百度图神经网络7日打卡营--DAY01前半部分 总结
首先很感谢百度AI团队这个平台,给大家请来世界级冠军来给大家做这一次的7日打卡营活动, 还提供免费的GPU算力平台,以及成熟可用的 包含刷新目前 最权威的 图神经ORB榜单的SOTA模型的 PGL 图神经网络算法框架库,我对这几天上课的心得做一个总结,方便大家排坑。
2019年可以说是图神经网络开始兴起的一年,去年早就被各种炫酷的图神经网络技术吸引,既然是开篇,那我就先来介绍一下什么是图神经网络。
01 什么是图神经网络?
1. 图和属性图
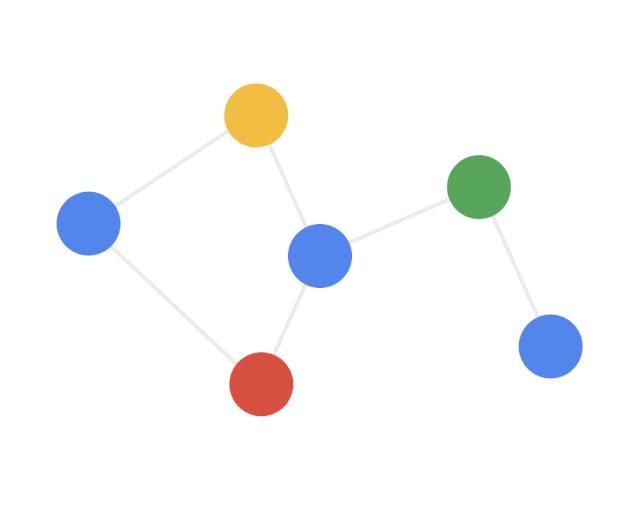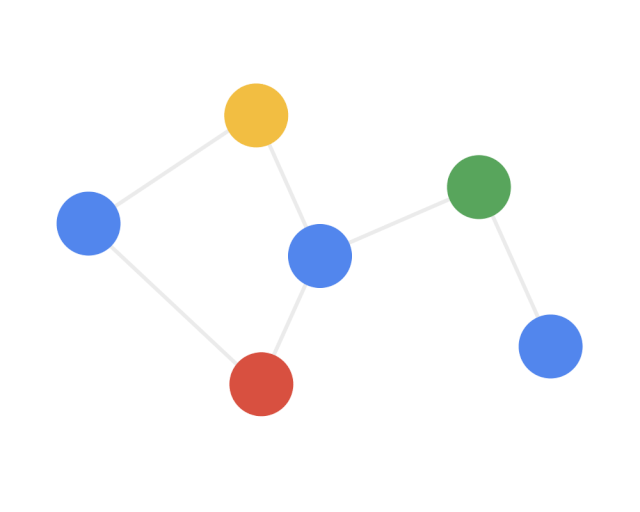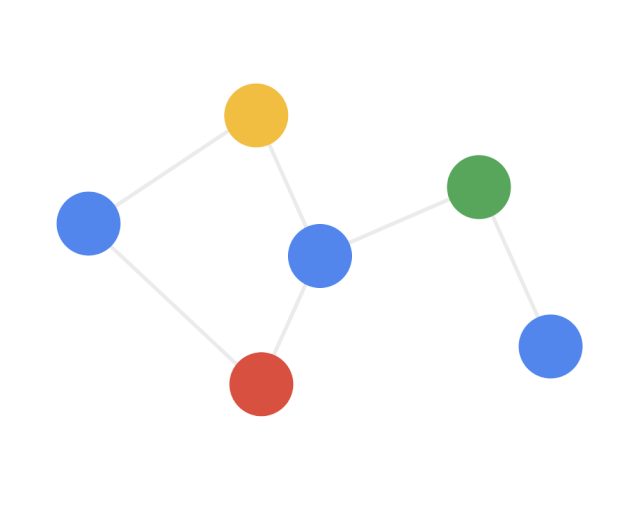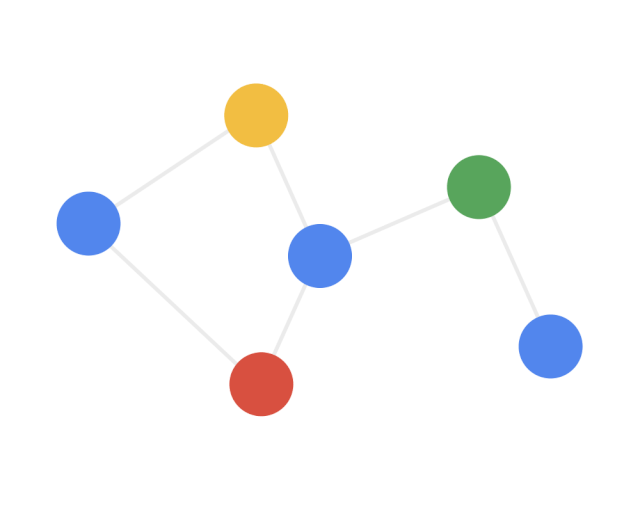
要了解图神经网络,首先要了解图。图是由节点和边组成的,如下图所示。一般图中的节点表示实体对象(比如一个用户、一件商品、一辆车、一张银行卡等都可以作为节点),边代表事件或者实体之间的特殊关系(比如用户和商品之间的购买关系)。

在数学中,我们一般使用邻接矩阵来表示图,如上图右边所示。邻接矩阵中的值为 1 表示节点之间有边,即有连接关系。所以邻接矩阵其实很好的将图的这种结构信息表达出来了。
