【动手学PaddlePaddle2.0系列】模型训练的N种姿势
【动手学Paddle2.0系列】模型训练的N种姿势
最开始接触深度学习的时候,我的码力几乎等于0,所以在最初的时候,几乎都是使用封装好的高层API进行训练,自由度很低。
想通过这个教程,对paddle2.0中的各种开启训练的方式进行一个总结。让我们开始愉快的学(ban)习(zhuan)吧!
1 Paddle2.0 主要思想
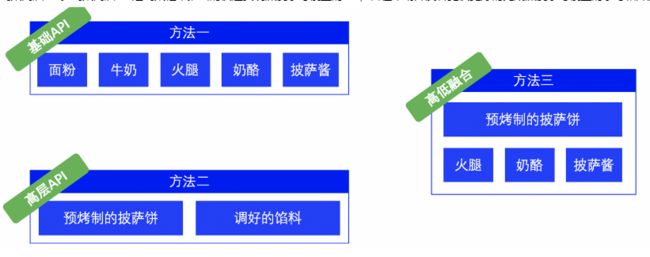
那么,用框架来类比,飞桨框架基础API对应方法一,飞桨框架高层API对应方法二。使用基础API,我们可以随心所欲的搭建自己的深度学习模型,不会受到任何限制;而使用方法二,我们可以很快的实现模型,达到自己想要的效果,缺点是少了一些自主性。但是,与制作披萨不同的是,飞桨框架可以做到真正的”鱼与熊掌”可以兼得,我们在飞桨框架中实现了API的高低融合,使我们的开发者既可以享受到基础API的强大,又可以兼顾高层API的快捷。
1.1 数据加载
from paddle.vision.transforms import Compose, Normalize
from paddle.vision.datasets import MNIST
# 数据预处理,这里用到了随机调整亮度、对比度和饱和度
transform = Compose([Normalize(mean=[127.5],
std=[127.5],
data_format='CHW')])
# 数据加载,在训练集上应用数据预处理的操作
train_dataset = MNIST(mode='train', transform=transform)
test_dataset = MNIST(mode='test')
Cache file /home/aistudio/.cache/paddle/dataset/mnist/train-images-idx3-ubyte.gz not found, downloading https://dataset.bj.bcebos.com/mnist/train-images-idx3-ubyte.gz
Begin to download
Download finished
Cache file /home/aistudio/.cache/paddle/dataset/mnist/train-labels-idx1-ubyte.gz not found, downloading https://dataset.bj.bcebos.com/mnist/train-labels-idx1-ubyte.gz
Begin to download
........
Download finished
Cache file /home/aistudio/.cache/paddle/dataset/mnist/t10k-images-idx3-ubyte.gz not found, downloading https://dataset.bj.bcebos.com/mnist/t10k-images-idx3-ubyte.gz
Begin to download
Download finished
Cache file /home/aistudio/.cache/paddle/dataset/mnist/t10k-labels-idx1-ubyte.gz not found, downloading https://dataset.bj.bcebos.com/mnist/t10k-labels-idx1-ubyte.gz
Begin to download
..
Download finished
1.2 加载模型
import paddle
from paddle.vision.models import LeNet
import paddle.nn as nn
mnist = LeNet()
# 模型封装,用Model类封装
model = paddle.Model(mnist)
# 模型配置:为模型训练做准备,设置优化器,损失函数和精度计算方式
model.prepare(optimizer=paddle.optimizer.Adam(parameters=model.parameters()),
loss=nn.CrossEntropyLoss(),
metrics=paddle.metric.Accuracy())
2 模型训练的N种姿势
2.1 高层API训练
2.1.1 方式一
# 模型训练,
model.fit(train_dataset,
epochs=5,
batch_size=64,
verbose=1)
# 模型评估,
model.evaluate(test_dataset, verbose=1)
Epoch 1/5
step 30/938 [..............................] - loss: 0.5914 - acc: 0.6250 - ETA: 11s - 12ms/st
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:77: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
return (isinstance(seq, collections.Sequence) and
step 70/938 [=>............................] - loss: 0.4902 - acc: 0.7636 - ETA: 6s - 8ms/stepstep 938/938 [==============================] - loss: 0.0476 - acc: 0.9470 - 5ms/step
Epoch 2/5
step 938/938 [==============================] - loss: 0.0125 - acc: 0.9803 - 5ms/step
Epoch 3/5
step 938/938 [==============================] - loss: 0.0026 - acc: 0.9844 - 5ms/step
Epoch 4/5
step 938/938 [==============================] - loss: 0.0061 - acc: 0.9869 - 5ms/step
Epoch 5/5
step 938/938 [==============================] - loss: 0.0837 - acc: 0.9885 - 5ms/step
Eval begin...
