【hadoop】hadoop集群介绍 和 完全分布式部署步骤
文章目录
-
-
-
- 前言
- hadoop模式
- 搭建完全分布式
- 搭建思路
- 步骤
-
-
前言
这章我们来看一下hadoop的搭建
hadoop模式
hadoop部署模式有三种
-
1、单机:Hadoop的单机模式安装很简单,只需配置好环境变量即可运行,这个模式一般用来学习和测试Hadoop的功能
-
2、伪分布式:
伪分布式的安装和完全分布式类似,区别是所有角色安装在一台机器上,使用本地磁盘,一般生产环境都会使用完全分布式,伪分布式一般是用来学习和测试Hadoop的功能
伪分布式的配置和完全分布式配置类似 -
3、完全分布式
这章主要介绍搭建完全分布式
搭建完全分布式
集群规划:
| 地址 | 名字 |
|---|---|
| 192.168.25.70 | had-node2 |
| 192.168.25.71 | had-node3 |
| 192.168.25.72 | had-node4 |
集群底层的操作系统是Centos os7
java环境:jdk1.8
hadoop包:hadoop 2.6.5
搭建思路
1、准备三台虚拟机
2、配置好ip地址规划
3、禁用selinux
4、禁用firewalld
5、配置 /etc/hosts
6、ssh
7、安装jdk
8、安装hadoop
9、配置环境变量
步骤
1、准备三台虚拟机
2、配置好ip地址规划
用命令行的方式修改网络配置,进入 cd /etc/sysconfig/network-scripts/
vim ifcfg-ens33
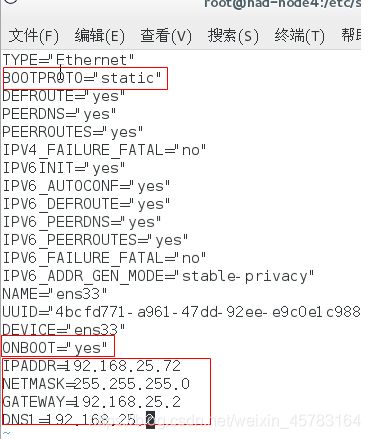
主要更改,注意红色框框的,包括
- 把 bootproto = static
- 还有onboot = yes
- ipaddr、netmask、还有gateway网关从虚拟网络适配器中查看
3、禁用selinux
#master、slave1、slave2
[root@had-node ~]# setenforce 0 # 将 SELinux 的状态临时设置为Permissive 模式(立即生效)
[root@had-node ~]# vi /etc/selinux/config
#编辑 config 文件将 SELINUX=enforcing 修改为 SELINUX=disabled(重启生效)
因为CentOS的所有访问权限都是有SELinux来管理的,为了避免我们安装中由于权限关系而导致的失败,需要先将其关闭,以后根据需要再进行重新管理。
4、禁用firewalld
#master、slave1、slave2
[root@had-node ~]# systemctl disable firewalld # 永久关闭防火墙(重启生效)
[root@had-node ~]# systemctl stop firewalld # 临时关闭防火墙(立即生效)
[root@had-node ~]# systemctl status firewalld # 检查修改
为避免由于防火墙策略导致安装失败问题,需要先关闭防火墙
5、配置 /etc/hosts
把我们的集群地址写进入,中间用 table 键隔开

6、ssh
#master、slave1、slave2
#生成ssh免密登录密钥
ssh-keygen –t rsa (四个回车)
执行完这个命令后,会生成id_rsa(私钥)、id_rsa.pub(公钥)
将公钥拷贝到要免密登录的目标机器上
ssh-copy-id had-node2
ssh-copy-id had-node3
ssh-copy-id hadnode4(也要发给自己的主机)
一般配置是从主节点到从节点
在配置免密登录时,先给主节点自己配置一个免密登录,因为后面一些程序在自己内部调用是需要免密登录的
7、安装jdk
- 卸载现有jdk
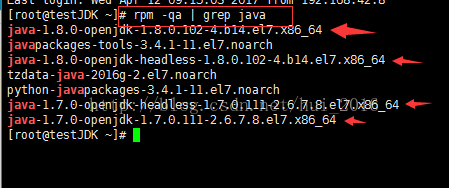
(1) 首先是,搜索或查找是否安装java软件:
[root@had-node ~]# rpm -qa | grep java //搜索命令
图片不符,就是理解下
(2) 卸载有openjdk jdk:
rpm -e --nodeps 后面跟系统自带的jdk名 这个命令来删除系统自带的jdk,
例如:rpm -e --nodeps java-1.8.0-openjdk-1.8.0.102-4.b14.el7.x86_64
rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.102-4.b14.el7.x86_64
rpm -e --nodeps java-1.7.0-openjdk-headless-1.7.0.111-2.6.7.8.el7.x86_64
rpm -e --nodeps java-1.7.0-openjdk-1.7.0.111-2.6.7.8.el7.x86_64
(3).删完再用 rpm -qa | grep java 或 rpm -qa | grep jdk 看一下是否删掉了

