本文参考了About Jason Brownlee的博文
英文链接:https://machinelearningmastery.com/machine-learning-in-python-step-by-step/
本文主要是上文的一些翻译,附加了自己实际中的总结和心得
这个项目从一个小的实例开始,经典的鸢尾花的分类。编写实例对新手学习一门工具来说是一个好的开始,如同编程中的hello world。
大纲:
- 安装Python和SciPy平台
- 导入数据集
- 总结数据集
- 可视化数据集
- 评估算法
- 做出一些预测
1 下载安装和开始使用Python SciPy
安装过程可以参考本上的上一篇博文,基本上这个流程过了一遍之后下面的步骤都没什么问题了。
安装与配置环境:https://www.jianshu.com/p/b9f3b5440dfe
1.1 安装SciPy库
Python的版本号是2.7或者3.5,本人的是3.5
有五个库需要预先安装好:
- scipy
- numpy
- matplotlib
- pandas
- sklearn
如果是windows下的话,强烈推荐安装Anaconda,正如本节开头所写,参考上一篇博文。
有一点注意的是,本人安装Anaconda的时候,scikit-learn版本为0.17,现在已经不够新了,这个教程推荐的scikit-learn版本至少为0.18以上,所以这里做了一个更新。
更新scikit-learn库只需要在cmd中输入 :
pip install –U scikit-learn
完成后如图:

完成了自动更新。
1.2 运行Python 和检查版本
下面检查Python和上文的库是否已经安装成功了
打开一个cmd命令框,输入:
python
然后复制如下代码:
# import sys
# print('Python:{}'.format(sys.version))
import scipy
print('scipy: {}'.format(scipy.__version__))
import numpy
print('numpy: {}'.format(numpy.__version__))
import matplotlib
print('matplotlib:{}'.format(matplotlib.__version__))
import pandas
print('pandas: {}'.format(pandas.__version__))
import sklearn
print('sklearn: {}'.format(sklearn.__version__))
测试输出的结果,本人的运行结果显示如下:
Python:3.5.2 |Anaconda 4.2.0 (64-bit)| (default, Jul 5 2016, 11:41:13) [MSC v.1900 64 bit (AMD64)]
scipy: 0.18.1
numpy: 1.13.0
matplotlib: 1.5.3
pandas: 0.18.1
sklearn: 0.19.1
理想情况下,应该是跟上面差不多或者更新一些,如果差一点也没关系。但是如果报错的话,立刻停下来,检查原因,处理好错误再继续。如果这段运行不通过,后续代码也无法进行。
2 导入数据
我们使用鸢尾花(iris)数据集。这是个很有名的数据集,被称为机器学习界的hello world。
这个数据集的详情:learn more about this dataset on Wikipedia.
2.1 导入库
# Load libraries
import pandas
from pandas.tools.plotting import scatter_matrix #导入散点图矩阵包
import matplotlib.pyplot as plt
from sklearn import model_selection
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
这些导入过程不应该有错误,如果有,停下来检查,看看上面的搭建环境的内容,排除错误然后继续。
2.2 导入数据集
# Load dataset
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class']
dataset = pandas.read_csv(url, names=names)
也可以先下载数据文件,然后修改url中的路径去加载它。
3 统计数据集
然后看看数据,在这一步注意了解以下几点:
- 数据的维度
- 数据本身
- 统计所有的数据集属性
- 根据不同类别进行数据细分
3.1数据的维度
#shape
Print(dataset.shape)
将得到150个实例和5个属性(变量)
3.2 了解数据本身
# head
print(dataset.head(20))
将看到前20行的数据
sepal-length sepal-width petal-length petal-width class
0 5.1 3.5 1.4 0.2 Iris-setosa
1 4.9 3.0 1.4 0.2 Iris-setosa
2 4.7 3.2 1.3 0.2 Iris-setosa
3 4.6 3.1 1.5 0.2 Iris-setosa
4 5.0 3.6 1.4 0.2 Iris-setosa
5 5.4 3.9 1.7 0.4 Iris-setosa
6 4.6 3.4 1.4 0.3 Iris-setosa
7 5.0 3.4 1.5 0.2 Iris-setosa
8 4.4 2.9 1.4 0.2 Iris-setosa