step 10000/10000 [==============================] - loss: 0.0000e+00 - acc: 0.9684 - 2ms/step
Eval samples: 10000
{'loss': [0.0], 'acc': 0.9684}
2.1.2 方式二
# 构建训练集数据加载器
train_loader = paddle.io.DataLoader(train_dataset, batch_size=64, shuffle=True)
# 构建测试集数据加载器
test_loader = paddle.io.DataLoader(test_dataset, batch_size=64, shuffle=True)
model.fit(train_loader,
eval_data = test_loader,
epochs=5,
verbose=1,
)
Epoch 1/5
step 938/938 [==============================] - loss: 0.0493 - acc: 0.9898 - 5ms/step
Eval begin...
step 157/157 [==============================] - loss: 0.0000e+00 - acc: 0.9672 - 3ms/step
Eval samples: 10000
Epoch 2/5
step 938/938 [==============================] - loss: 0.0285 - acc: 0.9911 - 5ms/step
Eval begin...
step 157/157 [==============================] - loss: 0.0000e+00 - acc: 0.9388 - 3ms/step
Eval samples: 10000
Epoch 3/5
step 938/938 [==============================] - loss: 0.0627 - acc: 0.9913 - 6ms/step
Eval begin...
step 157/157 [==============================] - loss: 4.0000 - acc: 0.9466 - 3ms/step
Eval samples: 10000
Epoch 4/5
step 938/938 [==============================] - loss: 0.0184 - acc: 0.9922 - 5ms/step
Eval begin...
step 157/157 [==============================] - loss: 0.0000e+00 - acc: 0.9529 - 3ms/step
Eval samples: 10000
Epoch 5/5
step 938/938 [==============================] - loss: 0.0035 - acc: 0.9927 - 5ms/step
Eval begin...
step 157/157 [==============================] - loss: 3.8146 - acc: 0.9229 - 3ms/step
Eval samples: 10000
model.evaluate(test_dataset, verbose=1)
Eval begin...
step 10000/10000 [==============================] - loss: 0.0000e+00 - acc: 0.9229 - 2ms/step
Eval samples: 10000
{'loss': [0.0], 'acc': 0.9229}
2.1.3 方式三
for epoch in range(5):
for batch_id, data in enumerate(train_loader()):
x_data = data[0]
y_data = data[1]
info = model.train_batch([x_data], [y_data])
if batch_id % 1 == 0:
print(info)
for ebatch_id, edata in enumerate(test_loader()):
x_data_v = edata[0]
y_data_v = edata[1]
info = model.eval_batch([x_data_v], [y_data_v])
if ebatch_id % 1 == 0:
print(info)
model.evaluate(test_dataset, verbose=1)
Eval begin...
step 10000/10000 [==============================] - loss: 0.0000e+00 - acc: 0.9880 - 2ms/step
Eval samples: 10000
{'loss': [0.0], 'acc': 0.9880055555555556}
2.1.4 方式四
import paddle.nn.functional as F
mnist.train()
epochs = 5
optim = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
# 用Adam作为优化函数
for epoch in range(epochs):
for batch_id, data in enumerate(train_loader()):
x_data = data[0]
y_data = data[1]
predicts = mnist(x_data)
loss = F.cross_entropy(predicts, y_data)
# 计算损失
acc = paddle.metric.accuracy(predicts, y_data, k=2)
loss.backward()
if batch_id % 1 == 0:
print("epoch: {}, batch_id: {}, loss is: {}, acc is: {}".format(epoch, batch_id, loss.numpy(), acc.numpy()))
optim.step()
optim.clear_grad()
for batch_id, data in enumerate(test_loader()):
x_data = data[0]
y_data = data[1]
predicts = mnist(x_data)
loss = F.cross_entropy(predicts, y_data)
# 计算损失
acc = paddle.metric.accuracy(predicts, y_data, k=2)
if batch_id % 1 == 0:
acc = paddle.metric.accuracy(predicts, y_data, k=2)
if batch_id % 1 == 0:
print("epoch: {}, batch_id: {}, loss is: {}, acc is: {}".format(epoch, batch_id, loss.numpy(), acc.numpy()))
总结
在上面的四种训练方式中,实际上每种方式都有其优缺点,完全使用高层API能够方便的开启训练。对于完全的新手用户,推荐使用方式一、方式二。对于已经熟悉Paddle2.0的用户推荐使用方式四。方式四可以更加灵活,并且能够灵活地加入混合精度训练,训练方式更加自由。
一点小小的宣传&下期预告
我会在下一个项目中介绍在Paddle2.0中使用混合精度训练,欢迎大家关注哦。
我目前在上海,感兴趣的领域包括模型压缩、小目标检测、嵌入式,欢迎交流关注。来AI Studio互粉吧等你哦