还要介绍一个概念是属性图。就是说,图中的节点和边都带有属性(这是一种信息)。如下图所示:
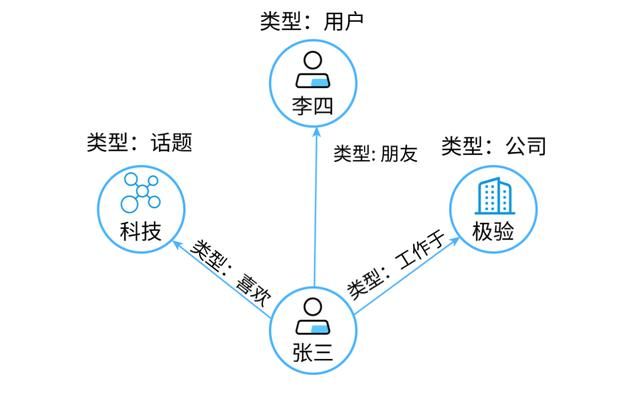
这个图里的用户节点有姓名、性别,话题节点具体的话题类别,公司节点有名称,注册时间等属性信息。边也可以有属性信息,比如开始工作时间是边“工作于”的一种属性。所以,属性图就是节点和边带有自己的属性信息,同时每个节点又有自己的拓扑结构信息。这是工业界最常用的一种图表示方法,因为我们需要更丰富的信息。
前几年神经网络很火,相信大家对神经网络都有一定的了解。图神经网络就是将图数据和神经网络进行结合,在图数据上面进行端对端的计算。
2. 图神经网络的计算机制
单层的神经网络计算过程:
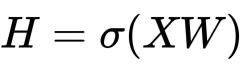
相比较于神经网络最基本的网络结构全连接层(MLP),特征矩阵乘以权重矩阵,图神经网络多了一个邻接矩阵。计算形式很简单,三个矩阵相乘再加上一个非线性变换。
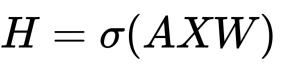
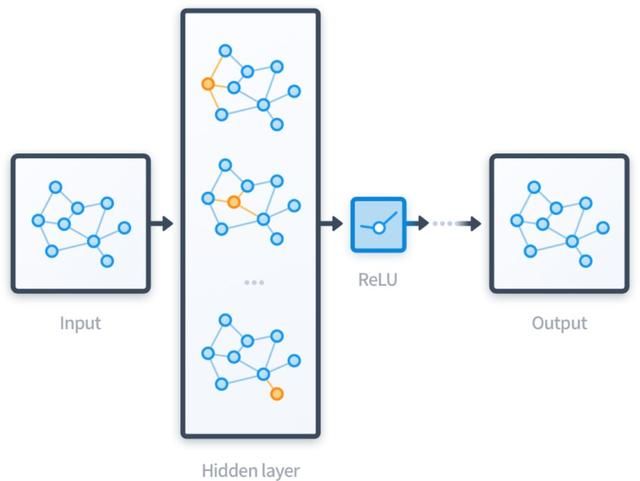
图神经网络的计算过程总结起来就是聚合邻居。如下面的动图所示,每个节点都在接收邻居的信息。为了更加全面的刻画每个节点,除了节点自身的属性信息,还需要更加全面的结构信息。所以要聚合邻居,邻居的邻居.....
