以官方Hadoop中的 WordCount案例分析 ,Job作业的提交过程:
public static void main(String[] args) throws Exception {
// Create a new Job
Configuration conf=new Configuration(true);
Job job = Job.getInstance(conf);
job.setJarByClass(MyWorkCountJob.class);
// Specify various job-specific parameters
job.setJobName("myWorkCountjob");
//设置输入文件路径
FileInputFormat.addInputPath(job, new Path("/user/root/hello.txt"));
//设置输出文件路径
Path outPath=new Path("/sxt/mr/output");
if(FileSystem.get(conf).exists(outPath))
FileSystem.get(conf).delete(outPath);
FileOutputFormat.setOutputPath(job, outPath);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// Submit the job, then poll for progress until the job is complete
job.waitForCompletion(true);//job 提交的入口
}
waitForCompletion方法
public boolean waitForCompletion(boolean verbose
) throws IOException, InterruptedException,
ClassNotFoundException {
if (state == JobState.DEFINE) {
submit();// 任务提交1.1
}
if (verbose) {
monitorAndPrintJob();//实时监控Job任务并打印相关的日志
} else {
// get the completion poll interval from the client.
int completionPollIntervalMillis =
Job.getCompletionPollInterval(cluster.getConf());
while (!isComplete()) {
try {
Thread.sleep(completionPollIntervalMillis);
} catch (InterruptedException ie) {
}
}
}
return isSuccessful();
}
1.1 submit 方法
public void submit()
throws IOException, InterruptedException, ClassNotFoundException {
ensureState(JobState.DEFINE);//确定job状态
setUseNewAPI();//默认使用新的API
connect();//获得与集群的连接
final JobSubmitter submitter =
getJobSubmitter(cluster.getFileSystem(), cluster.getClient());
status = ugi.doAs(new PrivilegedExceptionAction() {
public JobStatus run() throws IOException, InterruptedException,
ClassNotFoundException {
//异步调用submitJobInternal方法提交任务 1.2
return submitter.submitJobInternal(Job.this, cluster);
}
});
state = JobState.RUNNING;
LOG.info("The url to track the job: " + getTrackingURL());
}
submit方法首先创建了JobSubmitter实例,然后异步调用了JobSubmitter的submitJobInternal方法
1.2 submitJobInternal 方法
JobStatus submitJobInternal(Job job, Cluster cluster)
throws ClassNotFoundException, InterruptedException, IOException {
//检查job的输出路径是否存在,如果存在则抛出异常
checkSpecs(job);
Configuration conf = job.getConfiguration();
addMRFrameworkToDistributedCache(conf);
//初始化临时目录和返回的输出路径。
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);
//configure the command line options correctly on the submitting dfs
InetAddress ip = InetAddress.getLocalHost();
if (ip != null) {
submitHostAddress = ip.getHostAddress();
submitHostName = ip.getHostName();
conf.set(MRJobConfig.JOB_SUBMITHOST,submitHostName);
conf.set(MRJobConfig.JOB_SUBMITHOSTADDR,submitHostAddress);
}
//获取新的JobId
JobID jobId = submitClient.getNewJobID();
job.setJobID(jobId);
// 获取提交目录
Path submitJobDir = new Path(jobStagingArea, jobId.toString());
......
//把作业上传到集群中去
copyAndConfigureFiles(job, submitJobDir);
Path submitJobFile = JobSubmissionFiles.getJobConfPath(submitJobDir);
// 创建切片列表 找出每个文件的切片列表 合并切片列表的数量就是Map任务个数 客户端统计
int maps = writeSplits(job, submitJobDir); //2.1核心方法
conf.setInt(MRJobConfig.NUM_MAPS, maps);//文件分片的大小 就是Map任务数量
......
// Write job file to submit dir 相关配置写入到job.xml中
writeConf(conf, submitJobFile);
// Now, actually submit the job (using the submit name) 真正的提交作业
status = submitClient.submitJob( //2.3 提交job到RecourceManager
jobId, submitJobDir.toString(), job.getCredentials());
...
