今年,Spanner 终于发了另一篇 Paper Spanner: Becoming a SQL System,里面提到 Spanner 使用了一直新的存储格式 - Ressi,用来支持 OLTP 和 OLAP。在 Ressi 里面,使用了 PAX 来组织数据。因为 TiDB 定位就是一个 HTAP 系统,所以我也一直在思考在 TiKV 这层如何更好的存储数据,用来满足 HTAP 的需要,既然 Spanner 使用了 PAX,那么就有研究的必要了。
PAX 的论文可以看看 Weaving Relations for Cache Performance 或者 Data Page Layouts for Relational Databases on Deep Memory Hierarchies。
NSM and DSM
在谈 PAX 之前,NSM 和 DSM 还是绕不开的话题,NSM 就是通常说的行存,对于现阶段很多偏重 OLTP 的数据,譬如 MySQL 等,都采用的这种方式存储的数据。而 DSM,则是通常的说的列存,几乎所有的 OLAP 系统,都采用的这种方式来存储的底层数据。

NSM 会将 record 依次在磁盘 page 里面存放,每个 page 的末尾会存放 record 的 offset,便于快速的定位到实际的 record。如果我们每次需要得到一行 record,或者 scan 所有 records,这种格式非常的高效。但如果我们的查询,仅仅是要拿到 record 里面的一列数据,譬如 select name from R where age < 40,那么对于每次 age 的遍历,除了会将无用的其他数据一起读入,每次读取 record,都可能会引起 cache miss。

不同于 NSM,DSM 将数据按照不同的 attributes 分别存放到不同的 page 里面。对于上面只需要单独根据某一个 attribute 进行查询的情况,我们会直接读出page,遍历处理,这个对 cache 也是非常高效友好的。
但是,如果一个查询会涉及到多个不同的 attributes,那么我们就可能需要多次 IO 来组合最终的 tuple。同时,对于写入,DSM 因为会将不同的 attributes 对应的数据写到不同的 page,也会造成较多的随机 IO。
PAX
可以看到,NSM 和 DSM 都有各自的优劣,所以如何将它们和优点结合起来,就是现在很多 hybrid storage 包括 PAX 考虑的问题。
PAX 全称是 Partition Attributes Across,它在 page 里面使用了一种 mini page 的方式,将 record 切到到不同的 mini page 里面。
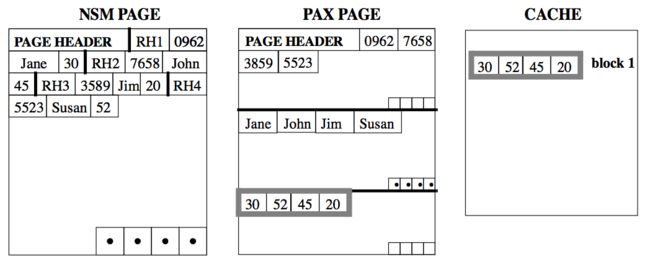
假设有 n 个 attributes,PAX 就会将 page 分成 n 个 mini pages,然后将第一个 attribute 的放在第一个 mini page 上面,第二个放在第二个 mini page,以此类推。

在每个 page 的开头,会存放每个 mini page 的 offset,mini page 对于 Fixed-length attribute 的数据,会使用 F-minipage ,而对于 variable-length attribute 的数据,则会使用 V-minipage。对于 F-minipage 来说,最后会有一个 bit vector 来存放 null value。而对于 V-minipage 来说,最后会保存每个每个 value 的在 mini page 里面的 offset。
可以看到,PAX 的格式其实是 NSM 和 DSM 的一种折中,当要依据某一列进行 scan 的时候,我们可以方便的在 mini page 里面顺序扫描,充分利用 cache。而对于需要访问多 attributes 得到最终 tuple 的时候,我们也仅仅是需要在同一个 page 里面的 mini page 之间读取相关的数据。
Data Manipulation
Insert
当数据插入的时候,PAX 会首先生成一个新的 page,然后根据 attribute 的 value size 分配好不同的 mini page, 这里需要注意下 variable-length value,因为它们的长度是不固定的,PAX 会使用一些 hint 来得到一个平均的 size。插入一个 record 的时候,PAX 会将这个 record 里面的数据分别 copy 到不同的 mini page 上面。如果一个 record 还能插入到这个 page,但这个 record 里面某一个 attribute 的数据不能插入到对应的 mini page 了,PAX 会重新调整不同 mini page 的 boundary。如果一个 page 已经 full 了,那么 PAX 就会重新分配一个 page。
Update
当数据更新的时候,PAX 会首先计算这个 record 需要更新的 attributes 在不同 mini page 里面的 offset,对于 variable-length value 来说,如果更新的数据大小超出了 mini page 可用空间,mini page 就会尝试向周围的 mini page 借一点空间。如果邻居也没有额外的空间了,那么这个 record 就会被移到新的 page 上面。
Delete
当数据删除的时候,PAX 会在 page 最开始会维护一个 bitmap,用来标记删除的数据。当删除标记越来越多的时候,就可能会影响性能,因为会导致 mini page 里面出现很多 gap,并不能高效的利用 cache。所以 PAX 会定期去对文件重新组织。
小结
PAX 其实是一个原理比较简单的东西,但它并没有成为一个业界主流的存储方案,应该有一些局限是我现在还不知道的。但既然 Spanner 敢用,证明在 HTAP 领域,PAX 也是一个可选择的方案,对我们后续 HTAP storage 的技术选型也有一定的指导作用。这里也就先记录一下,也希望能跟这方面有经验的同学多多交流下心得体会。