PCI Express学习篇---MSI/MSI-X中断
声明:此文章为原创,转载请注明 转自https://blog.csdn.net/weixin_48180416/article/details/115739848
PCIe支持传统中断、MSI中断、MSI-X中断。每个Function必须实现MSI或MSI-X,或两者同时支持。
PCIe最大支持32个MSI中断,2048个MSI-X中断。
以下介绍MSI中断
MSI Capability Structure是PCI-Compliance的配置空间
MSI Capability有四种形式: 32bit地址、64bit地址、带或不带Pending Mask
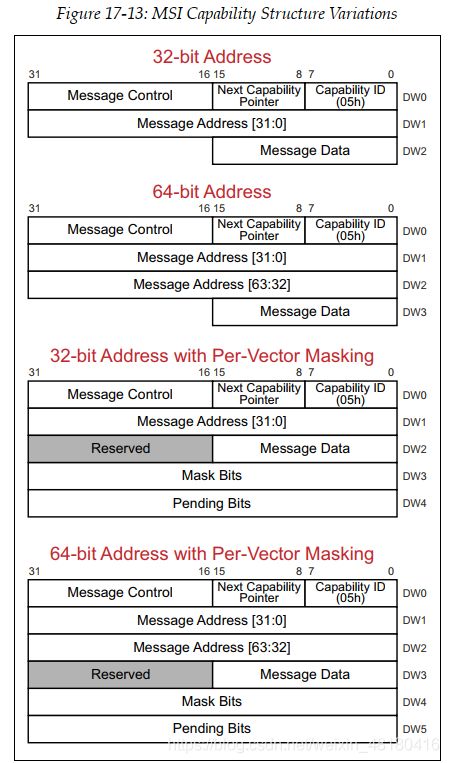

Message Control Register 包含总开关使能不使能MSI,支持多少个MSI,是32bit还是64bit,每个Vector是否屏蔽;
Mask Bit: 屏蔽对应vector的中断;bit[0]为1时屏蔽message 0
Pending Bit: 记录Pending中断,一旦Mask Bit变为0,就自动发pending bit对应vector的中断
配置MSI寄存器过程:
- 上电枚举后读MSI Capability,读到支持多少个MSI, 32bit or 64bit等信息,使能需要的MSI数量 至少一个MSI;
- 写message data和message address
- 最后使能MSI Enable
发起MSI过程:发起1DW长度的中断,data高16bit填0,低16bit来自于message data寄存器+Vector, 地址= message address
注: MSI中断的event id,即data字段必须是连续的,最多支持32个
以下介绍MSI-X中断
MSI-X相比于MSI的优点:
- 32个MSI中断数量不够用,MSI-X每个Function支持2048 vectors
- MSI地址是相同的,导致不同CPU时分配困难,MSI-X地址是独立的
- 在一些x86系统中,中断向量号表示的是优先级,MSI的event id(data)是连续的,表示的优先级是近似相等的,但是MSI-X的event id(data)可以是不连续的
MSI-X是PCIe Extend Capability的配置空间

BIR指的是相对哪个BAR,Offset是相对于这个BAR多少偏移可以找到MSI-X Table或PBA Table
MSI-X Table格式如下:
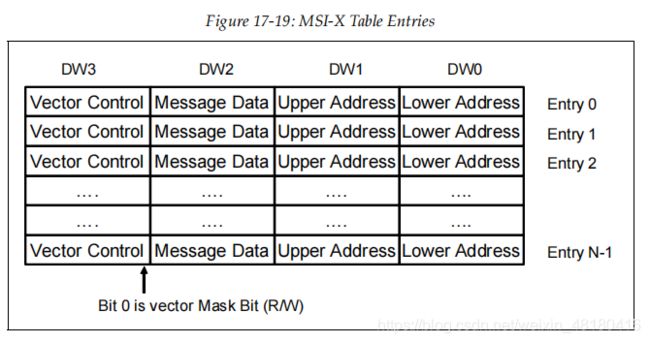
Vector Control字段bit0表示此Entry是否mask
Message Data和Address表示要发送的MSI中断的地址和数据(MSI-X配置发送的也是MSI TLP,实质就是一个MWr TLP)
以S家IP为例:
默认情况下,Table BIR、PBA BIR可以绑定到BAR0(修改配置也可以绑定到其他BAR)
- 软件会先读MSI-X Capability Structure, 但是不会改写BIR和offset (因为与下面的集成模块息息相关,改写后内部集成模块就找不到这两个Table了)
- 软件配置MSI-X Table,PBA Table的内容
- 软件Doorbell, 根据提供的Vector, PF, VF, TC, 内部集成模块发送MSI-X
内部集成了一个MSI-X发送模块

软件Doorbell有两种方法:
- 直接配置Doorbell寄存器,提供Vector、PF、TC、VF,写寄存器这个行为就会触发中断;(个人认为更简单)
- 通过AXI Slave发送MWr, addr与PL寄存器的地址Match,data为要覆盖doorbell寄存器的内容;
注意:
Vector指的Entry的索引,而Table中的Vec bit[0]为Mask bit,用于屏蔽每个Entry,不要混淆。
Pending Bit每个bit位对应的是Table的一个Entry
MSI/MSI-X Order问题:
Producer-Consumer模型:在下图这种模型的条件下,CPL不能超越P,否则数据还没有完全写入CPU就会开始Consume(处理)

这种中断方式属于轮询,MSI为MWr,与Posted data同属于Posted TLP,是不会发生乱序的情况的,也不需要其他规则
“与Posted data同属于Posted TLP,是不会发生乱序的情况的”是有前提的:
MSI和Posted Data必须有相同的TC,这样它们映射到同一个VC,才会有order的关系,不同的VC是没有order的
如果没有相同的TC,需要与Posted Data相同TC的"dummy read",保证Posted Data传输完毕(因为Non-P不可以超越P)
MSI TLP中的no-snoop和relaxed-ordering bit 必须是0