}
2.1 文件切片操作 writeSplits -> writeNewSplits 计算向数据移动模型的核心
private
int writeNewSplits(JobContext job, Path jobSubmitDir) throws IOException,
InterruptedException, ClassNotFoundException {
Configuration conf = job.getConfiguration();
InputFormat input =
ReflectionUtils.newInstance(job.getInputFormatClass(), conf);
List splits = input.getSplits(job);
T[] array = (T[]) splits.toArray(new InputSplit[splits.size()]);
// sort the splits into order based on size, so that the biggest
// go first
Arrays.sort(array, new SplitComparator());
//将split信息和SplitMetaInfo都写入HDFS中
JobSplitWriter.createSplitFiles(jobSubmitDir, conf,
jobSubmitDir.getFileSystem(conf), array);
return array.length;
}
writeNewSplits方法中,划分任务数量最关键的代码即为InputFormat的getSplits方法(InputFormat有不同实现类 框架默认的是TextInputFormat)。此时的Input即为TextInputFormat的父类FileInputFormat,其getSplits方法的实现如下:
public List getSplits(JobContext job) throws IOException {
Stopwatch sw = new Stopwatch().start();
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));//默认最小值 1
long maxSize = getMaxSplitSize(job);//默认最大值 Long类型的最大值
// generate splits
List splits = new ArrayList();
List files = listStatus(job);//获取源文件的源信息列表
for (FileStatus file: files) {
Path path = file.getPath();
long length = file.getLen();
if (length != 0) {
BlockLocation[] blkLocations;
//获取文件的block块列表
if (file instanceof LocatedFileStatus) {
blkLocations = ((LocatedFileStatus) file).getBlockLocations();
} else {
FileSystem fs = path.getFileSystem(job.getConfiguration());
blkLocations = fs.getFileBlockLocations(file, 0, length);
}
if (isSplitable(job, path))
long blockSize = file.getBlockSize();
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
//核心代码块
long bytesRemaining = length;
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
bytesRemaining -= splitSize;
}
//核心代码块结束
if (bytesRemaining != 0) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
}
} else { // not splitable
splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts(),
blkLocations[0].getCachedHosts()));
}
} else {
//Create empty hosts array for zero length files
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
// Save the number of input files for metrics/loadgen
job.getConfiguration().setLong(NUM_INPUT_FILES, files.size());
sw.stop();
if (LOG.isDebugEnabled()) {
LOG.debug("Total # of splits generated by getSplits: " + splits.size()
+ ", TimeTaken: " + sw.elapsedMillis());
}
return splits;
}
2.2 核心代码块分析
对每个输入文件进行split划分。注意这只是个逻辑的划分 因此执行的是FileInputFormat类中的getSplits方法。只有非压缩的文件和几种特定压缩方式压缩后的文件才分片。分片的大小由如下几个参数决定:mapreduce.input.fileinputformat.split.maxsize、mapreduce.input.fileinputformat.split.minsize、文件的blocksize大小确定。
具体计算方式为:
Math.max(minSize, Math.min(maxSize, blockSize))
分片的大小有可能比默认块大小64M要大,当然也有可能小于它,默认情况下分片大小为当前HDFS的块大小,64M
第一步 将bytesRemaining(剩余未分片字节数)初始化设置为整个文件的长度
第二步 如果bytesRemaining超过分片大小splitSize一定量才会将文件分成多个InputSplit,SPLIT_SLOP(默认1.1)。接着就会执行如下方法获取block的索引,其中第二个参数是这个block在整个文件中的偏移量
protected int getBlockIndex(BlockLocation[] blkLocations,
long offset) {
for (int i = 0 ; i < blkLocations.length; i++) {
// is the offset inside this block? 核心代码块 判断当前的偏移量是否在某个block中 是就返回当前index 位置信息
if ((blkLocations[i].getOffset() <= offset) &&
