增(create)删(delete)改(update)查(Retrieve)
一、
数据库(database) 是存储数据的仓库,简称DB
DBMS(databaseManagers)数据库管理的软件 (其实我们今天安装的就是DBMS,数据库是里面的一部分内容。)
数据库的发展史就是计算机的发展史
关系型数据库和nosql数据库的发展
主流的关系型数据库:(access ,mysql,Oracle,sql server ,postgreSQL)
二、常见DDL语句
ddl ==> 数据库定义语言(database defined language)
dml ==> 数据库操作语言 sql (database make language)
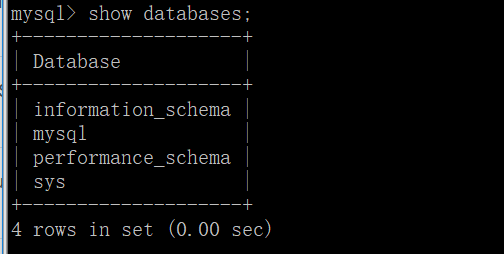
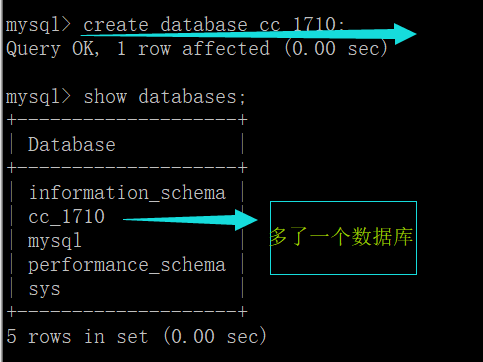
show databases; # 显示当前数据库管理软件下的所有数据库
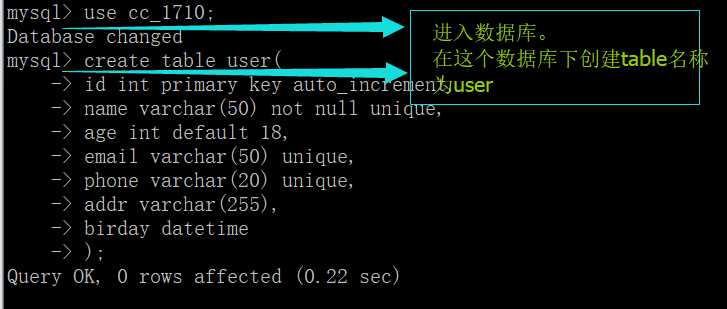
use xxx数据库名称; # 进入到某个数据库
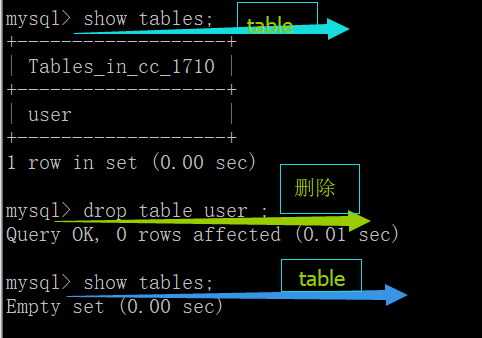
show tables; # 显示当前数据库中的所有表
desc 表名; # 查看某表的结构。
show databases
use 数据库名称