- 上传
- 用xftp把jdk的压缩包上传到相应目录
/usr/local/java - 在master上解压
- 用xftp把jdk的压缩包上传到相应目录
cd /usr/local/java
tar zxvf jdk1.8.0_152.tar.gz
- 配置jdk环境变量
#Executer in Master
vim /etc/profile
export JAVA_HOME=/usr/local/java/jdk1.8.0_152
export JAVA_BIN=/usr/local/java/jdk1.8.0_152/bin
export JRE_HOME=/usr/local/java/jdk1.8.0_152/jre
CLASSPATH=/usr/local/java/jdk1.8.0_152/jre/lib:/usr/local/java/jdk1.8.0_152/lib:/usr/local/java/jdk1.8.0_152/jre/lib/charsets.jar
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin

执行source /etc/profile使用生效
- JDK拷贝到Slave主机
#Executer in Master
scp -r /usr/local/java/jdk1.8.0_152 root@slave1:/usr/local/java/jdk1.8.0_152
scp -r /usr/local/java/jdk1.8.0_152 root@slave1:/usr/local/java/jdk1.8.0_152
同样要在另外两台had-node3 had-node4上更改环境变量,同上
- 验证查看java环境是否弄好了
Java –version

8、安装hadoop
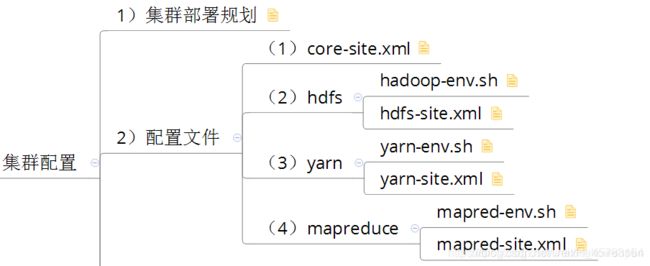
配置文件都在这个目录里面 cd /usr/local/hadoop/hadoop-2.6.5/etc/hadoop
- 下载安装包,给hadoop解压
用xftp把hadoop的压缩包上传到相应目录/usr/local/hadoop
#Master
[root@had-node java]# tar -zxvf hadoop-2.6.5.tar.gz //表示解压到当前目录下
(可以cd进hadoop-2.6.5看一下有没有解压成功)
- 添加JAVA_HOME环境到
hadoop-env.sh和yarn-env.sh
cd /usr/local/hadoop/hadoop-2.6.5/etc/hadoop(这个目录下是一些配置文件)
vim hadoop-env.sh
export JAVA_HOME=/usr/local/java/jdk1.8.0_152
vim yarn-env.sh
export JAVA_HOME=/usr/local/java/jdk1.8.0_152
- 修改配置文件
vim core-site.xml(指定namenode的地址)
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://had-node:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/hadoop-2.6.5/tmp</value>
</property>
</configuration>
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>had-node:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hadoop-2.6.5/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hadoop-2.6.5/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
vim yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>had-node:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>had-node:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>had-node:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>had-node:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>had-node:8088</value>
</property>
</configuration>
#创建临时目录和文件目录
mkdir /usr/local/hadoop/hadoop-2.6.5/tmp
mkdir -p /usr/local/hadoop/hadoop-2.6.5/dfs/name
mkdir -p /usr/local/hadoop/hadoop-2.6.5/dfs/data
- 编辑slaves文件:
清空slaves,再加入从节点的名字
vim slaves
slave1
slave2
- 拷贝安装包
#Master
scp -r /usr/local/hadoop/hadoop-2.6.5 root@slave1:/usr/local/hadoop/hadoop-2.6.5
scp -r /usr/local/hadoop/hadoop-2.6.5 root@slave2:/usr/local/hadoop/hadoop-2.6.5
9、配置环境变量
#Master、Slave1、Slave2
vim /etc/profile
HADOOP_HOME=/usr/local/hadoop/hadoop-2.6.5
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
![]()
#刷新环境变量
source /etc/profile
10、启动集群
- 初始化namenode
#Master
#初始化Namenode
hadoop namenode -format
- 启动集群
./sbin/start-all.sh
- 终止服务器
./sbin/hadoop stop-all.sh
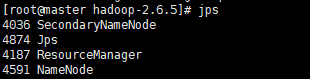
- 查看集群状态
Jps