(offset < blkLocations[i].getOffset() + blkLocations[i].getLength())){
return i;
}
}
BlockLocation last = blkLocations[blkLocations.length -1];
long fileLength = last.getOffset() + last.getLength() -1;
throw new IllegalArgumentException("Offset " + offset +
" is outside of file (0.." +
fileLength + ")");
}
第三步 将符合条件的块的索引对应的block信息的主机节点以及文件的路径名、开始的偏移量、分片大小splitSize封装到一个InputSplit中加入List
第四步 bytesRemaining -= splitSize修改剩余字节大小 循环以上操作 直到不满足条件 剩余bytesRemaining还不为0,表示还有未分配的数据,将剩余的数据及最后一个block加入splits列表
以上是 整个getSplits获取切片的过程。当使用基于FileInputFormat实现InputFormat时,为了提高MapTask的数据本地化,应尽量使InputSplit大小与block大小相同
2.3 submitter 实现了ClientProtocol接口的类 在1.1中connect()连接集群时 调用init初始化方法 由框架读取 HDFS的配置文件中配置了mapreduce.framework.name属性为“yarn”的话,会创建一个YARNRunner对象 submitter 就是YARNRunner 对象
submitter.submitJobInternal(Job.this, cluster)
YARNRunner的构造方法:
public YARNRunner(Configuration conf, ResourceMgrDelegate resMgrDelegate,
ClientCache clientCache) {
this.conf = conf;
try {
this.resMgrDelegate = resMgrDelegate;
this.clientCache = clientCache;
this.defaultFileContext = FileContext.getFileContext(this.conf);
} catch (UnsupportedFileSystemException ufe) {
throw new RuntimeException("Error in instantiating YarnClient", ufe);
}
}
ResourceMgrDelegate实际上ResourceManager的代理类,其实现了YarnClient接口,通过ApplicationClientProtocol代理直接向RM提交Job,杀死Job,查询Job运行状态等操作。
YarnRunner 类的submitJob方法
public JobStatus submitJob(JobID jobId, String jobSubmitDir, Credentials ts)
throws IOException, InterruptedException {
addHistoryToken(ts);
// Construct necessary information to start the MR AM
//Client构造ASC。ASC中包括了调度队列,优先级,用户认证信息,除了这些基本的信息之外,还包括用来启动AM的CLC信息,一个CLC中包括jar包、依赖文件、安全token,以及运行任务过程中需要的其他文件
ApplicationSubmissionContext appContext =
createApplicationSubmissionContext(conf, jobSubmitDir, ts);
// Submit to ResourceManager
try {
ApplicationId applicationId =
resMgrDelegate.submitApplication(appContext); // 2.4 提交ASC到RecoureManeger
ApplicationReport appMaster = resMgrDelegate
.getApplicationReport(applicationId);
String diagnostics =
(appMaster == null ?
"application report is null" : appMaster.getDiagnostics());
if (appMaster == null
|| appMaster.getYarnApplicationState() == YarnApplicationState.FAILED
|| appMaster.getYarnApplicationState() == YarnApplicationState.KILLED) {
throw new IOException("Failed to run job : " +
diagnostics);
}
return clientCache.getClient(jobId).getJobStatus(jobId);
} catch (YarnException e) {
throw new IOException(e);
}
}
2.4 到这里一个Client就完成了一次Job任务的提交
2.5 YARN 框架 统一的资源管理 任务调度
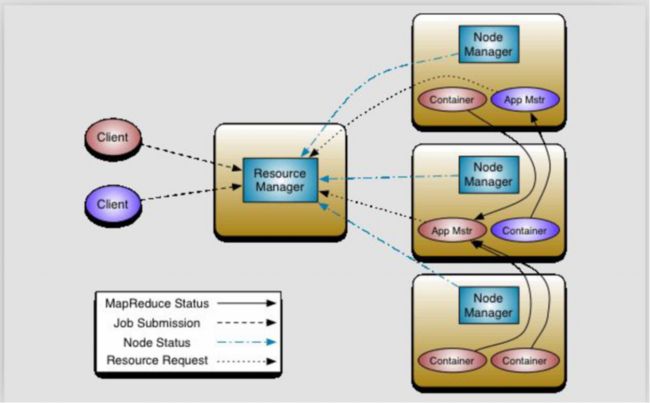
相关的角色
**ResourceManager **
集群节点资源的统一管理
**NodeManager ** 每个DN上都会对应一个NM进程
- 与RM汇报资源的使用情况
- 管理运行的Container生命周期
Container:【节点NM上CPU,MEM,I/O大小等资源的虚拟描述】
MR-ApplicationMaster-Container
每个Job作业对应一个AM,避免单点故障,负载到不同的节点
创建Task时需要和RM申请资源(Container),然后向存放具体资源的DN通信,由DN创建Container并且启动进程同时下发任务(这里就实现了计算向数据移动)
Task-Container 任务执行进程
DN上执行的JVM进程,接收到AM下发的任务后,通过反射机制创建具体的任务对象后 执行具体的任务
** 执行流程**
1 RM 在空闲的DN 上启动AM
2 AM向RM申请资源 ,RM将资源分配信息给AM
3 AM在和数据所在的NM节点通信,创建Container并且通知NM启动Container(JVM进程),分发具体任务到NM上,Container通过反射调起具体的任务类执行
4 如果是MapReduce框架 则进入到MapTask流程 具体分析见 http://liujiacai.net/blog/2014/09/07/yarn-intro/