图神经网络是直接在图上进行计算,整个计算的过程,沿着图的结构进行,这样处理的好处是能够很好的保留图的结构信息。而能够对结构信息进行学习,正是图神经网络的能力所在,下面我们就来看看图神经网络为什么强大?
2. 基本思想
图神经网络的一个基本思想,就是基于节点的局部邻居信息对节点进行embedding。直观来讲,就是通过神经网络来聚合每个节点及其周围节点的信息。
02 图神经网络的强大能力
现实生活中的大量的业务数据都可以用图来表示。万事万物皆有联系,节点+关系这样一种表示足以包罗万象。
比如人类的社交网络,个体作为节点,人与人之间的各种关系作为边;电商业务中,用户和商品也可以构建成图网络;而物联网、电网、生物分子这些是天然的节点+关系结构;甚至,可以将实物物体抽象成 3D 点云,以图数据的形式来表示。图数据可以说是一种最契合业务的数据表达形式。
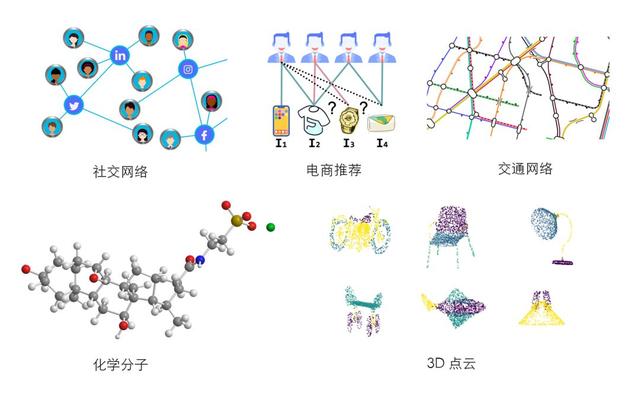
图神经网络的强大能力我认为可以归纳为三点:
- 对图数据进行端对端学习
- 擅长推理
- 可解释性强
1. 端对端学习
近几年,深度学习带来了人脸识别、语音助手以及机器翻译的成功应用。这三类场景的背后分别代表了三类数据:图像、语音和文本。
深度学习在这三类场景中取得突破的关键是它背后的端对端学习机制。端对端代表着高效,能够有效减少中间环节信息的不对称,一旦在终端发现问题,整个系统每一个环节都可以进行联动调节。
既然端对端学习在图像、语音以及文本数据上的学习是如此有效,那么将该学习机制推广到具有更广泛业务场景的图数据就是自然而然的想法了。
这里我们引用 DeepMind 论文中的一段话,来说明其重要性:
我们认为,如果 AI 要实现人类一样的能力,必须将组合泛化(combinatorial generalization)作为重中之重,而结构化的表示和计算是实现这一目标的关键。正如生物学里先天因素和后天因素是共同发挥作用的,我们认为“人工构造”(hand-engineering)和“端到端”学习也不是只能从中选择其一,我们主张结合两者的优点,从它们的互补优势中受益。
2. 擅长推理
业界认为大规模图神经网络是认知智能计算强有力的推理方法。图神经网络将深度神经网络从处理传统非结构化数据(如图像、语音和文本序列)推广到更高层次的结构化数据(如图结构)。
大规模的图数据可以表达丰富和蕴含逻辑关系的人类常识和专家规则,图节点定义了可理解的符号化知识,不规则图拓扑结构表达了图节点之间的依赖、从属、逻辑规则等推理关系。
以保险和金融风险评估为例,一个完备的 AI 系统不仅需要基于个人的履历、行为习惯、健康程度等进行分析处理,还需要通过其亲友、同事、同学之间的来往数据和相互评价进一步进行信用评估和推断。基于图结构的学习系统能够利用用户之间、用户与产品之间的交互,做出非常准确的因果和关联推理。
——达摩院2020十大科技趋势白皮书
3. 可解释性强
图具有很强的语义可视化能力,这种优势被所有的 GNN 模型所共享。比如在异常交易账户识别的场景中,GNN 在将某个账户判断为异常账户之后,可以将该账户的局部子图可视化出来,如下图所示:

我们可以直观地从子图结构中发现一些异常模式,比如同一设备上有多个账户登录,或者同一账户在多个设备上有行为。还可以从特征的维度,比如该账户与其他有关联的账户行为模式非常相似(包括活跃时间集中,或者呈现周期性等),从而对模型的判断进行解释。
论文 “GNNExplainer: Generating Explanations for Graph Neural Networks” 提供了一种自动从子图中提取重要子图结构和节点特征的方法,可以为 GNN 的判断结果提供重要依据。
03 图神经网络的应用
图数据无处不在,图神经网络的应用场景自然非常多样。笔者在这里选择一部分应用场景为大家做简要的介绍,更多的还是期待我们共同发现和探索。