9 4.9 3.1 1.5 0.1 Iris-setosa
10 5.4 3.7 1.5 0.2 Iris-setosa
11 4.8 3.4 1.6 0.2 Iris-setosa
12 4.8 3.0 1.4 0.1 Iris-setosa
13 4.3 3.0 1.1 0.1 Iris-setosa
14 5.8 4.0 1.2 0.2 Iris-setosa
15 5.7 4.4 1.5 0.4 Iris-setosa
16 5.4 3.9 1.3 0.4 Iris-setosa
17 5.1 3.5 1.4 0.3 Iris-setosa
18 5.7 3.8 1.7 0.3 Iris-setosa
19 5.1 3.8 1.5 0.3 Iris-setosa
3. 3. 统计所有的数据集属性
接下来看看数据的属性,包括样本值,均值,最小值,最大值,以及百分比值。可以看到所有的数值都有着相似的区间(0~8公分)
sepal-length sepal-width petal-length petal-width
count 150.000000 150.000000 150.000000 150.000000
mean 5.843333 3.054000 3.758667 1.198667
std 0.828066 0.433594 1.764420 0.763161
min 4.300000 2.000000 1.000000 0.100000
25% 5.100000 2.800000 1.600000 0.300000
50% 5.800000 3.000000 4.350000 1.300000
75% 6.400000 3.300000 5.100000 1.800000
max 7.900000 4.400000 6.900000 2.500000
3.4根据不同类别进行数据细分
按“class”统计行数,
# class distribution
print(dataset.groupby('class').size())
我们可以看到每种花的样本数都是50
class
Iris-setosa 50
Iris-versicolor 50
Iris-virginica 50
dtype: int64
4 数据可视化
主要是两种图:
单变量图用来更好的理解每个属性
多变量图用来更好的理解属性间的关系
4.1 单变量图
单变量图,顾名思义,就是指每个图对应单个变量,绘制箱线图(box and whisker plots)
# box and whisker plots
dataset.plot(kind='box', subplots=True, layout=(2,2), sharex=False, sharey=False)
plt.show()
得到了一个直观的属性分布图

还可以创建一个直方图,便于对各属性有个整体的认识
# histograms
dataset.hist()
plt.show()

看来似乎有两个输入变量呈高斯分布,这有助于以后我们用算法验证它。
4.2 多变量图
然后我们看看变量之间的关系
首先我们看素有属性对之间的散点图,这有助于发现输入变量之间的结构化关系。
# scatter plot matrix
scatter_matrix(dataset)
plt.show()
值得注意的是,许多属性之间的两两关系呈现出的对角线分布趋势,这提示着一种高相关性和可预测性的关系。

5 算法评估举例
接下来创建一些模型,并评估各算法的精度,包括以下几步:
- 对验证数据集进行分离
- 使用10折交叉验证( cross validation)建立测试框架( test harness)
- 根据花的测量属性建立5个不同的模型预测其的种类
- 选择最好的模型
5.1 创建验证数据集
使用统计学方法评估模型的精度。同时我们希望对其中的最优模型得到一个更精确的估计。
我们将把加载的数据集分为两部分。80%用来训练模型,20%留作验证数据集。
# Split-out validation dataset
array = dataset.values
X = array[:,0:4]
Y = array[:,4]
validation_size = 0.20
seed = 7
X_train, X_validation, Y_train, Y_validation = model_selection.train_test_split(X, Y, test_size=validation_size, random_state=seed)
然后就获得了训练数据X_train,Y_train
5.2 测试框架
将使用10折交叉验证( cross validation)评估精度,就是说把数据集分成10份,轮流将其中9份作为训练数据,1份作为测试数据,进行试验。每次试验都会得到相应的正确率。10次的结果的正确率的平均值作为对算法精度的估计。
# Test options and evaluation metric
seed = 7
scoring = 'accuracy'
这里使用'accuracy'作为评估模型的度量值。它是正确预测结果和全部用例数量的比值,乘以100%的结果(例如95%),接下来使用scoring变量评估每个模型。
5.3 建立模型
我们并不知道哪种模型在某个问题上是最好的也不知道该用什么样的配置,但根据图形可以看出某些分类在某些维度上是部份线性分离的,这可以帮助我们产生好的测试结果。
接下来我们评价6种不同的算法
- 逻辑回归(LR, Logistic regression)
- 线性判别分析(LDA, Linear Discriminant Analysis)
