/html;charset=utf-8 代表 HTML 文本文档,UTF-8 编码。
- Transfer-Encoding: chunked 表示输出的内容长度不能确定。
- Connection 报头域允许发送用于指定连接的选项。例如指定连接的状态是连续,或 者指定“close”选项,通知服务器,在响应完成后,关闭连接。
- Vary 头域指定了一些请求头域,这些请求头域用来决定当缓存中存在一个响应, 并且该缓存没有过期失效时,是否被允许利用此响应去回复后续请求而不需要重复验证。
- Cache-Control 用于指定缓存指令,缓存指令是单向的,且是独立的。
- Content-Encoding 实体报头域被用作媒体类型的修饰符,它的值表示了已经被应用 到实体正文的附加内容的编码,因而要获得 Content-Type 报头域中所引用的媒体类 型,必须采用响应的解码机制。
HTTP 请求方式
HTTP 协议请求主要分为 6 中类型,各类型的主要作用如下:
- GET 请求:GET 请求会通过 URL 网址传递信息,可以直接在 URL 中写上要传递的信息,也可以由表单进行传递。如果使用表单进行传递,这表单中的信息会自动转为 URL 地址中的数据,通过 URL 地址传递。
- POST 请求:可以向服务器提交数据,是一种比较主流也比较安全的数据传递方式, 比如在登录时,经常使用 POST 请求发送数据。
- PUT 请求:请求服务器存储一个资源,通常要指定存储的位置。
- DELETE 请求:请求服务器删除一个资源。
- HEAD 请求:请求获取对应的 HTTP 报头信息。
- OPTIONS 请求:可以获得当前 URL 所支持的请求类型。
除此之外,还有 TRACE 请求与 CONNECT 请求等,TRACE 请求主要用于测试或诊断。 由于用得非常少,所以这里不再提及。
接下来,我们将通过实例讲解 HTTP 协议请求中的 GET 请求和 POST 请求,这两种是最常用的请求方式。
- GET 请求实例分析
有时候在百度上查询一个关键词,我们会打开百度首页,并输入该关键词进行查询,比 如输入“Python”,然后按回车键,此时会出现对应的查询结果,观察一下 URL 的变化,如下所示。
https://www.baidu.com/s?wd=Python&rsv_spt=1&rsv_iqid=0x8a7b64fb0001c521&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf8&rqlang=cn&tn=baiduhome_pg&rsv_enter=1&rsv_dl=tb&oq=%25E7%25BD%2591%25E7%25BB%259C%25E7%2588%25AC%25E8%2599%25AB%25E7%259A%2584%25E5%25A5%25BD%25E5%25A4%2584&rsv_t=87f3Kz6nUiM7HXHQTzBpxWSGowc4u4IuzpZOSjJlWWAjkruEp0ZptPDzt43dqEfbewEw&rsv_btype=t&inputT=3469&rsv_pq=b71284a20002123b&rsv_sug3=39&rsv_sug1=31&rsv_sug7=100&rsv_sug2=0&rsv_sug4=69751414&rsv_sug=2
可以发现,对应的查询信息是通过 URL 传递的,这里采用的是 HTTP 请求中的 GET 方 法。其中字段 ie 的值为 utf-8,代表的是编码信息,而字段 wd 的值为 Python,代表的是用户检索的关键词。
- POST 请求实例分析
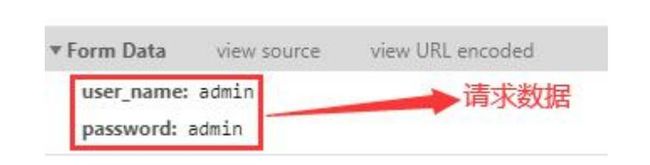
POST 请求则是常用在登录、注册等操作的时候,提交的数据放置在实体区内提交。下面展示一个完整的 POST 请求。图1是为大家提供的一个 POST 表单测试网页,输入用 户名和密码后点击登录。使用 F12 打开开发者工具,捕获的请求数据如图2所示:

- POST 请求与 GET 请求的区别