1. 计算机视觉
在计算机视觉的应用有根据提供的语义生成图像,如下图所示(引用)。输入是一张语义图,GNN通过对“man behind boy on patio”和“man right of man throwing firsbee”两个语义的理解,生成了输出的图像。

▲图片来源:https://arxiv.org/pdf/1804.01622.pdf
再说说视觉推理,人类对视觉信息的处理过程往往参杂着推理。比如下图的场景中,左上角第4个窗户虽然有部分遮挡,我们仍可以通过其他三扇窗户推断出它是窗户;再看右下角的校车,虽然车身不完整,但我们可以通过这个车身颜色推断出其是校车。

▲图片来源:https://arxiv.org/pdf/1803.11189.pdf
人类可以从空间或者语义的维度进行推理,而图可以很好的刻画空间和语义信息,让计算机可以学着像人类一样,利用这些信息进行推理。
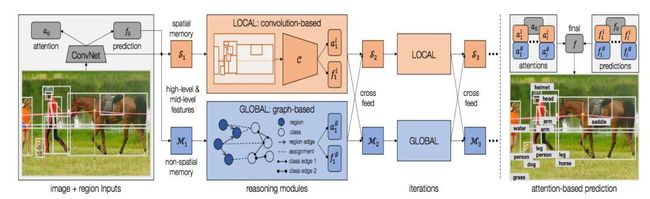
▲图片来源:https://arxiv.org/abs/1803.11189
当然还有动作识别,视觉问答等应用,这里我们就不一一列举了,感兴趣的同学推荐大家阅读文章:
图像生成
https://arxiv.org/pdf/1804.01622.pdf
视觉推理
https://arxiv.org/pdf/1803.11189.pdf
2. 自然语言处理
GNNs 在自然语言处理中的应用也很多,包括多跳阅读、实体识别、关系抽取以及文本分类等。多跳阅读是指给机器有很多语料,让机器进行多链条推理的开放式阅读理解,然后回答一个比较复杂的问题。在2019年,自然语言处理相关的顶会论文使用 GNN 作为推理模块已经是标配了。
多跳阅读:
https://arxiv.org/pdf/1905.06933.pdf
关系抽取和文本分类应用也十分多,这里推荐大家阅读:
https://mp.weixin.qq.com/s/i2pgW4_NLCB1Bs3qRWRYoA
3. 生物医疗
我们在高中都接触过生物化学,知道化合物是由原子和化学键构成的,它们天然就是一种图数据的形式,所以图神经网络在生物医疗领域应用特别广泛。包括新药物的发现、化合物筛选、蛋白质相互作用点检测、以及疾病预测。
据笔者所知,目前国外包括耶鲁、哈佛,国内像北大清华都有很多实验室研究图神经网络在医学方面的应用,而且我相信这会是图神经网络最有价值的应用方向之一。
除了上述的方向,还有像在自动驾驶和 VR 领域会使用的 3D 点云;与近两年同样很火的知识图谱相结合;智慧城市中的交通流量预测;芯片设计中的电路特性预测;甚至还可以利用图神经网络编写代码。
目前在真正在工业场景中付诸应用,并取得了显著成效的场景主要有两个,一是推荐,二是风控。
4. 工业应用之推荐
推荐是机器学习在互联网中的重要应用。互联网业务中,推荐的场景特别说,比如内容推荐、电商推荐、广告推荐等等。这里,我们介绍三种图神经网络赋能推荐的方法。
(1)可解释性推荐
可解释性推荐,就是不仅要预测推荐的商品,还要给出推荐的理由。推荐中有一个概念叫元路径。在电影推荐的场景里,如下图所示。我们用 U 表示用户,用 M 表示电影,那么 UUM 是一条元路径。它表示一位用户关注了另一位用户,那么我们可以将用户看过的电影,推荐给关注他的人。
当然,还有比如 UMUM 表示与你看过相同电影的人还在看什么电影这条路径;UMTM 表示与你看过同一类型电影的路径.....元路径有很多,不同元路径对于不同的业务语义。在这个场景中,图神经网络模型有两个任务,一个是推荐影片给用户,二是给出哪条元路径的权重更高。而这正式 GNN 可解释性的体现。
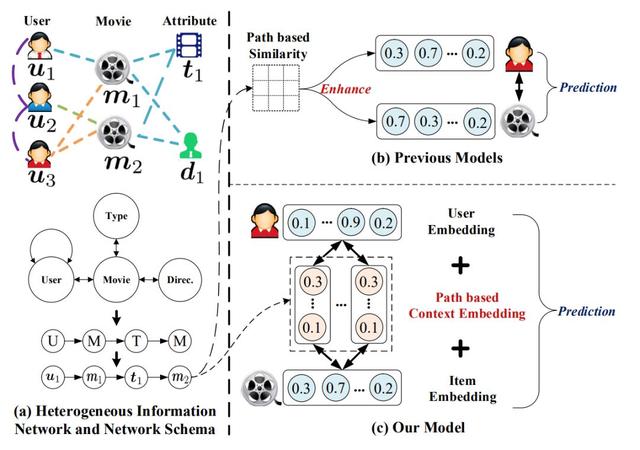