- K-近邻算法(KNN, K-Nearest Neighbors)
- 分类与回归树(CART, Classific and Regression Tree)
- 高斯朴素贝叶斯(NB, Gaussian Naive Bayes)
- 支持向量机(SVM, Support Vector Machines)
其中有简单线性算法(LR和LDA),非线性算法(KNN, CART, NB 和SVM)。我们在每次运行前重置随机数种子来确保对算法的评估是基于完全相同的数据分支的。这确保了结果可以直接进行比较。
接下来构建和评估五个模型:
# Spot Check Algorithms
models = []
models.append(('LR', LogisticRegression()))
models.append(('LDA', LinearDiscriminantAnalysis()))
models.append(('KNN', KNeighborsClassifier()))
models.append(('CART', DecisionTreeClassifier()))
models.append(('NB', GaussianNB()))
models.append(('SVM', SVC()))
# evaluate each model in turn
results = []
names = []
for name, model in models:
kfold = model_selection.KFold(n_splits=10, random_state=seed)
cv_results = model_selection.cross_val_score(model, X_train, Y_train, cv=kfold, scoring=scoring)
results.append(cv_results)
names.append(name)
msg = "%s: %f (%f)" % (name, cv_results.mean(), cv_results.std())
print(msg)
5.4 选择最好的模型
这样就得到了6个模型和他们的精确度估计,运行上面的代码得到如下的结果:
LR: 0.966667 (0.040825)
LDA: 0.975000 (0.038188)
KNN: 0.983333 (0.033333)
CART: 0.966667 (0.040825)
NB: 0.975000 (0.053359)
SVM: 0.991667 (0.025000)
看起来KNN得到了最大的精度估计。
我们也可以创建一张图表来反映模型评估的结果,每种算法都被评估了10次(10折交叉验证)
# Compare Algorithms
fig = plt.figure()
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
plt.boxplot(results)
ax.set_xticklabels(names)
plt.show()
然后得到了箱线图:
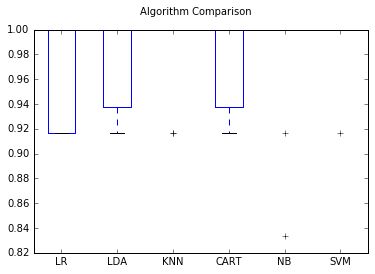
可以看到很多算法的精度都比较高。
6 做出预测
根据测试,KNN算法是精度最高的,然后我们想得到在验证集上的准确性。
这将是我们对最优模型独立性的一个最终确认。这样做是有意义的,以防止训练中出现的失误,例如数据的过拟合或者数据泄露。这都会导致一个过于乐观的结果。
我们可以验证数据集上直接运行KNN模型,总结结果作为最终分数,混淆矩阵(confusion matrix)和分类报告。
# Make predictions on validation dataset
knn = KNeighborsClassifier()
knn.fit(X_train, Y_train)
predictions = knn.predict(X_validation)
print(accuracy_score(Y_validation, predictions))
print(confusion_matrix(Y_validation, predictions))
print(classification_report(Y_validation, predictions))
可以看到精确度是0.9或者说是90%,混淆矩阵提示了三类错误。最后分类报告提供了每一类的准确率,召回率,F1值,并显示了优异的结果
0.9
[[ 7 0 0]
[ 0 11 1]
[ 0 2 9]]
precision recall f1-score support
Iris-setosa 1.00 1.00 1.00 7
Iris-versicolor 0.85 0.92 0.88 12
Iris-virginica 0.90 0.82 0.86 11
avg / total 0.90 0.90 0.90 30
这里补充一下:
precision 体现了模型对负样本的区分能力,precision越高,说明模型对负样本的区分能力越强。recall 体现了分类模型H对正样本的识别能力,recall 越高,说明模型对正样本的识别能力越强。F1-score 是两者的综合。F1-score 越高,说明分类模型越稳健。
classification_repor的最后一行是用support 加权平均算出来的,如:
0.90 =( 1.007 + 0.8512 + 0.9*11) / 30
总结
这一节我们一步步的学习了如何使用Python完成一个简单的机器学习工程。
从加载数据开始到预测结果的一个小的工程,是熟悉一个新平台的最佳途径。
本人初学,如有不足之处,好望高手们指教。