1、GET 请求,请求的数据会附加在 URL 之后,以?分割 URL 和传输数据,多个参数用&连接。POST 请求:POST 请求会把请求的数据放置在 HTTP 请求包的包体中。因此, GET 请求的数据会暴露在地址栏中,而 POST 请求则不会。
2、传输数据的大小对于 GET 请求方式提交的数据最多只能有 1024 字节,而 POST 请求没有限制。
3、安全性问题使用 GET 请求的时候,参数会显示在地址栏上,而 POST 请求不会。所以,如果这些数据是非敏感数据,那么使用 GET;如果用户输入的数据包含敏感数据,那么还是使用 POST 为好。
请求
Requests 是用 python 语言基于 urllib 编写的,采用的是 Apache2 Licensed 开源协议的 HTTP 库。
- Requests 库安装 以“管理员身份运行 cmd”,直接使用 pip 进行安装,语法格式如下:
pip install requests
若安装速度慢,推荐使用第三方下载:
pip install -i https://mirrors.aliyun.com/pypi/simple 模块名
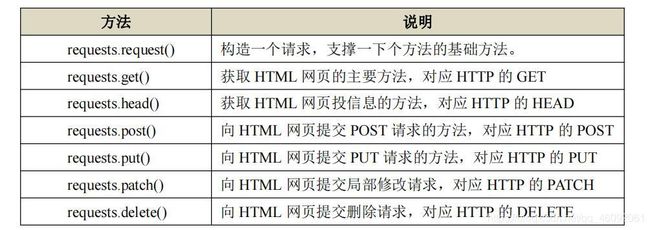
- Requests 库的 7 个主要方法:
- requests.request()
requests.request(method,url,**kwargs)
其中参数 method 表示请求方式,对应 get/put/post 等 7 种;url 表示获取页面的 url 链接; **kwargs 表示控制访问的参数,均为可选项。
- Requests 库的 get()方法
requests.get(url,params=None,**kwargs)
其中参数 url 表示获取页面的 url 链接;params 表示 url 中额外参数,字典或字节流格式,是可选参数;**kwargs 表示 12 个控制访问的参数。
响应
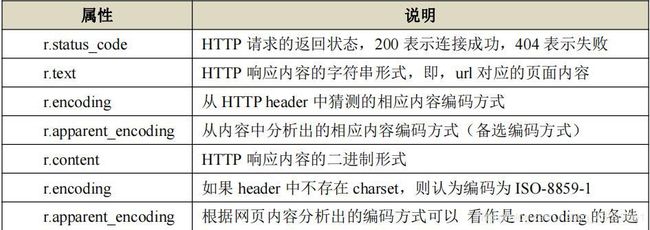
Response 对象包含服务器返回的所有信息,分为三部分:响应状态码、响应头、响应内容。
Response 的编码
- r.encoding : 从 HTTP header 中猜测的响应内容的编码方式;如果 header 中不存在 charset,则认为编码为 ISO-8859-1,r.text 根据 r.encoding 显示网页内容。
- r.apparent_encoding : 根据网页内容分析出的编码方式,可以看作 r.encoding 的备选。
第一个简单的爬虫
import requests
r = requests.get('http://www.baidu.com')
print('content:',r.content)
print('text:',r.text)
执行结果如下所示:
<!DOCTYPE html> <!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;
charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css
href=http://s1.bdstatic.com/r/www/cache/bdorz/baidu.min.css>
<title>ç™¾åº¦ä¸€ä¸‹ï¼Œä½ å°±çŸ ¥é� “</title></head>
<body link=#0000cc>
class=head_wrapper> <div class=s_form> <div
class=s_form_wrapper> <div id=lg> <img hidefocus=true
src=//www.baidu.com/img/bd_logo1.png width=270 height=129>
</div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1>
<input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <inputs_btn_wr">">