▲论文链接:http://www.shichuan.org/doc/47.pdf
(2)基于社交网络的推荐
利用用户之间的关注关系,我们也可以实现推荐。用户的购买行为首先会受到其在线社交圈中朋友的影响。如果用户 A 的朋友是体育迷,经常发布关于体育赛事、体育明星等信息,用户 A 很可能也会去了解相关体育主题的资讯。
其次,社交网络对用户兴趣的影响并非是固定或恒定的,而是根据用户处境(Context)动态变化的。举例来说,用户在听音乐时更会受到平时爱好音乐的朋友影响,在购买电子产品时更会受到电子发烧友的朋友影响。目前有许多的电商平台,包括像京东、蘑菇街、小红书等都在尝试做基于社交的推荐。
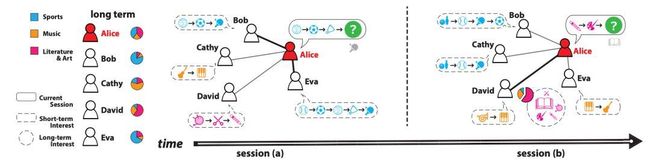
▲论文链接:http://www.cs.toronto.edu/~lcharlin/papers/fp4571-songA.pdf
(3)基于知识图谱的推荐
要推荐的商品、内容或者产品,依据既有的属性或者业务经验,可以得到他们之间很多的关联信息,这些关联信息即是我们通常说的知识图谱。知识图谱可以非常自然地融合进已有的用户-商品网络构成一张更大、且包含更加丰富信息的图。

▲论文链接:https://arxiv.org/pdf/1803.03467.pdf
其实不管是社交网络推荐,还是知识图谱,都是拿额外的信息补充到图网络中。既能有聚合关系网络中复杂的结构信息,又能囊括丰富的属性信息,这就是图神经网络强大的地方。
国外图片社交媒体 Pinterest 发表了利用图神经网络做推荐的模型 PinSage 。大家应该也都比较熟悉了,这里就不再赘述了。
图数据包罗万象,图神经网络的应用场景将会非常丰富。从 2020 年 AAAI 和 ICLR 的情况来看,图神经网络在学术界已经掀起了一阵新的潮流。当然,工业界也会迎来更多的投入和关注,毕竟图数据是最贴合业务的数据。
这里要向大家推荐一本关于图神经网络的书《深入浅出图神经网络》。这是我以及我的公司极验图数据团队结合自己在图神经网络领域的研究和实践经验撰写的一本入门书籍,从原理、算法、实现、应用 4 个维度为大家详细全面的讲解了图神经网络。希望能够对大家学习和利用图神经网络技术有所帮助。
3.1 图神经网络可以做哪些应用?
见这篇:https://zhuanlan.zhihu.com/p/115422316
图神经网络介绍完毕,下面正式开始这一次 百度图神经七日打卡的活动。
04 图网络的学习算法总结
-
图游走类算法:通过在图上的游走,获得多个节点序列,再利用 Skip Gram 模型训练得到节点表示(下节课内容)
-
图神经网络算法:端到端模型,利用消息传递机制实现。
-
知识图谱嵌入算法:专门用于知识图谱的相关算法。
05 简单易用的PGL 图学习库简介
-
Github 链接:https://github.com/PaddlePaddle/PGL
-
API文档: https://pgl.readthedocs.io/en/latest/
05 PGL 框架的安装
这里我就做一回知识的搬运工,以下是同道写的很全面的避坑文章:
https://blog.csdn.net/weixin_50874291/article/details/110122443
还有这位童鞋的:传送门
06 图游走类模型的介绍
https://blog.csdn.net/weixin_45325331/article/details/110124382
https://blog.csdn.net/zbp_12138/article/details/110217585?utm_source=app
基于百度paddlepaddle框架实现图结构及图的游走模型
1. DeepWalk采样算法
from pgl.graph import Graph