show tables

create database 数据库名称
drop databse 数据库名称

create table 表名称(
字段1 类型 [约束条件],
字段2 类型 [约束条件]
……
字段n 类型 [约束条件]
);
注意,最后一个没有逗号。多个约束条件用空格隔开。
eg:
create table user(
id int primary key auto_increment,
name varchar(50) not null unique,
age int default 18,
email varchar(50) unique,
phone varchar(20) unique,
addr varchar(255),
birday datetime
);
auto_increment :自动加1
drop table user 删除表名为user的表。
drop table if exists 表名称 (如果存在删除这个表格)
删除这个table名称为user的表格
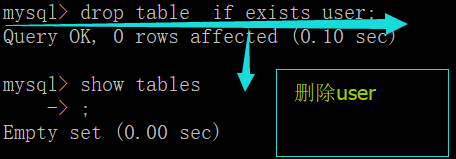
desc 表名
三、Mysql的数据类型
1、整数 int (这个最多11位)
2、浮点数 float double decimal
decimal(5,2) 整数位最多是3位,小数位最多是2位
3、字符串 char varchar
char(10) 10个字符长度,用不完,也是10个长度
varchar(10) 10个字符长度,用多少,是多少长度
4、文本类型 text 不用写东西,直接一个text即可。
5、日期 data(只能表示年月日)、time (只能表示时分秒)、datatime(年月日时分秒)
6、binary 二进制 block
7、布尔 bit
约束条件:
目的:保证数据的正确性。
1.主键primary key,默认是唯一
2.非空not null
3.惟一unique
4.默认default
5.外键foreign key
三、Mysql的CRUD(增删改查)
一定要写where条件,不写where条件表示修改全表数据,这个可不是闹着玩滴小伙子。
增加(create)
insert into 表名(字段1,字段2,字段3,……,字段n) values(值1,值2,值3,……,值n)
eg:insert into user(name,id,age,email,phone,addr,birday) values("zs",null,16,"[email protected]","110",'zz','1990-08-23');
insert into user values("zs",null,16,"[email protected]","110",'zz','1990-08-23'); 简写形式,但是要一一对应。
删除(delete)
delete from 表名 where 条件
不带where条件表示清空全表。
修改(update)
update 表名 字段1=新值1,字段2=新值2,…… where 条件
查询(tetrieve)
select 字段1,字段2…… from 表名 [where 条件]
eg:select id,name,age,email,phone,addr,birday from user;
select id,name,age from user; (也可以查询部分)
select * from user; (*表示查询所有)
alter 修改表的结构
alter table 表名 add 新的字段 类型
alter table 表名 drop 字段名称
drop table tagName 清除表的结构。这个表完全不存在了。
删除表数据3种方法:
delete from 表名 where 条件 删除的是表的数据,不删除标的结构。表一直存在。
再次添加会占位,有里面有字典记录,id接着下后面写。
truncate [table] 表名称 删除的是表的数据,不删除标的结构。
这个再次添加,id从1开始。相当于格式化。
alter table 表名 drop 表名称
三个创建:
create database dbName
create table tbName(数据,type,【约束条件】)
create视图,或者索引
eg :创建一个视图
1.1.1视图
·对于复杂的查询,在多次使用后,维护是一件非常麻烦的事情
·解决:定义视图
·视图本质就是对查询的一个封装,虚拟的表,一旦封装的内容改变了,视图的内容也随着用
·定义视图
create view stuscore as
select students.*,scores.score from scores
inner join students on scores.stuid=students.id;
·视图的用途就是查询
select * from stuscore;
四个语句:
增(create)删(delete)改(update)查(Retrieve)
五种约束:
1.主键primary key,默认是唯一
2.非空not null
3.惟一unique
4.默认default
5.外键foreign key
check()这个约束条件在mysql中不生效
数据库对象:
表 ,视图 ,索引,函数,过程,触发器 。etc还有好多
sql: 结构化查询语言
名词:字段也就是列 ,记录(对象)也就是行
五种多表查询:
1、内连接:
相等连接
不相等连接
2、外连接:
左连接
右连接
3、交叉连接
4、自然连接
5、自连接
E-R模型
当前物理的数据库都是按照E-R模型进行设计的
E表示entry,实体
R表示relationship,关系
一个实体转换为数据库中的一个表
关系描述两个实体之间的对应规则,包括
1.一对一
合法的情况下:一个男人娶一个女人,一个女人嫁一个男人
2.一对多
目前教室里,一个老师教多个学生,一个学生被一个老师教
一个教室里有很多学生,一个学生只能一个教室
3.多对多
在大学中,一个学生选很多课程,一个课程被学生选
在大学里,一个学生可以有很多老师,一个老师可以教很多学生
关系转换为数据库表中的一个列在关系型数据库中一行就是一个对象
三范式
对于设计数据库提出了一些规范,这些规范被称为范式。在一定程度上,为了提高访问性能,可以允许一定的冗余。
1.第一范式(1NF)
所谓第一范式(1NF)是指在关系模型中,对域添加的一个规范要求,所有的域都应该是原子性的,即数据库表的每一列都是不可分割的原子数据项,而不能是集合,数组,记录等非原子数据项。即实体中的某个属性有多个值时,必须拆分为不同的属性。在符合第一范式(1NF)表中的每个域值只能是实体的一个属性或一个属性的一部分。
简而言之,第一范式就是无重复的域。
说明:在任何一个关系数据库中,第一范式(1NF)是对关系模式的设计基本要求,一般设计中都必须满足第一范式(1NF)。不过有些关系模型中突破了1NF的限制,这种称为非1NF的关系模型。换句话说,是否必须满足1NF的最低要求,主要依赖于所使用的关系模型。
2.第二范式(2NF)
在1NF的基础上,非码属性必须完全依赖于候选码(在1NF基础上消除非主属性对主码的部分函数依赖)
第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。第二范式(2NF)要求数据库表中的每个实例或记录必须可以被唯一地区分。选取一个能区分每个实体的属性或属性组,作为实体的唯一标识。例如在员工表中的身份证号码即可实现每个一员工的区分,该身份证号码即为候选键,任何一个候选键都可以被选作主键。在找不到候选键时,可额外增加属性以实现区分,如果在员工关系中,没有对其身份证号进行存储,而姓名可能会在数据库运行的某个时间重复,无法区分出实体时,设计辟如ID等不重复的编号以实现区分,被添加的编号或ID选作主键。(该主键的添加是在ER设计时添加,不是建库时随意添加)
第二范式(2NF)要求实体的属性完全依赖于主关键字。所谓完全依赖是指不能存在仅依赖主关键字一部分的属性,如果存在,那么这个属性和主关键字的这一部分应该分离出来形成一个新的实体,新实体与原实体之间是一对多的关系。为实现区分通常需要为表加上一个列,以存储各个实例的唯一标识。
简而言之,第二范式就是在第一范式的基础上属性完全依赖于主键。
第三范式(3NF)
在1NF基础上,任何非主属性不依赖于其它非主属性(在2NF基础上消除传递依赖)
第三范式(3NF)是第二范式(2NF)的一个子集,即满足第三范式(3NF)必须满足第二范式(2NF)。简而言之,第三范式(3NF)要求一个关系中不包含已在其它关系已包含的非主关键字信息。例如,存在一个部门信息表,其中每个部门有部门编号(dept_id)、部门名称、部门简介等信息。那么在员工信息表中列出部门编号后就不能再将部门名称、部门简介等与部门有关的信息再加入员工信息表中。如果不存在部门信息表,则根据第三范式(3NF)也应该构建它,否则就会有大量的数据冗余。