接着上一篇文章的问题:在实际的系统开发和后期的数据维护工作中,经常会遇到这样的需求---将一个表的增量数据插入到该数据表中。
上一篇《利用 LEFT JOIN 实现增量数据的 INSERT INTO 插入》中,没有对插入的数据进行主键是否重复判断,所以,仅仅实现增量数据的导入是没有问题的。然而,实际情况中,我们会遇到在插入新增数据的同时,对已经存在的数据做UPDATE操作。
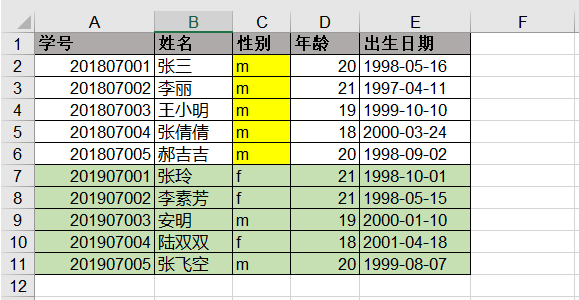
就比如,student表中的数据,往年的学生信息可能做了些更正(如下图,2018年的学生全部更正为男性),那么我们不光要导入新增的数据(2019年级学生信息),而且要在inset into的同时,对更正的2018年纪学生信息做update。
如果是在程序业务层中,在insert into操作前我们可以先查询是否存在这个记录,如果存在就做update,如果不存在就做insert into操作。
本案例中,是需要在数据库操作中进行如此操作。MySQL数据提供了INSERT ... ON DUPLICATE KEY UPDATE 语法来实现这种操作。
先来看看官网(https://dev.mysql.com/doc/refman/5.7/en/insert-on-duplicate.html)的介绍:
If you specify an ON DUPLICATE KEY UPDATE clause and a row to be inserted would cause a duplicate value in a UNIQUE index or PRIMARY KEY, an UPDATE of the old row occurs. For example, if column a is declared as UNIQUE and contains the value 1, the following two statements have similar effect:
##写法一
INSERT INTO t1 (a,b,c) VALUES (1,2,3) ON DUPLICATE KEY UPDATE c=c+1;
##写法二
UPDATE t1 SET c=c+1 WHERE a=1;
就是说如果你指定了ON DUPLICATE KEY UPDATE子句,并且要插入的行会在惟一索引或主键中导致重复值,则会发生旧行的更新。而且上面两种写法的结果是一样的。
而且,ON DUPLICATE KEY UPDATE子句还能够对多条记录同时操作,用逗号将要操作的记录隔开。
INSERT INTO t1 (a,b,c) VALUES (1,2,3),(4,5,6)
ON DUPLICATE KEY UPDATE c=VALUES(a)+VALUES(b);
下面的写法实现的效果一样:
INSERT INTO t1 (a,b,c) VALUES (1,2,3)
ON DUPLICATE KEY UPDATE c=3;
INSERT INTO t1 (a,b,c) VALUES (4,5,6)
ON DUPLICATE KEY UPDATE c=9;
对于INSERT ... SELECT句法,MySQL也有声明具体的使用规则:
1.对单个表(可能是派生表)上查询的列的引用。
2.对多个表联合查询中的列的引用。
3.对去重查询的列的引用。
4.对其他表中列的引用,只要SELECT不使用GROUP BY。一个副作用是必须限定对非惟一列名的引用。
那我们可以修改语句,生成我们需要的执行语句:
INSERT INTO student
SELECT * FROM student_tmp
ON DUPLICATE KEY UPDATE student.sex = student_tmp.sex;
执行ok
[SQL]INSERT INTO student
SELECT * FROM student_tmp
ON DUPLICATE KEY UPDATE student.sex = student_tmp.sex
受影响的行: 9
时间: 0.154s
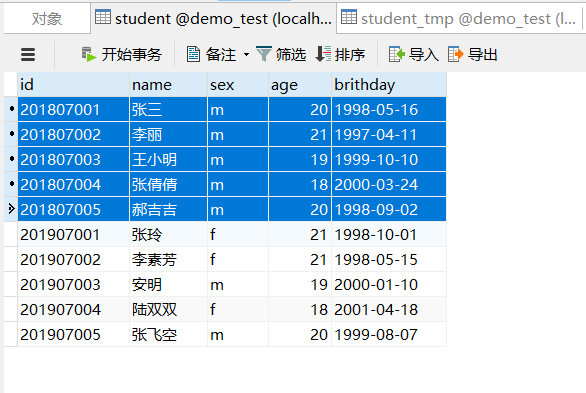
查看执行后语句后的student表结果,2018年级的学生信息已经全部更新为'm',2019年级的学生信息也成功插入,这正是我们想要的结果。
上一篇《利用 LEFT JOIN 实现增量数据的 INSERT INTO 插入》
编者按:本文由弄青春原创,如果您喜欢,劳驾您点个赞,也欢迎您留下宝贵的评论!若要转载,请注明出处!