import numpy as np
class UserDefGraph(Graph):
def random_walk(self, nodes, walk_len):
"""
输入:nodes - 当前节点id list (batch_size,)
walk_len - 最大路径长度 int
输出:以当前节点为起点得到的路径 list (batch_size, walk_len)
用到的函数
1. self.successor(nodes)
描述:获取当前节点的下一个相邻节点id列表
输入:nodes - list (batch_size,)
输出:succ_nodes - list of list ((num_successors_i,) for i in range(batch_size))
2. self.outdegree(nodes)
描述:获取当前节点的出度
输入:nodes - list (batch_size,)
输出:out_degrees - list (batch_size,)
"""
walks = [[node] for node in nodes]
walks_ids = np.arange(0, len(nodes))
cur_nodes = np.array(nodes)
for l in range(walk_len):
"""选取有下一个节点的路径继续采样,否则结束"""
outdegree = self.outdegree(cur_nodes)
walk_mask = (outdegree != 0)
if not np.any(walk_mask):
break
cur_nodes = cur_nodes[walk_mask]
walks_ids = walks_ids[walk_mask]
outdegree = outdegree[walk_mask]
succ_nodes = self.successor(cur_nodes)
sample_index = np.floor(np.random.rand(outdegree.shape[0])*outdegree).astype("int64")
next_nodes = []
for s, ind, walk_id in zip(succ_nodes, sample_index, walks_ids):
walks[walk_id].append(s[ind])
next_nodes.append(s[ind])
cur_nodes = np.array(next_nodes)
return walks2. SkipGram模型训练
import paddle.fluid.layers as l
def userdef_loss(embed_src, weight_pos, weight_negs):
"""
输入:embed_src - 中心节点向量 list (batch_size, 1, embed_size)
weight_pos - 标签节点向量 list (batch_size, 1, embed_size)
weight_negs - 负样本节点向量 list (batch_size, neg_num, embed_size)
输出:loss - 正负样本的交叉熵 float
"""
pos_logits = l.matmul(
embed_src, weight_pos, transpose_y=True) # [batch_size, 1, 1]
neg_logits = l.matmul(
embed_src, weight_negs, transpose_y=True) # [batch_size, 1, neg_num]
ones_label = pos_logits * 0. + 1.
ones_label.stop_gradient = True
pos_loss = l.sigmoid_cross_entropy_with_logits(pos_logits, ones_label)
zeros_label = neg_logits * 0.
zeros_label.stop_gradient = True
neg_loss = l.sigmoid_cross_entropy_with_logits(neg_logits, zeros_label)
loss = (l.reduce_mean(pos_loss) + l.reduce_mean(neg_loss)) / 2
return loss3. Node2Vec采样算法
import numpy as np
def node2vec_sample(succ, prev_succ, prev_node, p, q):
"""
输入:succ - 当前节点的下一个相邻节点id列表 list (num_neighbors,)
prev_succ - 前一个节点的下一个相邻节点id列表 list (num_neighbors,)
prev_node - 前一个节点id int
p - 控制回到上一节点的概率 float
q - 控制偏向DFS还是BFS float
输出:下一个节点id int
"""
succ_len = len(succ)
prev_succ_len = len(prev_succ)
prev_succ_set = np.asarray([])
for i in range(prev_succ_len):
prev_succ_set = np.append(prev_succ_set,prev_succ[i])
# 概率参数信息
probs = []
prob = 0
prob_sum = 0.
for i in range(succ_len):
if succ[i] == prev_node:
prob = 1. / p
elif np.where(prev_succ_set==succ[i]):
prob = 1.
elif np.where(prev_succ_set!=succ[i]):
prob = 1. / q
else:
prob = 0.
probs.append(prob)
prob_sum += prob
RAND_MAX = 65535
rand_num = float(np.random.randint(0, RAND_MAX+1)) / RAND_MAX * prob_sum
sampled_succ = 0.
for i in range(succ_len):
rand_num -= probs[i]
if rand_num <= 0:
sampled_succ = succ[i]
return sampled_succ 总结
本文心得是我第三次参加百度的AI7日打卡营活动,关于图神经网络的算法,去年就见识了各种大佬的神奇用法,这一次活动,更是进一步加强了自己图神经网络GCN的理论基础,并且学习了在CNN中广泛使用的GCN算法。为后面的图学习科研之路打下更深的理论基础。本人研究方向是计算机视觉方向,通过这几天的打卡营活动,感悟颇多,图游走算法在NLP中已经取得了优秀的成果,相信在CV中也能够取得优异的表现。
同时,通过这次活动,在群里各位大佬的指正,让我对padllepaddle编程有了更进一步的提高,同时必须指出百度的paddlepaddle框架 编写算法及模型调参都非常方便。非常适合科研er进行学习使用,希望百度的paddlepaddle框架能够越来越优秀,和Pytorch及Tf框架平分天下,期待国产崛起。欢迎大家给百度paddlepaddle的PGL多多star哦!
地址在这:https://github.com/PaddlePaddle/PGL。
大家可以在百度AI Studio学习平台上学习更多的AI知识:https://aistudio.baidu.com/aistudio/index